Mi próximo reto🧠 es procesar +10.000 horas de telediarios y publicar un buscador para encontrar entre todo lo dicho:
👉 ¿Qué se dijo de pactos de investidura?
👉 ¿Y de Revilla? ¿Y de Puigdemont?
Iré narrando aquí el proceso. Sígueme si quieres ver cómo lo hago 👍. 1 RT = ❤️
👉 ¿Qué se dijo de pactos de investidura?
👉 ¿Y de Revilla? ¿Y de Puigdemont?
Iré narrando aquí el proceso. Sígueme si quieres ver cómo lo hago 👍. 1 RT = ❤️


Publicaré mi proceso, el resultado y el código fuente. Necesitaré voluntarios excepcionales: un buen diseñador de producto y otros especialistas que quieran participar.
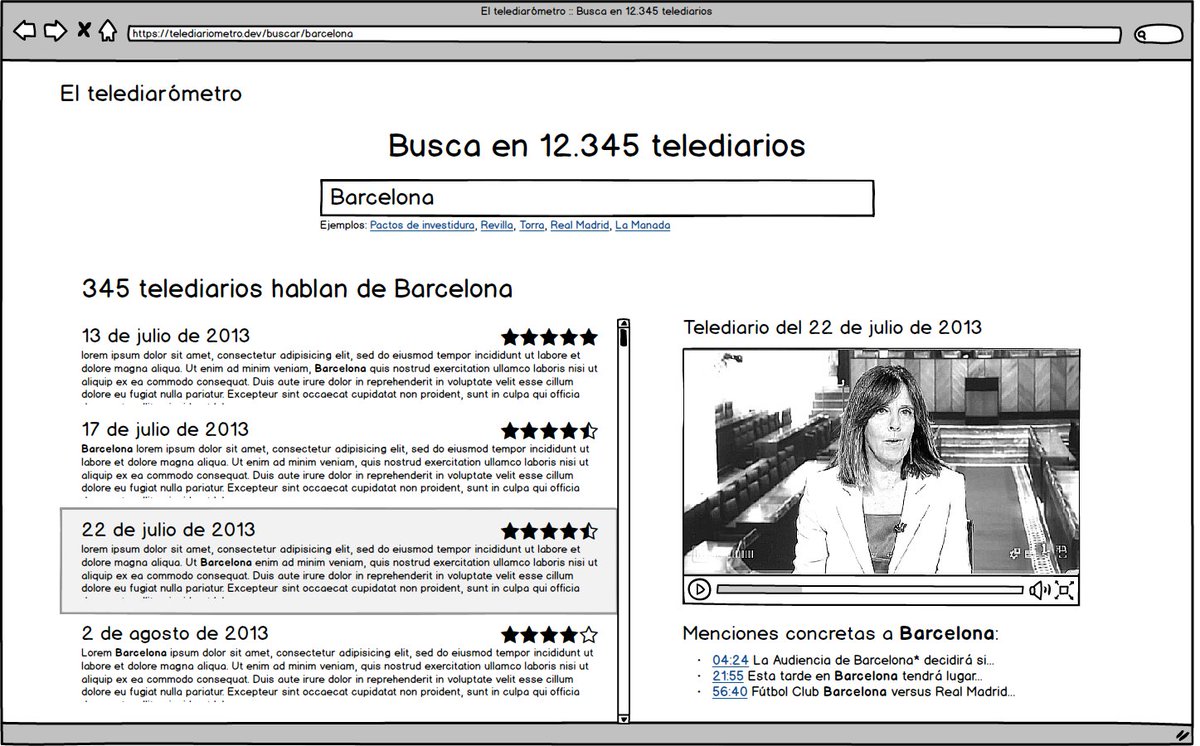
De momento este es el esquema de baja fidelidad de lo que quiero hacer.
¿Empezamos? Empezamos 🚀
De momento este es el esquema de baja fidelidad de lo que quiero hacer.
¿Empezamos? Empezamos 🚀
Veo dos estrategias viables.
La más directa es descargar en masa los subtítulos (ficheros en formato VTT), pues muchos telediarios tienen subtítulos para personas sordas.
La opción alternativa es hacer "speech-to-text" sobre el audio de los telediarios. Esto será el plan b.
La más directa es descargar en masa los subtítulos (ficheros en formato VTT), pues muchos telediarios tienen subtítulos para personas sordas.
La opción alternativa es hacer "speech-to-text" sobre el audio de los telediarios. Esto será el plan b.

