#統計 1つ前のツイートのリンク先の解説
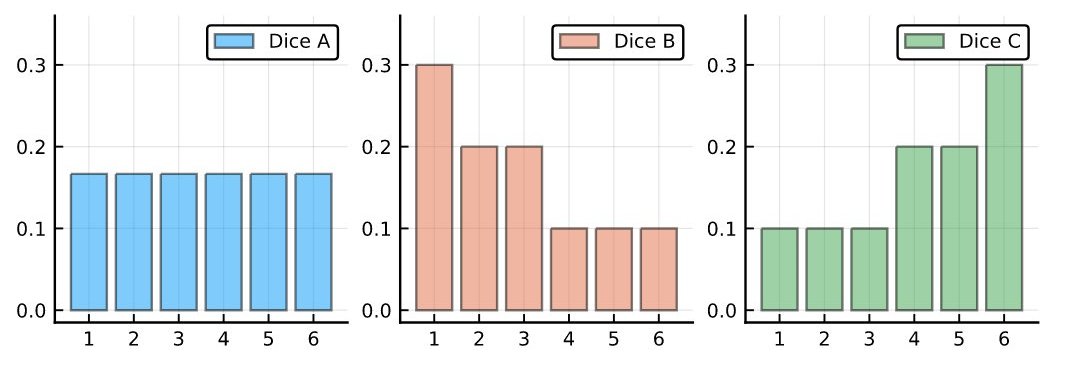
採用したモデルは「サイコロA,B,Cのどれかである」で事前分布でA,B,Cが等確率。サイコロA,B,Cの出目の分布は添付画像の通り。
しかし、推定先のサイコロXの出目の分布はサイコロA,B,Cからかけ離れていた。そして、推定・推測・推論にも失敗した。
採用したモデルは「サイコロA,B,Cのどれかである」で事前分布でA,B,Cが等確率。サイコロA,B,Cの出目の分布は添付画像の通り。
しかし、推定先のサイコロXの出目の分布はサイコロA,B,Cからかけ離れていた。そして、推定・推測・推論にも失敗した。
#統計 扱っている状況が単純でない場合には、統計分析に使用したモデルが現実において妥当かどうかはそう簡単には分かりません。
そして、モデルが妥当であるかどうかで、統計分析が信用できるか否かが決まります。
これはベイズであろうがなかろうが同じこと。
仮説検定や信頼区間でも同じ。
そして、モデルが妥当であるかどうかで、統計分析が信用できるか否かが決まります。
これはベイズであろうがなかろうが同じこと。
仮説検定や信頼区間でも同じ。
#統計
A氏>我々は可能な限り努力して、妥当だと思われる確率モデルと事前分布を用いて、◯◯という仮説が正しい確率はほぼ100%になることを確認できました!
B氏>で、そのモデルが現実において妥当な証拠は?
A氏>我々はベイズ主義に基いて研究しているので、その質問には答えられません!
A氏>我々は可能な限り努力して、妥当だと思われる確率モデルと事前分布を用いて、◯◯という仮説が正しい確率はほぼ100%になることを確認できました!
B氏>で、そのモデルが現実において妥当な証拠は?
A氏>我々はベイズ主義に基いて研究しているので、その質問には答えられません!
#統計
B氏>😱😱😱
A氏>我々は可能な限り努力して妥当だと思われるモデルを採用しました!そのモデルとデータから、我々は◯◯という仮説が正しい確率はほぼ100%であると考えざるを得なくなったということです!
B氏>努力したことは認めよう。でも、そのモデルが妥当な証拠はどこにあるの?
B氏>😱😱😱
A氏>我々は可能な限り努力して妥当だと思われるモデルを採用しました!そのモデルとデータから、我々は◯◯という仮説が正しい確率はほぼ100%であると考えざるを得なくなったということです!
B氏>努力したことは認めよう。でも、そのモデルが妥当な証拠はどこにあるの?
#統計 stattanさんの言う通りで、渡辺澄夫『ベイズ統計の理論と方法』は確かに難しい本かもしれませんが、言葉による説明の部分が非常に面白く読める本です。味のある言葉による解説が多い。
例えば添付画像のように「人文社会科学における確率モデルは云々」とも書いてあります。
例えば添付画像のように「人文社会科学における確率モデルは云々」とも書いてあります。

#統計 データのサイズが増えるに従って、それまでに見えてなかった詳細な構造が見えて来ることは、科学の世界では普通のことだと思います。
その場合には分析用のモデル自体を更新した方がよい。
最初に採用したモデルを固定したままベイズ更新を続けても、妥当でない推論の収束先を得るだけ。
その場合には分析用のモデル自体を更新した方がよい。
最初に採用したモデルを固定したままベイズ更新を続けても、妥当でない推論の収束先を得るだけ。
#統計
添付画像1
【ベイズ統計とは、標本を必ずとも必要としない】‼️‼️
添付画像2は to-kei.net/bayes/ より。いつものデタラメが書いてあり、ベイズであることが極めて疑わしい肖像画が引用されているのも典型的。テンプレか?
