,
25 tweets,
6 min read
Read on Twitter
Thank you, @NathanKalmoe, for once more engaging with our work. I feel privileged to have the opportunity to discuss how both of our works differ/intersect. As you invited and welcomed my retorque, here are some additional thoughts.
(1/gazillion)
(1/gazillion)
I say additional because there was a thread of this article's findings:
And a first pass on a few topics here with @ChrisPolPsych @ntdPhD
And a first pass on a few topics here with @ChrisPolPsych @ntdPhD
In this iteration, you focused on samples, distributions, sophistication measures and interpretation. While the latter is always somewhat subjective, I see the remaining points as issues which are worth debating, and whose intricacies may be elucidating to the differences found:
1. Generalizations are only possible if sample reflects the range of sophistication of the public.
-
I disagree with this point on a few grounds. Epistemologically, it can be daunting –if not practically impossible– to assess the population’s sophistication range/levels because
-
I disagree with this point on a few grounds. Epistemologically, it can be daunting –if not practically impossible– to assess the population’s sophistication range/levels because
these are intrinsically related to theory, definitions, and its measurement. Theoretically, the population, and its subgroups may have a level/range of political sophistication, but scholars’ ability to gauge it depends on many factors, so *ensuring samples to reflect the
range of sophistication in the public* may be intractable. Statistically, as I am sure you know, even if one could control for sophistication levels in the sampling process, conditioning on moderators/mediators (may I dare to say confounders) can lead to unintended outcomes.
And ultimately, while random sampling is the gold standard, it has little to with guaranteeing representativeness or proportionality of sophistication or any other latent construct. So benchmarking levels for pop may be fruitless (although I believe in benchmarking ES for meta).
In sum, I disagree not with the stated goal, or in theory, but with its use to justify ad-hoc assessments of data quality and that “All 4 samples are probably > info than public”. See below for details:
2. YouGov samples are better than the Nat-Rep SSI.
-
Traditionally, sampling procedure takes precedence on judging sample quality. And since none are true random samples, I would deem their a priori quality equivalent, and this point moot. But if the criterion is
-
Traditionally, sampling procedure takes precedence on judging sample quality. And since none are true random samples, I would deem their a priori quality equivalent, and this point moot. But if the criterion is
representativeness of opt-in online surveys, then typical quality criteria would be adhesion to the intended proportions of population targets (e.g., ACS, CPS, Census, etc.) and its year. However, I caution that, representativeness isn’t the only, and under some conditions,
the most impactful criterion on response quality. Often neglected aspects are quality controls (time & attention checks, bogus items), question format & labeling, & survey design. In sum, while ranking is certainly warranted when comparing between ANES/GSS/TESS data with
SSI/YouGov/Cint/Lucid with MTurk/students samples, the within comparisons are less straightforward, as discussed here
3. The other SSI study is mostly old dudes, so not particularly great.
-
Different samples have different purposes. Sample 2 is a confirmatory independent sample from the same panel to ensure findings are not dependable upon sampling method (matching on demographics).
-
Different samples have different purposes. Sample 2 is a confirmatory independent sample from the same panel to ensure findings are not dependable upon sampling method (matching on demographics).
So my approach has been to explore on the NR Sample 1, and when confirmed in the confirmatory sample (Sample 2), I always try to look for two or more independent datasets to validate new findings.
See here for another example (& two more in press):
See here for another example (& two more in press):
This is to avoid false positives, and incurring into questionable research practices. So the goal of Sample 1 is replicability rather than representativeness, which is especially important since these data contain social psychological constructs.
As for its demographic distribution, when not controlling for demographics, can yield, by chance, disproportionate representation, which panel composition is only a factor among many such as availability, n. of running projects, survey length, etc.
4. The strength of the relationship between social and economic ideologies (via both symbolic and operational) is contingent upon (alleged) sample quality.
-
While this is certainly plausible between the categories of data quality above (ANES vs. professional survey companies vs.
-
While this is certainly plausible between the categories of data quality above (ANES vs. professional survey companies vs.
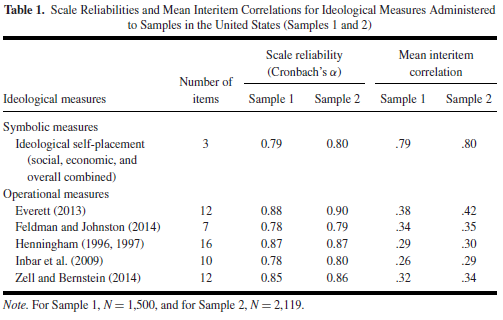
MTurk/students), when it comes to within comparisons, I believe measures are more important than they are given credit for. Ultimately, Kalmoe’s research use different measures for ideology and sophistication.
Think of IID, where we use a 9-point scale whose endpoints are labeled with "strongly" – rather than "extremely" as in ANES – liberal/conservative. This one change seems to yield more variance in IIDs and a less peaked distribution at the middle category."
In any case, I would contend that the agreement we found between the rich variety of used measures across independent datasets are a major plus to our study and its findings.
In sum, the increase in magnitude of correlations argued by @NathanKalmoe as a function of an ad-hoc assessment of data quality may be spurious.
5. Potpourri.
This got way to long (& sorry for my displaced enthusiasm, I should be aware this is a twitter thread). I blame @NathanKalmoe on the many points raised which needed addressing.
So here’s some rapid fire:
This got way to long (& sorry for my displaced enthusiasm, I should be aware this is a twitter thread). I blame @NathanKalmoe on the many points raised which needed addressing.
So here’s some rapid fire:
5.a. We conducted analyses based on median split, range split and its continuous score.
5.b. We found the % of explained variance varies as a function of the ideological measure.
5.c. The found correlations have little – if at all – with outliers.
5.b. We found the % of explained variance varies as a function of the ideological measure.
5.c. The found correlations have little – if at all – with outliers.
5.d. In agreement with the literature, and argued in the first exchanged thread, we indeed found sophistication is an important moderator in the relationship between social and economic conservatism.
For all these, see online appendix here: osf.io/j5wv4/
For all these, see online appendix here: osf.io/j5wv4/
*******retort
(aaaargh, as if I didn't re-read a few times).
(aaaargh, as if I didn't re-read a few times).