Mi punto de partida son los telediarios de RTVE:
rtve.es/alacarta/video…
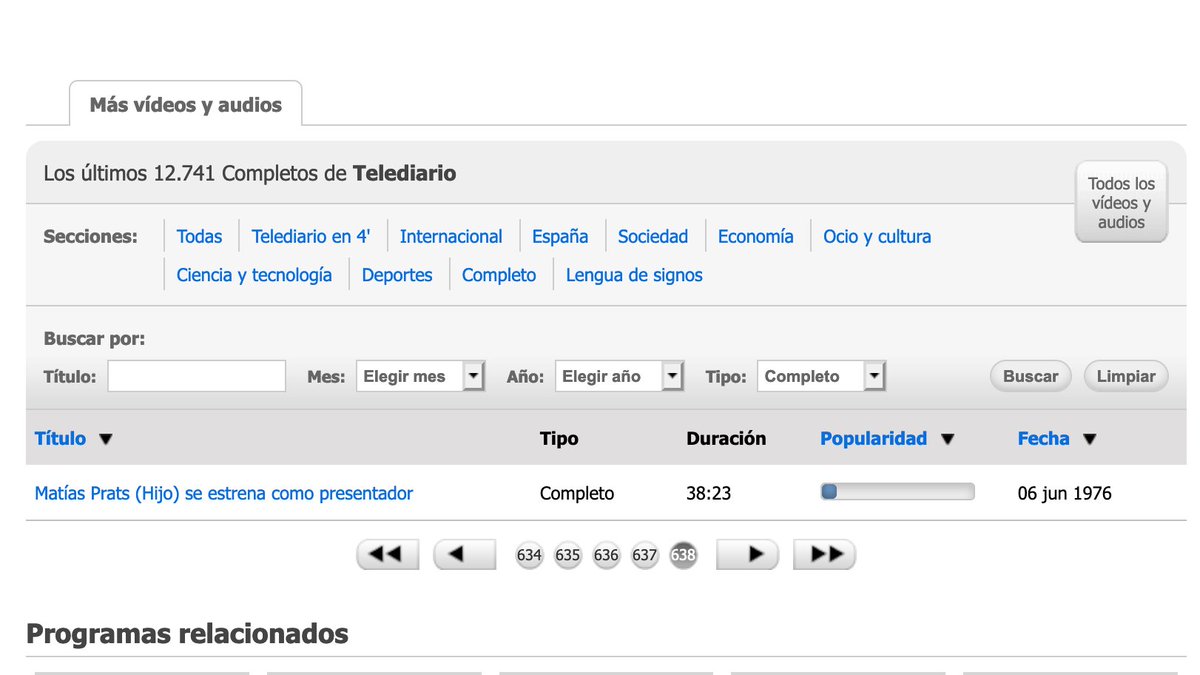
El buscador me ofrece 114.912 distintos, pero hay mucha morralla: fragmentos, avances... Utilizo el filtro "Tipo" para quedarme solo con los telediarios completos. Salen 12.271: 638 páginas. Las quiero 😎
rtve.es/alacarta/video…
El buscador me ofrece 114.912 distintos, pero hay mucha morralla: fragmentos, avances... Utilizo el filtro "Tipo" para quedarme solo con los telediarios completos. Salen 12.271: 638 páginas. Las quiero 😎
He escrito un script en Bash que descarga el índice con los telediarios completos. Podéis verlo aquí: gist.github.com/JaimeObregon/b…
Si todo va bien, con eso tendré materia prima para empezar a cacharrear de verdad. De momento ha bajado 253 páginas de 638. Voy a dar un paseo.
Si todo va bien, con eso tendré materia prima para empezar a cacharrear de verdad. De momento ha bajado 253 páginas de 638. Voy a dar un paseo.
El script ha terminado de descargar las páginas. Mwahahahaha...
Le ha llevado poco más de media hora. Después, ha concatenado todas ellas en un gran índice que procesaré después mediante expresiones regulares.
Le ha llevado poco más de media hora. Después, ha concatenado todas ellas en un gran índice que procesaré después mediante expresiones regulares.

El siguiente paso ha sido offline: he procesado con una expresión regular los resultados del portal de RTVE y he insertado los telediarios encontrados en una base de datos de ultimísima generación: SQlite 😂
¿Para qué complicarse la vida?
La regex: gist.github.com/JaimeObregon/d…
¿Para qué complicarse la vida?
La regex: gist.github.com/JaimeObregon/d…

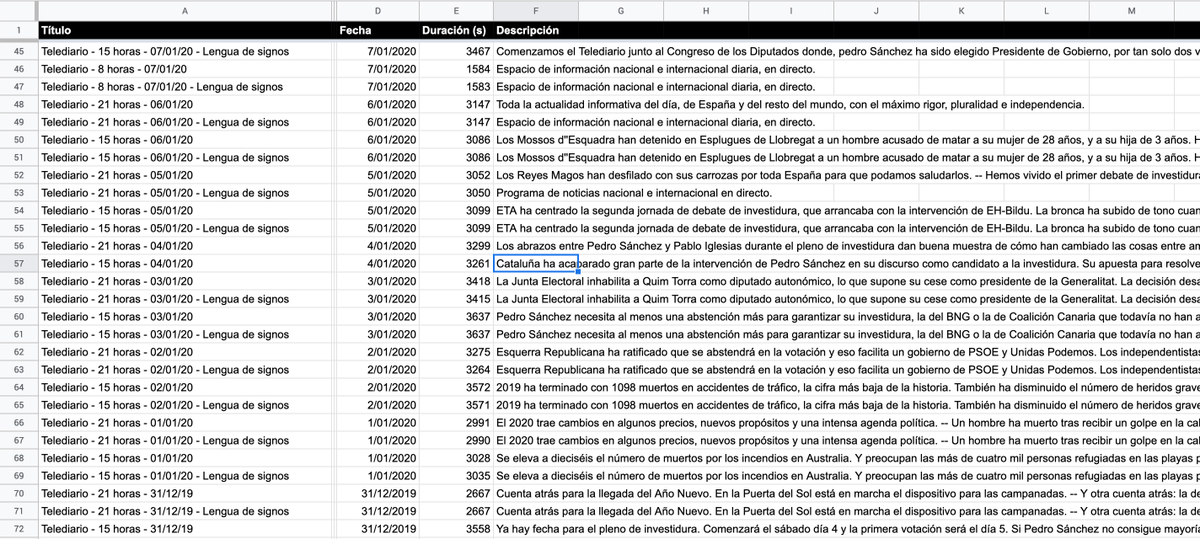
Ahora ya tengo estructurados +12.600 telediarios. Mola™️.