添付画像3の正しい考え方は
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より。
添付画像1
【ベイズ統計とは、標本を必ずとも必要としない】‼️‼️
添付画像2は to-kei.net/bayes/ より。いつものデタラメが書いてあり、ベイズであることが極めて疑わしい肖像画が引用されているのも典型的。テンプレか?
添付画像3の正しい考え方は
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より。



#統計 私による to-kei.net 批判についてはツイログの検索
twilog.org/genkuroki/sear…
を参照。相当に辛辣な批評になってしまっていますが、参考になれば幸いです。
統計学入門の教科書に問題があるので、問題のある教科書通りの解説を拡散すると必然的に批判されることになってしまう。
twilog.org/genkuroki/sear…
を参照。相当に辛辣な批評になってしまっていますが、参考になれば幸いです。
統計学入門の教科書に問題があるので、問題のある教科書通りの解説を拡散すると必然的に批判されることになってしまう。
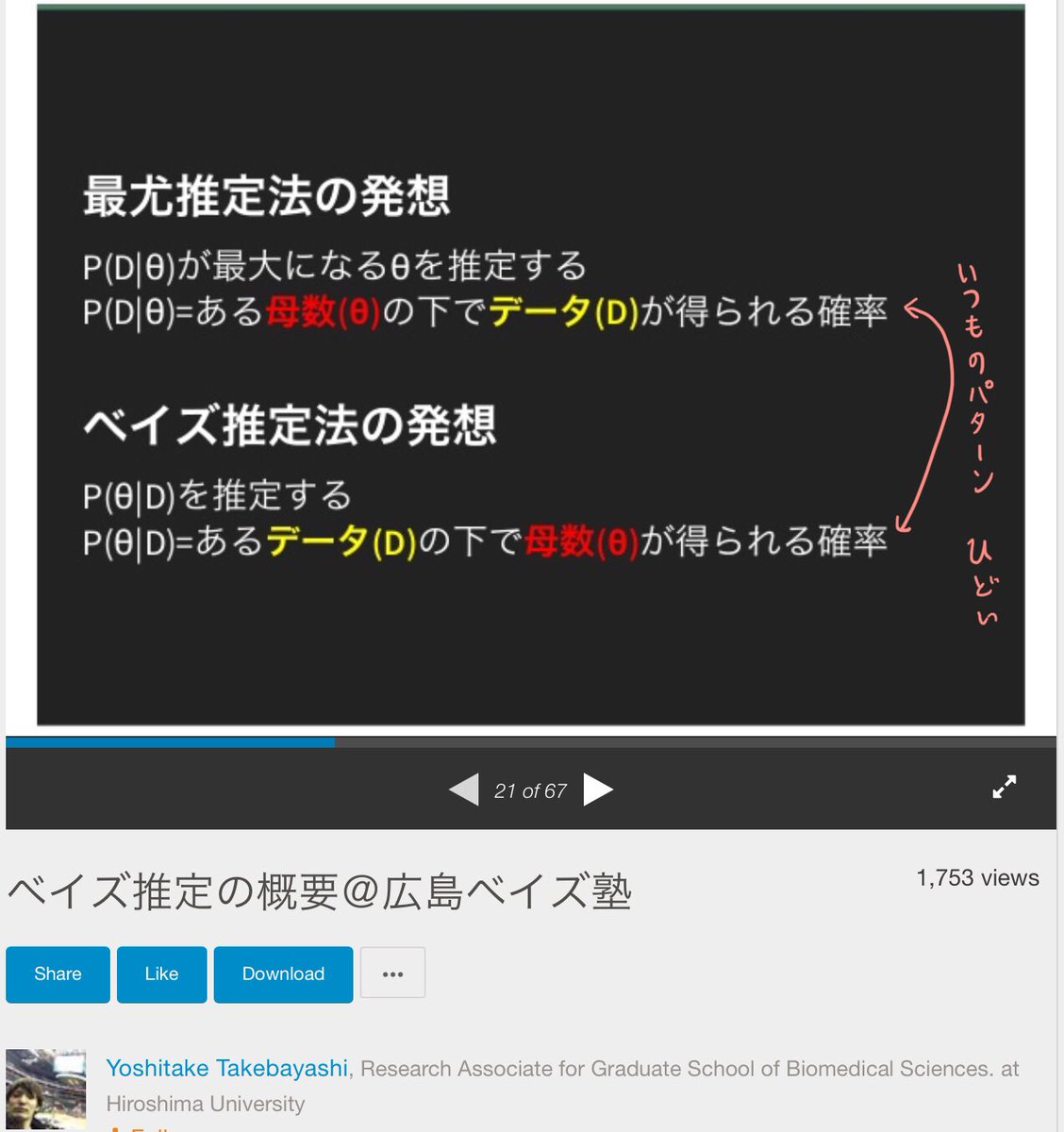
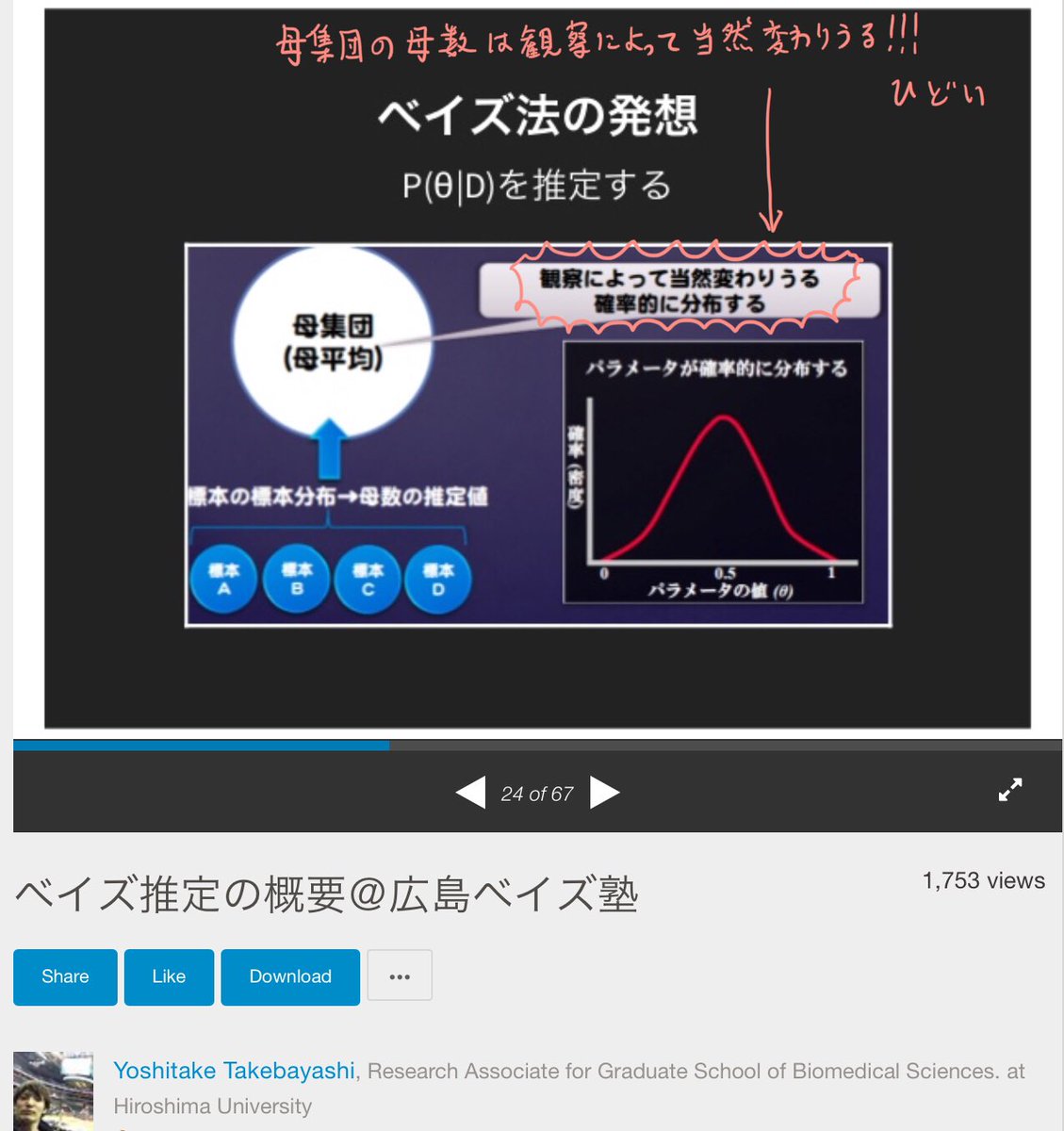
#統計 添付画像1,2は
slideshare.net/yoshitaket/ws-…
ベイズ推定の概要@広島ベイズ塾
Yoshitake Takebayashi
Published on Mar 3, 2015
より。添付画像2によれば、母集団の母数も
【観察によって当然変わりうる】
らしい‼️‼️
添付画像3の正しい考え方は
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より(既出)。
slideshare.net/yoshitaket/ws-…
ベイズ推定の概要@広島ベイズ塾
Yoshitake Takebayashi
Published on Mar 3, 2015
より。添付画像2によれば、母集団の母数も
【観察によって当然変わりうる】
らしい‼️‼️
添付画像3の正しい考え方は
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より(既出)。

#統計 ベイズであろうがなかろうが、例えば、S市の小学6年生男子の体重全体を母集団とするとき、その平均は確定値。
母集団からの無作為抽出したサンプルも、ベイズであろうがなかろうが、確率変数の実現値とみなされる。
事後分布は数学的モデル内部でのみ通用する確率分布に過ぎない。
母集団からの無作為抽出したサンプルも、ベイズであろうがなかろうが、確率変数の実現値とみなされる。
事後分布は数学的モデル内部でのみ通用する確率分布に過ぎない。
#統計 ベイズについて誤解を広まる側にまわってしまった人達は、関連の資料をインターネット上から削除するのではなく、過去に広めた誤解を完全否定するために使える資料を作って公開して欲しいと思います。
誤解の蔓延は現時点で結構ひどいことになっているので、その責任を取る必要があると思う。
誤解の蔓延は現時点で結構ひどいことになっているので、その責任を取る必要があると思う。
#統計 あと、私が酷評しているような資料であっても、それはピンポイントで引用している部分がひどいだけで、具体的な計算法や統計関係のソフトウェアの使い方の解説の部分は十分に有用な資料になっていることが多いと思っています。
#統計 以下のリンク先の、渡辺澄夫『ベイズ統計の理論と方法』からの引用部分は素晴らしい。
擬似哲学的な議論で分からないことを分かることにしてしまうのは非常にまずいというお話。
まずい統計学教育を何年も続けてやってしまった人はその逆向きを行う責任がある。
擬似哲学的な議論で分からないことを分かることにしてしまうのは非常にまずいというお話。
まずい統計学教育を何年も続けてやってしまった人はその逆向きを行う責任がある。
#統計 渡辺澄夫『ベイズ統計の理論と方法』の出版は2012年です。WAICについて知っている人はこの本もしくは渡辺さんの別の解説を読んでいるはず。
WAICについて知っているような人達の中にも、ベイズ統計について広まっている俗説を解説している人達がいる不思議。
WAICについて知っているような人達の中にも、ベイズ統計について広まっている俗説を解説している人達がいる不思議。
#統計 正しい。
未知の母集団分布に「正しい事前分布」なんてものはないし、事前分布はモデルの一部分なので、
「ベイズ統計では、モデルが正しければ、仮説が正しい確率を計算できる」
という主張をしても意味がない。
渡辺澄夫『ベイズ統計の理論と方法』7.1節の説明はミスリィーディング。
未知の母集団分布に「正しい事前分布」なんてものはないし、事前分布はモデルの一部分なので、
「ベイズ統計では、モデルが正しければ、仮説が正しい確率を計算できる」
という主張をしても意味がない。
渡辺澄夫『ベイズ統計の理論と方法』7.1節の説明はミスリィーディング。
#統計 1つ前のツイートで指摘した通り、「(事前分布も含めて)正しいモデルの下では、仮説が正しい確率を求められる」という主張もナンセンスである。
「仮説が正しい確率」なるものは最初からナンセンス。
救いようがない。続く
「仮説が正しい確率」なるものは最初からナンセンス。
救いようがない。続く
#統計 「仮説が正しい確率」というような考え方を捨てても何も失われない。
渡辺澄夫『ベイズ統計の理論と方法』を読めば、最尤法やベイズ法を使えば、サンプルサイズ→大で、採用した正しくないモデルの範囲内でベストの推定結果が得られることが分かり、さらにモデル間の相対評価の方法も得られる。
渡辺澄夫『ベイズ統計の理論と方法』を読めば、最尤法やベイズ法を使えば、サンプルサイズ→大で、採用した正しくないモデルの範囲内でベストの推定結果が得られることが分かり、さらにモデル間の相対評価の方法も得られる。