He pensado que para compartirlo es mejor subirlo a una hoja de cálculo en la nube. Aquí la tenéis: bit.ly/35YcEFQ
Seguiré destripándolos y compartiendo. Sígueme si quieres ver el proceso. Haz RT para difundir 👍
He pensado que para compartirlo es mejor subirlo a una hoja de cálculo en la nube. Aquí la tenéis: bit.ly/35YcEFQ
Seguiré destripándolos y compartiendo. Sígueme si quieres ver el proceso. Haz RT para difundir 👍
¡Sigamos experimentando con telediarios!😀 He actualizado el documento y ahora refleja la URL de cada telediario. El subtitulado más antiguo que he encontrado es del 27/12/2013, 15:00 👍
Tras suprimir los de lengua de signos me salen 5.841. Son estos: gist.github.com/JaimeObregon/d…
Tras suprimir los de lengua de signos me salen 5.841. Son estos: gist.github.com/JaimeObregon/d…

Ahora mismo estoy descargando ya todos los subtítulos de todos los telediarios YEAH 🚀.
Es el momento de la verdad <dramatización>LA TENSIÓN SE CORTA CON UN CUCHILLO</dramatización>: ahí está escrito todo lo pronunciado en los últimos 6 AÑOS de telediario.
El script es así:
Es el momento de la verdad <dramatización>LA TENSIÓN SE CORTA CON UN CUCHILLO</dramatización>: ahí está escrito todo lo pronunciado en los últimos 6 AÑOS de telediario.
El script es así:

Hago cosas complejas con datos para poder responderme Preguntas Absurdas™️. De momento…:
@marianorajoy: 13.273 menciones en 6 años.
@sanchezcastejon: 6.826
@KRLS Puigdemont: 4.138
Artur Mas: 2613
@PabloIglesias: 2.555
¡Ojo! Resultados de mi escrutinio todavía provisionales 😂
@marianorajoy: 13.273 menciones en 6 años.
@sanchezcastejon: 6.826
@KRLS Puigdemont: 4.138
Artur Mas: 2613
@PabloIglesias: 2.555
¡Ojo! Resultados de mi escrutinio todavía provisionales 😂
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias — "ETA" (que cesó el fuego en 2011): 2.312 menciones desde 2014 🤦♂️.
— "Bárcenas": 894 menciones.
— "Urdangarín": 782.
— "Cataluña": ¡...récord! 17.600
— "Cantabria": 3.135.
— "Galicia": 6.526