#統計 渡辺澄夫『ベイズ統計の理論と方法』が採用している基本設定では、未知の分布q(x)のサンプルは分布
q(x_1)…q(x_n)
に従い、モデル内サンプルは分布
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に従うという設定になっています。未知の分布サイドには事前分布というものがない。続く
q(x_1)…q(x_n)
に従い、モデル内サンプルは分布
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に従うという設定になっています。未知の分布サイドには事前分布というものがない。続く
#統計 ところが同書7.1節では、未知の分布側のサンプルも
∫P(x_1|w)…P(x_n|w)Φ(w)dw
型の分布に従うという設定を採用しています。この設定は同書の他の部分にはないものなので、この点に注意しないと読者はひどい誤解をしてしまう可能性があります。7.1節の内容は他の部分にはほとんど無関係です。
∫P(x_1|w)…P(x_n|w)Φ(w)dw
型の分布に従うという設定を採用しています。この設定は同書の他の部分にはないものなので、この点に注意しないと読者はひどい誤解をしてしまう可能性があります。7.1節の内容は他の部分にはほとんど無関係です。
#統計 ついでに述べておくと、6.4節「統計的検定」を読むときにも、よりすっきりした理解をするために注意を要する部分があります。
p.184 定理25では、上のZ(X_1,…,X_n)型の尤度の商を扱い、p.185 注意67(2)では事前分布がデルタ分布の場合を扱っており~続く
p.184 定理25では、上のZ(X_1,…,X_n)型の尤度の商を扱い、p.185 注意67(2)では事前分布がデルタ分布の場合を扱っており~続く
#統計 続き~、ネイマン・ピアソンの補題をp.184 定理25の特別な場合とみなしています。その説明は論理的には誤りではないのですが、実際には、シンプルなネイマン・ピアソンの定理からp.184 定理25が容易に出せるので、この説明の仕方に読者は従わない方がよいと私は思っています。続く
#統計 ネイマン・ピアソンの補題の内容はシンプルに「2つの分布p₁(x), p₀(x) (後者が帰無仮説)について、L(X) = p₁(x)/p₀(x)が最強力検定を与える」と言えます。
これを Z(x)=Z(x_1,…,x_n) (x=(x_1,…,x_n)) 型の分布に適用すればp.184 定理25が得られます。
これを Z(x)=Z(x_1,…,x_n) (x=(x_1,…,x_n)) 型の分布に適用すればp.184 定理25が得られます。
#統計 さらに、既出ですが、第4章の4.3節が難しいと感じた人は以下のリンク先に書いたより初等的な議論もあることを知っておいた方がよいかもしれません。
genkuroki.github.io/documents/2016…
大学1年レベルまで初等化
nbviewer.jupyter.org/github/genkuro…