— "Buenas noches": 4.176 veces.
— "Bárcenas": 894 menciones.
— "Urdangarín": 782.
— "Cataluña": ¡...récord! 17.600
— "Cantabria": 3.135.
— "Galicia": 6.526
— "Buenas noches": 4.176 veces.
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias Seguiré obteniendo información útil y divertida de los telediarios 🧐 Pero estoy de viaje y es de noche.
Sígueme si quieres que saque más miga a los datos. Haz retuit a este tuit inicial si quieres darme ánimos. Hago esto en mi tiempo libre y por pasión✌️
Sígueme si quieres que saque más miga a los datos. Haz retuit a este tuit inicial si quieres darme ánimos. Hago esto en mi tiempo libre y por pasión✌️
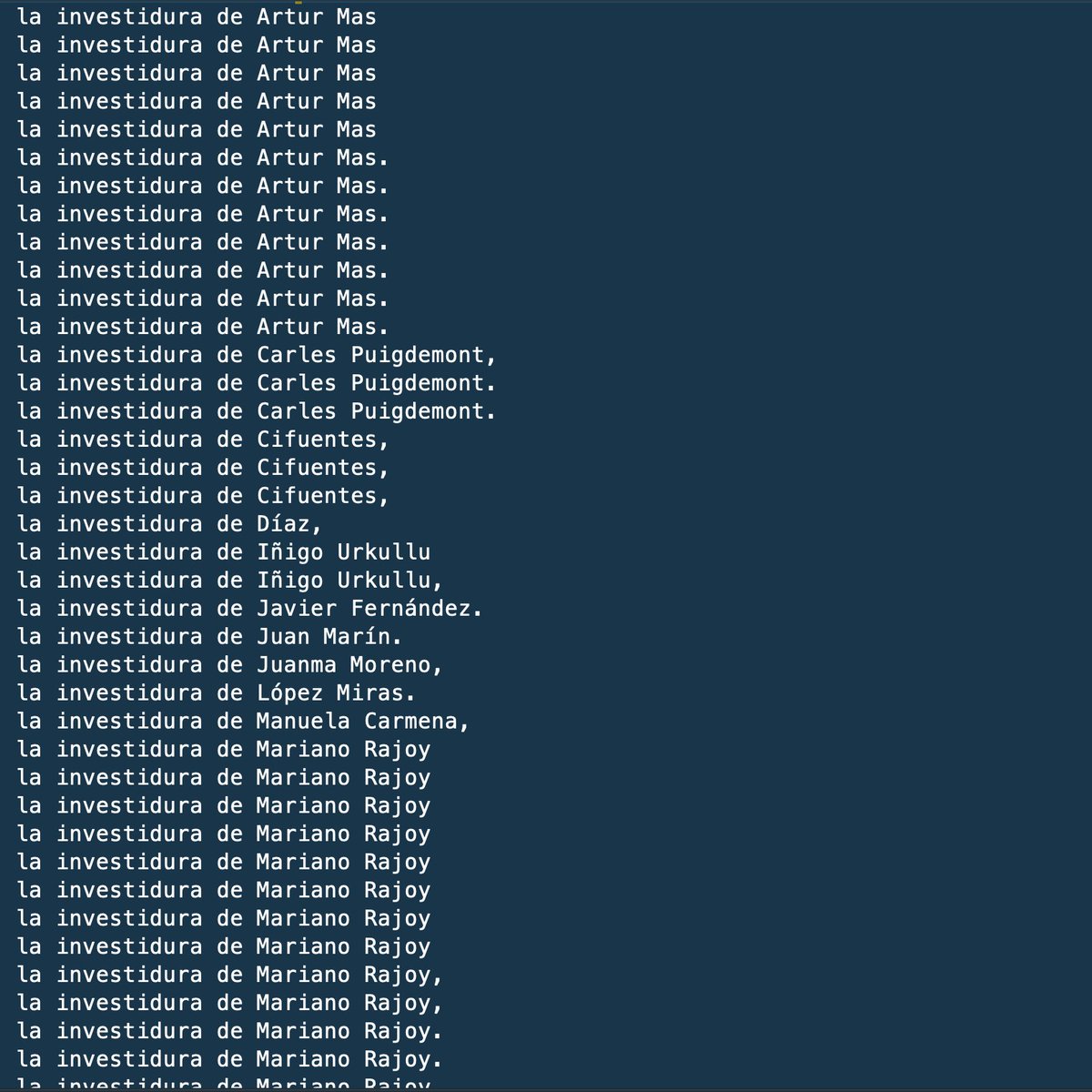
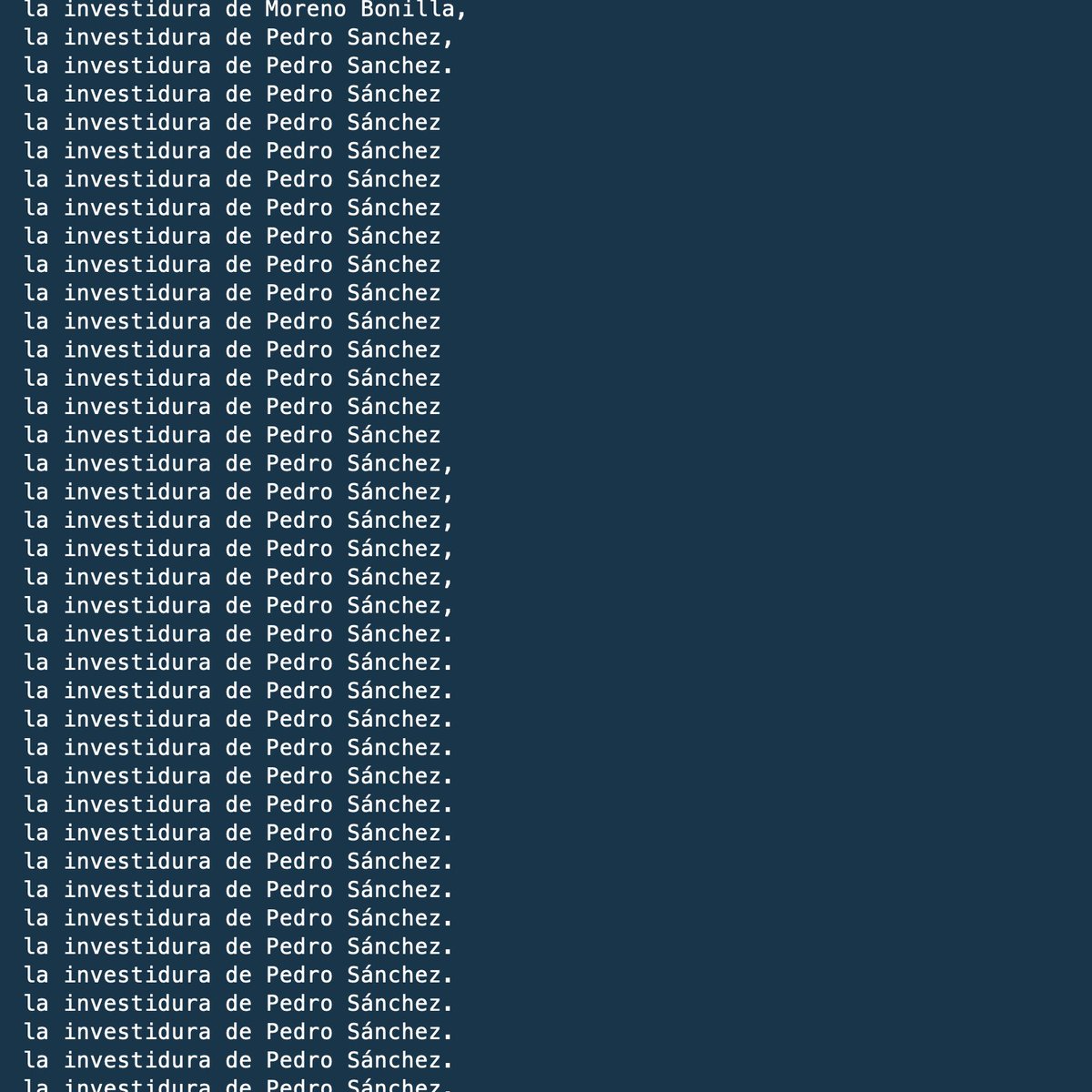
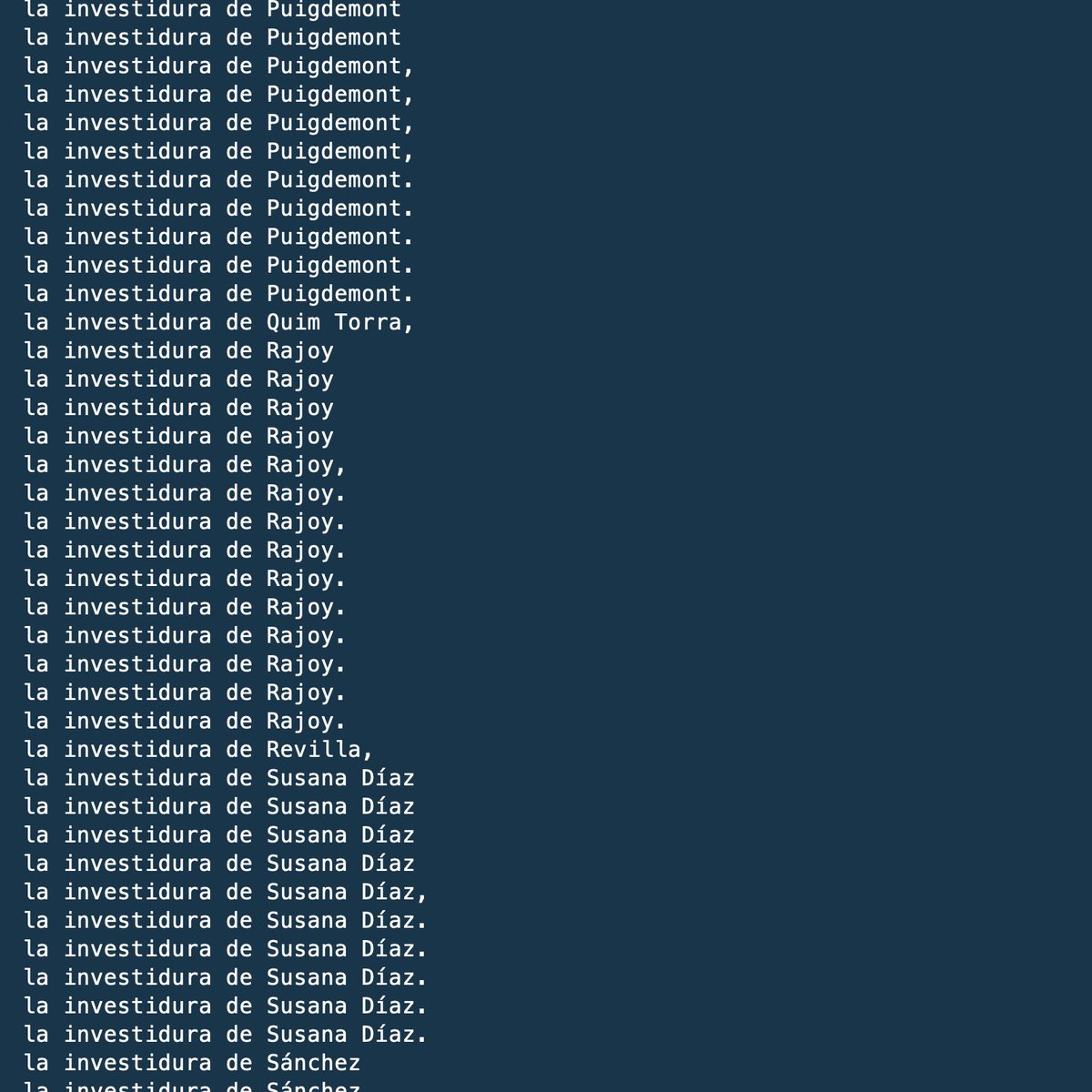
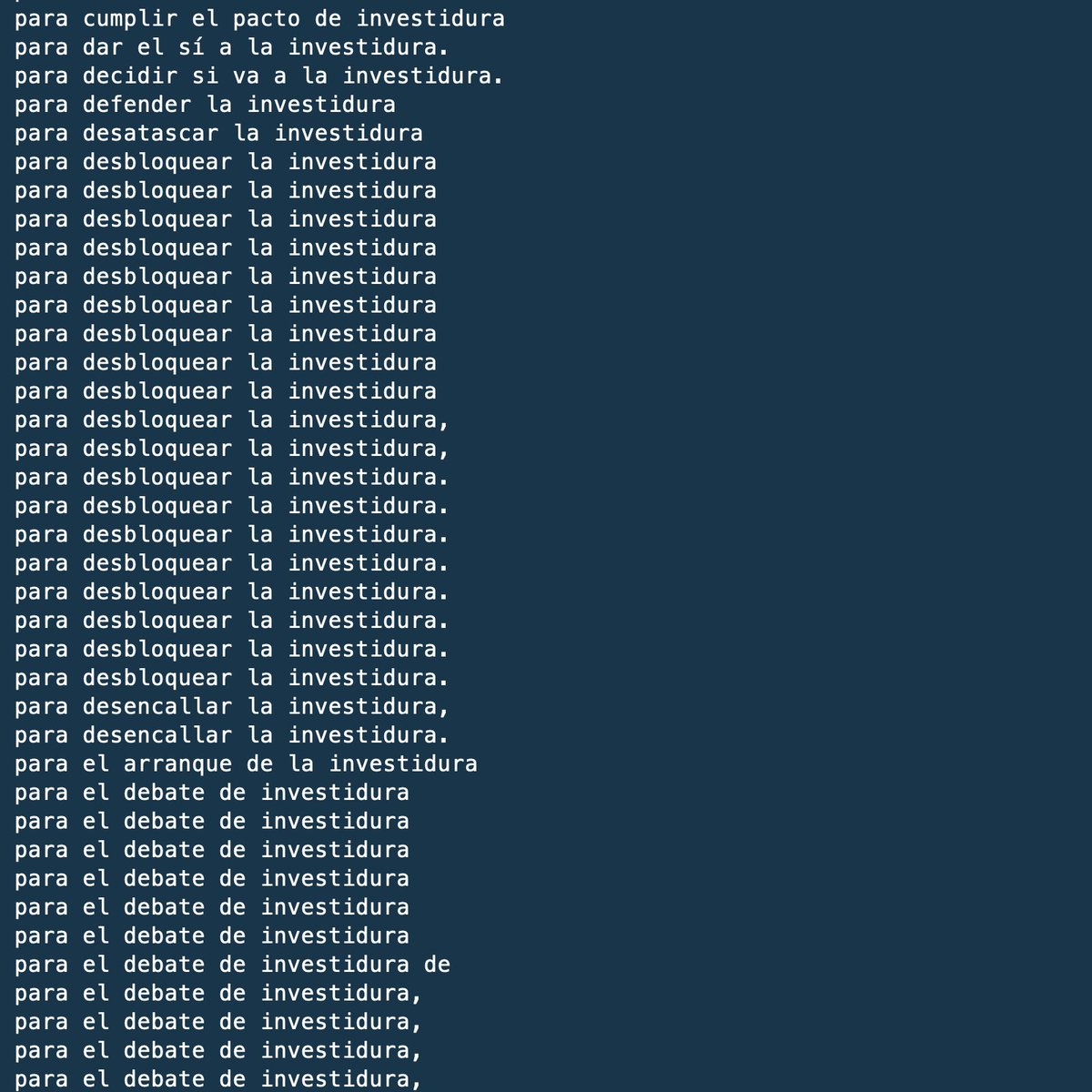
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias ¿Cuántas veces se ha hablado de investiduras en el telediario desde 2014?
🤓 5183 veces. Aquí están todas: gist.github.com/JaimeObregon/b…