大学2~3年レベルまで初等化
genkuroki.github.io/documents/2016…
大学1年レベルまで初等化
nbviewer.jupyter.org/github/genkuro…
大学2~3年レベルまで初等化
#統計 訂正
❌ L(X) = p₁(x)/p₀(x)
⭕️ L(X) = p₁(X)/p₀(X)
例によって、x→Xの違いです。まあ、以上の説明で理解できる人はネイマン・ピアソンの補題を知っている人だけだと思うので、害はないと思いますが、念のために訂正しておきます。
❌ L(X) = p₁(x)/p₀(x)
⭕️ L(X) = p₁(X)/p₀(X)
例によって、x→Xの違いです。まあ、以上の説明で理解できる人はネイマン・ピアソンの補題を知っている人だけだと思うので、害はないと思いますが、念のために訂正しておきます。
#統計 仮に推定先の未知の分布サイドのサンプル(データ)の分布が
∫P(x_1|w)…P(x_n|w)Φ(w)dw
の形ならば、事前分布がΦ(w)で確率モデル部分がP(x|w)の正しいモデルを採用できれば、パラメーターwに関する仮説が正しい確率を求めることができます。
しかし、この設定は同書の他の部分の設定と違う。
∫P(x_1|w)…P(x_n|w)Φ(w)dw
の形ならば、事前分布がΦ(w)で確率モデル部分がP(x|w)の正しいモデルを採用できれば、パラメーターwに関する仮説が正しい確率を求めることができます。
しかし、この設定は同書の他の部分の設定と違う。
#統計 同書の他の部分の未知の分布サイドのデータの分布が
q(x_1)…q(x_n)
の形であるという設定では、事前分布がからむパラメータwがないので、「パラメータwに関する仮説が正しい確率」自体最初からナンセンスだということになります。モデル内部の仮想世界でのみそういう確率は考えられる。
q(x_1)…q(x_n)
の形であるという設定では、事前分布がからむパラメータwがないので、「パラメータwに関する仮説が正しい確率」自体最初からナンセンスだということになります。モデル内部の仮想世界でのみそういう確率は考えられる。
#統計 同感!
みんな同じように変なことを書いているので、震源地があると思うのですが、変なことを書いている人達は参照文献を示さない習慣を持っているようなので、全然遡れないのだ。
何を読んで変な考えを知ったのかに関する情報をみんなで共有するべきだと思います。
みんな同じように変なことを書いているので、震源地があると思うのですが、変なことを書いている人達は参照文献を示さない習慣を持っているようなので、全然遡れないのだ。
何を読んで変な考えを知ったのかに関する情報をみんなで共有するべきだと思います。
#統計 色々分かっていなかった時代の歴史的にのみ意味のある文献は現代においては証拠物件として引用できない。
21世紀の現代におかしなことを言っている人達は何を根拠にそういうおかしなことを言うようになったかが問題。
もしかして歴史的にのみ意味のある文献が根拠?
21世紀の現代におかしなことを言っている人達は何を根拠にそういうおかしなことを言うようになったかが問題。
もしかして歴史的にのみ意味のある文献が根拠?
#統計 ベイズではない肖像画(厳密にはベイズであることが極めて疑わしい肖像画)を何の断りもなく引用しているパターンも目立つので、そもそもまともに文献を引用する気がないのかもしれない。
数学的証明にありがちなself-containedな説明でもない。
数学的証明にありがちなself-containedな説明でもない。
#統計 もっともよく見かけるおかしな説明は
* 頻度論では母数は定数でデータは確率変数だが、ベイズ統計ではデータは定数で母数が確率変数になる。
というスタイルの説明です。これが一体どこから出て来たのかについては、歴史的にのみ意味を持つ文献さえ見当がつかない。
* 頻度論では母数は定数でデータは確率変数だが、ベイズ統計ではデータは定数で母数が確率変数になる。
というスタイルの説明です。これが一体どこから出て来たのかについては、歴史的にのみ意味を持つ文献さえ見当がつかない。
#統計 「ベイズ主義」やら「主観確率」については歴史的にのみ意味のある文献に色々書いてあることはwell-knownだと思う。
#統計 仮に、ベイズで実測値を未知の分布を持つ確率変数の実現値でモデル化していないとすると、ベイズでは実測値が運悪く大幅に偏ってしまっていて、それが原因で実測値をもとに推定した結果もひどく偏ってしまうリスクを考慮しないことになり、科学的には排除されるべき方法になってしまいます。続く
#統計 そして、ベイズであろうがなかろうが、使用するデータは同じです。
例えば、S市の小学6年生男子全員から30人を無作為抽出して、身長と体重のデータを得たとします。
そのデータをベイズ統計では分析した途端に、無作為抽出に伴うデータの確率的な偏りを考慮しなくなるのはおかしいです。続く
例えば、S市の小学6年生男子全員から30人を無作為抽出して、身長と体重のデータを得たとします。
そのデータをベイズ統計では分析した途端に、無作為抽出に伴うデータの確率的な偏りを考慮しなくなるのはおかしいです。続く
#統計 だから、ベイズであろうがなかろうが、データは未知の分布を持つ確率変数の実現値であると考える必要がある。
観測データを未知の分布を持つ確率変数でモデル化すると、ベイズ統計の事後分布も確率変数になり、モデルのパラメータは確率変数である事後分布に従う確率変数になります。
観測データを未知の分布を持つ確率変数でモデル化すると、ベイズ統計の事後分布も確率変数になり、モデルのパラメータは確率変数である事後分布に従う確率変数になります。
#統計 ベイズ統計を理解するには、「確率変数である事後分布に従う確率変数」なるものを理解する必要があります。
数学的な理解力が足りないと、そこから逃げるために「データは定数で事後分布は1つに確定している」などと間違った考え方に陥るリスクがあると思う。
そういう逃げ方はまずい。
数学的な理解力が足りないと、そこから逃げるために「データは定数で事後分布は1つに確定している」などと間違った考え方に陥るリスクがあると思う。
そういう逃げ方はまずい。
#統計 資料
文脈的に清水裕士さんが修正した原因は私だと思うのだが、そういう場合には影響を受けた私の発言にリンクを張って紹介しないと相当にまずいことをやっていることになります。その辺は大丈夫なのかな?
ブロックされた以降、彼が書いたものは読んでいません。
文脈的に清水裕士さんが修正した原因は私だと思うのだが、そういう場合には影響を受けた私の発言にリンクを張って紹介しないと相当にまずいことをやっていることになります。その辺は大丈夫なのかな?
ブロックされた以降、彼が書いたものは読んでいません。
#統計 余談:仮に未知の母集団分布q(x)が確率モデルp(x|w)によって、q(x)=p(x|w₀)と実現可能だったとしても(この意味で確率モデルp(x|w)が正しいとしても)、「パラメータwに関する仮説が正しい確率」は意味を持ちません。この場合も事前分布で測った確率はモデル内部の仮想世界でのみ意味を持つ。
#統計 資料
添付画像1は『パターン認識と機械学習 上』(所謂PRML)p.22より。ここにもよく見るデタラメな解説が!
添付画像2の正しい考え方はは渡辺澄夫の
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より。統計学ではなく、機械学習を勉強した人達の中にもおかしな考え方を学んで信じている人達が結構いるのかな?
添付画像1は『パターン認識と機械学習 上』(所謂PRML)p.22より。ここにもよく見るデタラメな解説が!