Este análisis es muy simple: quisiera hacer un estudio más útil, más elaborado… pero ahora soy un mero humano con sueño que hace esto por deporte.
🤓 5183 veces. Aquí están todas: gist.github.com/JaimeObregon/b…
Este análisis es muy simple: quisiera hacer un estudio más útil, más elaborado… pero ahora soy un mero humano con sueño que hace esto por deporte.
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias 😂Encuesta rápida. En 2⃣ horas publico el resultado ⚡️
¿Cuántas veces crees que se ha dicho "mierda" 💩 en un telediario de RTVE desde 2014?
¿Cuántas veces crees que se ha dicho "mierda" 💩 en un telediario de RTVE desde 2014?
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias Me ha sorprendido el dato: ¡114 veces! Casi siempre en un contexto de fútbol y/o xenofobia 😑.
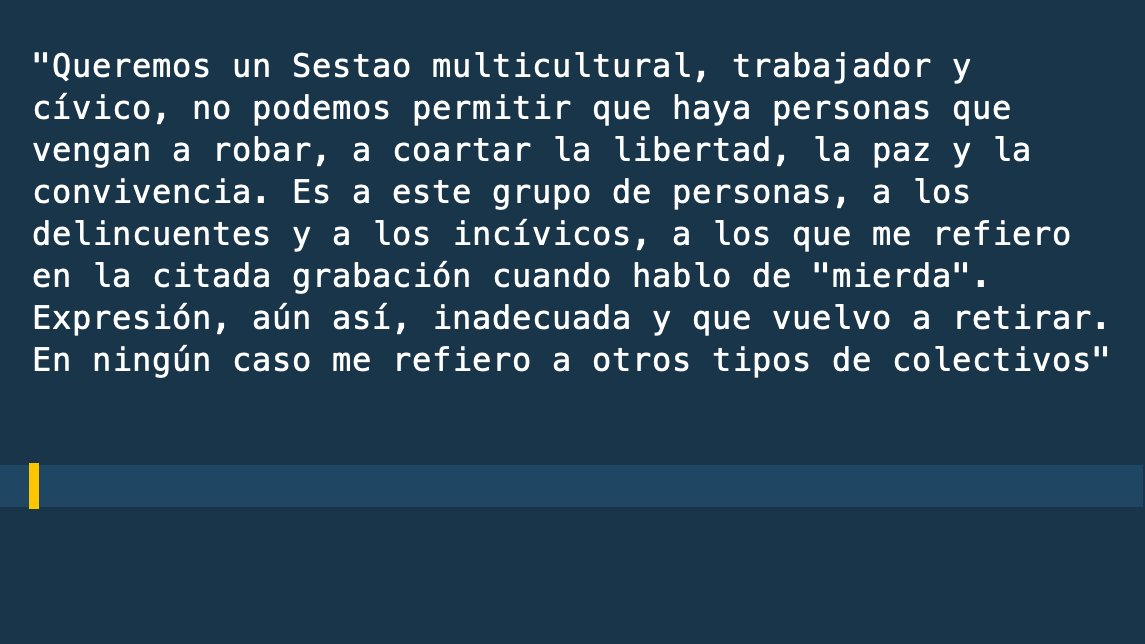
Pero los políticos también son deslenguados. Por ejemplo, el alcalde que dijo: "La mierda ya no viene a Sestao; si no, la echo yo. La echo yo." Y claro, la lió.