添付画像2の正しい考え方はは渡辺澄夫の
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
より。統計学ではなく、機械学習を勉強した人達の中にもおかしな考え方を学んで信じている人達が結構いるのかな?


#統計 「頻度論」と同じように標本分布に関する平均が汎化誤差のそれと漸近的に一致することがWAICやLOOCVの根拠なので、ベイズ統計で標本分布を考えずに【ただ1つの(つまり実際観測された)データ集合】しか考えないなら、WAICも1個抜き出し交差検証も全部潰れてしまう。ひどすぎ。論外。
#統計 PRMLでも赤枠で囲った部分には註釈も参照文献も示されていない。ベイズであろうがなかろうが、機械学習で使うデータ集合は同じものであり、主義の違いで性質は変わらない。
ベイズであろうがなかろうが、データ集合自体が運悪く偏りまくっていたら、その学習結果も偏りまくる。
ベイズであろうがなかろうが、データ集合自体が運悪く偏りまくっていたら、その学習結果も偏りまくる。

#統計 資料
検定や信頼区間の代用ではなく、検定や信頼区間そのものの場合も数学的なモデルを前提にしないと意味のある結果が出せない場合が多いです。
検定や信頼区間の場合も使用したモデルの妥当性に無頓着なのは非科学的態度なのでやめた法がよいよと私は繰り返し言って来た。
検定や信頼区間の代用ではなく、検定や信頼区間そのものの場合も数学的なモデルを前提にしないと意味のある結果が出せない場合が多いです。
検定や信頼区間の場合も使用したモデルの妥当性に無頓着なのは非科学的態度なのでやめた法がよいよと私は繰り返し言って来た。
#統計 最近では以下のリンク先スレッドでも、区間推定でも使用したモデルの妥当性に無頓着な教え方はよくないと指摘しています。
仮に〇〇統計という分野で、信頼区間を求めるのに使ったモデルの妥当性に無頓着な態度が当然視されているならば、〇〇統計という分野は非科学的だということになる。
仮に〇〇統計という分野で、信頼区間を求めるのに使ったモデルの妥当性に無頓着な態度が当然視されているならば、〇〇統計という分野は非科学的だということになる。
#統計 どういう話になっているか分からないのですが(清水さんは私をブロックしている)、モデルの妥当性は常に問題にされるべき。「仮定する」はどういう意味?
「パラメータの推定」という発想に「そのパラメータを含むモデルの妥当性を当然の前提にする」が付け加わると瞬時に非科学的な思考になる。
「パラメータの推定」という発想に「そのパラメータを含むモデルの妥当性を当然の前提にする」が付け加わると瞬時に非科学的な思考になる。
#統計 以下のリンク先でカイヤンさんが言っていることは大事。
サンプルのサイズが大きくなると未知の分布の詳細な構造が見えて来る、というのが基本的な考え方。解像度が上がって来る。
未知の真の分布を本当にぴったり含む超複雑なモデルよりも、適切ない解像度のモデルの方が予測性能は高くなる。
サンプルのサイズが大きくなると未知の分布の詳細な構造が見えて来る、というのが基本的な考え方。解像度が上がって来る。
未知の真の分布を本当にぴったり含む超複雑なモデルよりも、適切ない解像度のモデルの方が予測性能は高くなる。
#統計 AICの漸近論はモデルによる未知の分布の実現可能性を仮定しますが、モデルがそう複雑ではなくてパラメータの個数の項の大きさが問題にならず、対数尤度の項が支配的な状況では、実現可能性が成立していなくても、十分に実用的なモデル選択の道具になります。
#統計 数学的な前提の詳細全部が致命的な問題になるわけではないと思う。問題はむしろ数学的詳細の理解が足りないことではなく、
モデルを前提にした分析をしているのに、モデルの妥当性について無頓着な態度
だと思います。数学的ではなく、常識的な意味で非科学的な態度を取っていることになる。
モデルを前提にした分析をしているのに、モデルの妥当性について無頓着な態度
だと思います。数学的ではなく、常識的な意味で非科学的な態度を取っていることになる。
#統計 例えば、AICの漸近論が証明に必要な前提条件が本当は成立しているか分からないのに、それを「仮定する」というのは非常にまずい。
仮定しなくても、対数尤度にパラメータ数の違いよりもぅっと大きな差が付いていれば、対数尤度が大きなモデルの方を選ぶことは合理的だと思う。
仮定しなくても、対数尤度にパラメータ数の違いよりもぅっと大きな差が付いていれば、対数尤度が大きなモデルの方を選ぶことは合理的だと思う。
#統計 あと、仮にAICの漸近論の前提が満たされている状況であっても、サンプルサイズn→∞でモデル選択に失敗する確率が0に収束しない場合があるという予備知識も重要だと思う。
統計学の使用はギャンブルであり、ギャンブルを他人に勧める人は正直に失敗するリスクを強調する必要がある。続く