Luego se disculpó así:
Pero los políticos también son deslenguados. Por ejemplo, el alcalde que dijo: "La mierda ya no viene a Sestao; si no, la echo yo. La echo yo." Y claro, la lió.
Luego se disculpó así:
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias La lista completa con los 114 resultados la he publicado aquí: gist.github.com/JaimeObregon/9…
@marianorajoy @sanchezcastejon @KRLS @PabloIglesias Perdonad este hiato de unos días, pero ando algo regular de salud. No obstante... ¡ya tengo la transcripción textual de los telediarios de RTVE! Y ha quedado un domingo fantástico para publicarlos ✌️
Pero es un fichero de 121 MB y ni Google ni LibreOffice pueden con él.
Pero es un fichero de 121 MB y ni Google ni LibreOffice pueden con él.
Quiero publicar estos datos para que otros podáis continuar mi labor haciendo Procesado de Lenguaje Natural (NLP), análisis semántico, o meras búsquedas textuales. Hay un universo de posibilidades 😀 para sacar valor a los telediarios.
¿Igual lo cuelgo en un repo de Github?
¿Igual lo cuelgo en un repo de Github?
Esta es la expresión regular que he utilizado para convertir los ficheros VTT de subtítulos en largas cadenas de texto corrido.
Tiene todavía algún fleco por pulir, pero es una primera aproximación funcional. Ha sido fácil.
Tiene todavía algún fleco por pulir, pero es una primera aproximación funcional. Ha sido fácil.

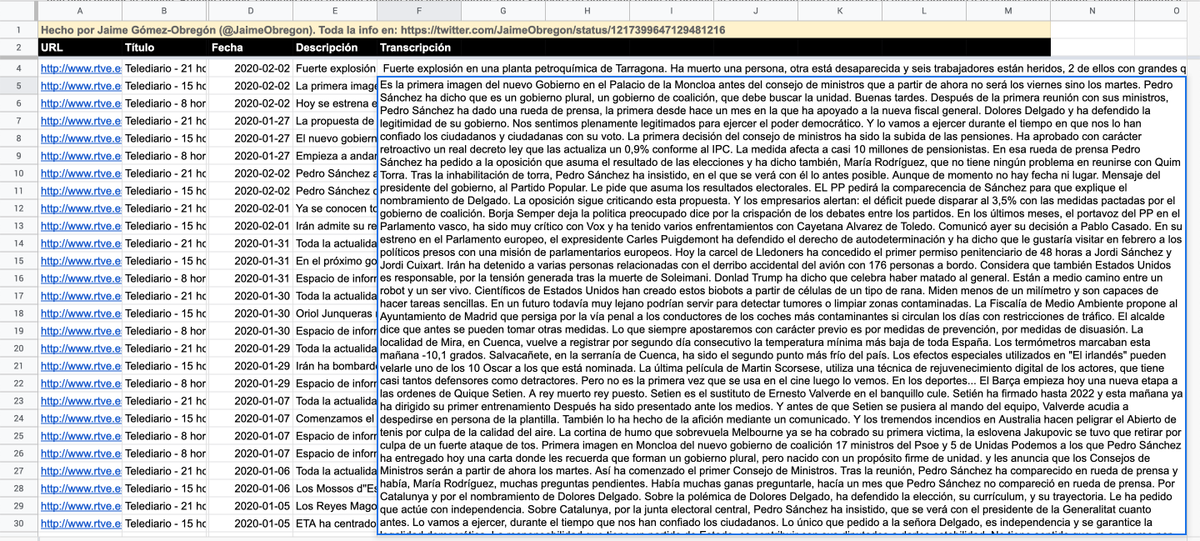
▶️ ¡Lo prometido es deuda! He añadido a la tabla de mi experimento la transcripción de todos los telediarios de RTVE de los últimos años. Es mucho texto, lo tenéis todo en: bit.ly/35YcEFQ
Lo he obtenido procesando los subtítulos existentes en el portal de RTVE. ¡Es oro!
Lo he obtenido procesando los subtítulos existentes en el portal de RTVE. ¡Es oro!
Hay que agradecer 🙏 a RTVE 📺 el esfuerzo que hacen subtitulando los telediarios. Con ello los hacen más accesibles para todos, no solo para las personas sordas.
Me encantaría que otros especialistas se sumen haciendo analítica, procesado de lenguaje natural, meras búsquedas...
Me encantaría que otros especialistas se sumen haciendo analítica, procesado de lenguaje natural, meras búsquedas...

Por ejemplo, me pregunto si expertos como @victorianoi podría alimentar su potente @graphext para extraer más valor de esta crónica de la historia reciente de España que suponen los telediarios.
También sería brutal hacer "Named Entity Recognition" (NER) sobre estos textos 🤤
También sería brutal hacer "Named Entity Recognition" (NER) sobre estos textos 🤤

El Procesado de Lenguaje Natural (NLP) es una ciencia compleja, donde hay frecuentes avances que hacen posible a las máquinas extraer conocimiento de grandes masas de texto desestructurado cada vez con mayor precisión, identificando personas, lugares, conceptos, eventos...

Otros experimentos interesantísimos que se pueden hacer con estos datos que he procesado son, por ejemplo, lo que hizo aquí @TPoliticas analizando si los medios se hacen eco de las polémicas o son los medios los que 𝘨𝘦𝘯𝘦𝘳𝘢𝘯 las polémicas:
@TPoliticas Por cierto, como dato curioso: hay tres telediarios al día: a las 8, a las 15 y a las 21. RTVE subtitula los dos últimos.
Y siguiendo con las curiosidades... hay muchas formas de saludar a los telespectadores pero... ¿cuáles son las más frecuentes? Estas:
Y siguiendo con las curiosidades... hay muchas formas de saludar a los telespectadores pero... ¿cuáles son las más frecuentes? Estas:

@TPoliticas ¿Y por la tarde? Por aplastante mayoría a mediodía es: "¿Qué tal?, buenas tardes". Por las noches, en cambio, gana "Hola, (muy) buenas noches".
Es curioso pero inútil™️ saberlo 😜
Es curioso pero inútil™️ saberlo 😜

@TPoliticas Buenos, pero no me he pegado con miles de telediarios para publicar una tabla y hacer estadísticas tontas... sino para hacer un buscador de telediarios y publicarlo al alcance de todos. Y aquí es donde tengo excelentes noticias...
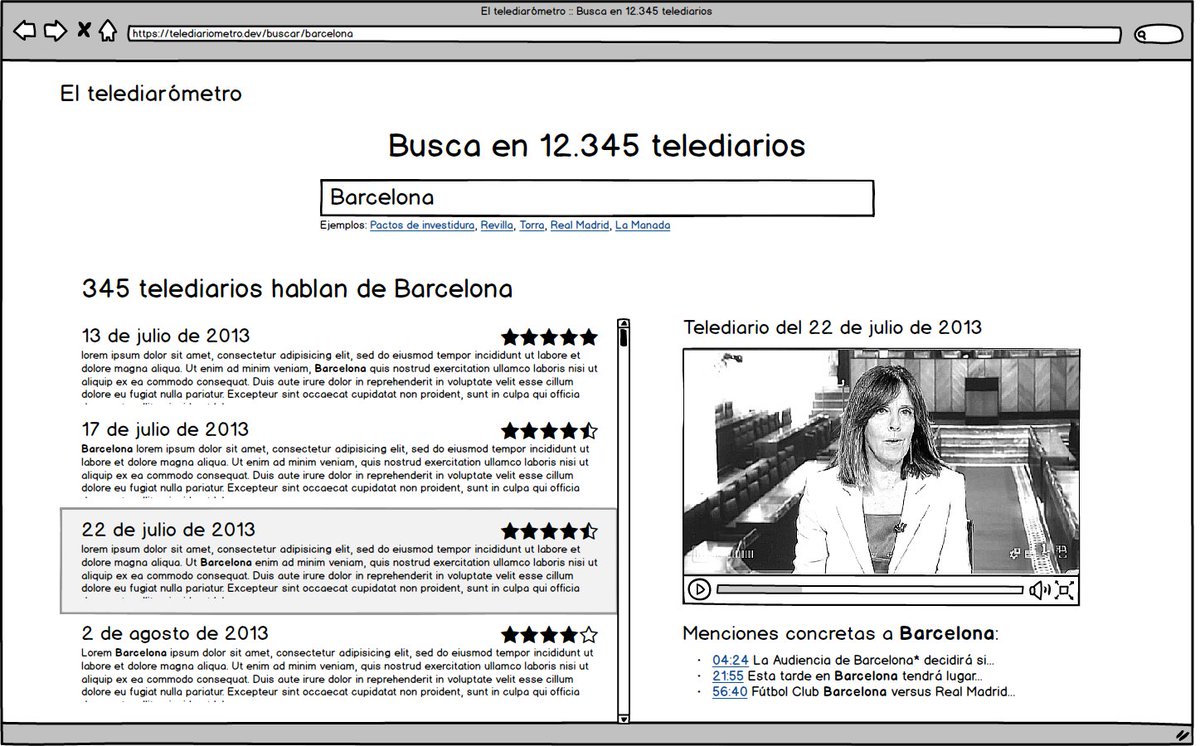
@TPoliticas 👉...¡y es que me ha contactado la gente de @civio para decirme que tienen esta herramienta web casi lista! Y tiene una pintaza impresionante 👇
Seguid a la Fundación @civio y a los enormes @dcabo y @evabelmonte (et al.) — Hacen un trabajo enorme en pro de la transparencia ❤️
Seguid a la Fundación @civio y a los enormes @dcabo y @evabelmonte (et al.) — Hacen un trabajo enorme en pro de la transparencia ❤️