統計学の使用はギャンブルであり、ギャンブルを他人に勧める人は正直に失敗するリスクを強調する必要がある。続く
#統計 モデル0がモデル1のパラメータ空間をより低次元に制限して得られたものであり、未知の分布がモデル0で実現可能なとき、モデル0,1での最尤法の予測分布の対数尤度比は漸近的にχ²分布に従います(Wilks' theorem)。それを使ってχ²検定を作れる。
AICはある意味でこの話の一般化になっています。
AICはある意味でこの話の一般化になっています。
#統計 AICを使っている場合に、モデル0がモデル1のパラメータ空間をより低次元に制限したものになっている場合は、AICによるモデル選択だけではなく、対数尤度比のχ²検定も使える状況になっています。
これを知っていれば、情報量基準と仮説検定が無関係でないことも分かる。
これを知っていれば、情報量基準と仮説検定が無関係でないことも分かる。
#統計 もちろん、仮説検定と情報量基準によるモデル選択には違いがあって、仮説検定では比較する片方のモデルを捨て去り難い帰無仮説扱いしますが、情報量基準によるモデル選択では2つのモデルを対等に扱います。あと、情報量基準はモデル0とモデル1の間に特別な関係がなくても使える。
#統計 直上に書いたことに近い解説が、渡辺澄夫『ベイズ統計の理論と方法』pp.80-82の例9にあります。分散1の正規分布モデルを例に説明が書いてあります。
さらにシンプルなベルヌイ分布モデルで遊びたいなら
nbviewer.jupyter.org/gist/genkuroki…
が参考になると思います(#Julia言語)。
例の計算大事。
さらにシンプルなベルヌイ分布モデルで遊びたいなら
nbviewer.jupyter.org/gist/genkuroki…
が参考になると思います(#Julia言語)。
例の計算大事。
#統計 #Julia言語
nbviewer.jupyter.org/gist/genkuroki…
にはベルヌイ分布モデル
p(x=1|w) = (x=1の確率) = w
p(x=0|w) = (x=0の確率) = 1-w
の場合に、AIC, WAIC, BIC, 自由エネルギーを計算しています。渡辺澄夫『ベイズ統計の理論と方法』を読むときに、このシンプルな例を知っていると少し楽になるはず。
nbviewer.jupyter.org/gist/genkuroki…
にはベルヌイ分布モデル
p(x=1|w) = (x=1の確率) = w
p(x=0|w) = (x=0の確率) = 1-w
の場合に、AIC, WAIC, BIC, 自由エネルギーを計算しています。渡辺澄夫『ベイズ統計の理論と方法』を読むときに、このシンプルな例を知っていると少し楽になるはず。
#統計 メモ
どういう話になっているのか分かりませんが、私が既存の統計学入門への批判で繰り返し述べて来た「検定や信頼区間の解説で数学的モデルを使っていることの説明が不十分なせいで、モデルと現実の区別が曖昧になり過ぎている」という指摘に通じるものがあると思ったのでメモっておきます。
どういう話になっているのか分かりませんが、私が既存の統計学入門への批判で繰り返し述べて来た「検定や信頼区間の解説で数学的モデルを使っていることの説明が不十分なせいで、モデルと現実の区別が曖昧になり過ぎている」という指摘に通じるものがあると思ったのでメモっておきます。
#統計 「仮説が正しい確率」と言っている事例の追加。
bookdown.org/sbtseiji/lswja…
jamoviで学ぶ心理統計
Danielle J Navarro & Dvid R Foxcroft
またしても「心理統計学」の事例。
【ベイズ流の視点では,統計的推論は信念の更新がすべて】という時代遅れで非科学的な考え方を信じている。
bookdown.org/sbtseiji/lswja…
jamoviで学ぶ心理統計
Danielle J Navarro & Dvid R Foxcroft
またしても「心理統計学」の事例。
【ベイズ流の視点では,統計的推論は信念の更新がすべて】という時代遅れで非科学的な考え方を信じている。





#統計 正しい考え方を紹介している事例
ameblo.jp/yusaku-ohkubo/…
A. Gelman "Philosophy and the practice of Bayes" の紹介
【・この時、事前分布は「事前の信念」であり事後分布は「仮説が正しい確率である」
2. しかし近年のベイズ統計においては、上のような見解を維持することが困難である】
ameblo.jp/yusaku-ohkubo/…
A. Gelman "Philosophy and the practice of Bayes" の紹介
【・この時、事前分布は「事前の信念」であり事後分布は「仮説が正しい確率である」
2. しかし近年のベイズ統計においては、上のような見解を維持することが困難である】
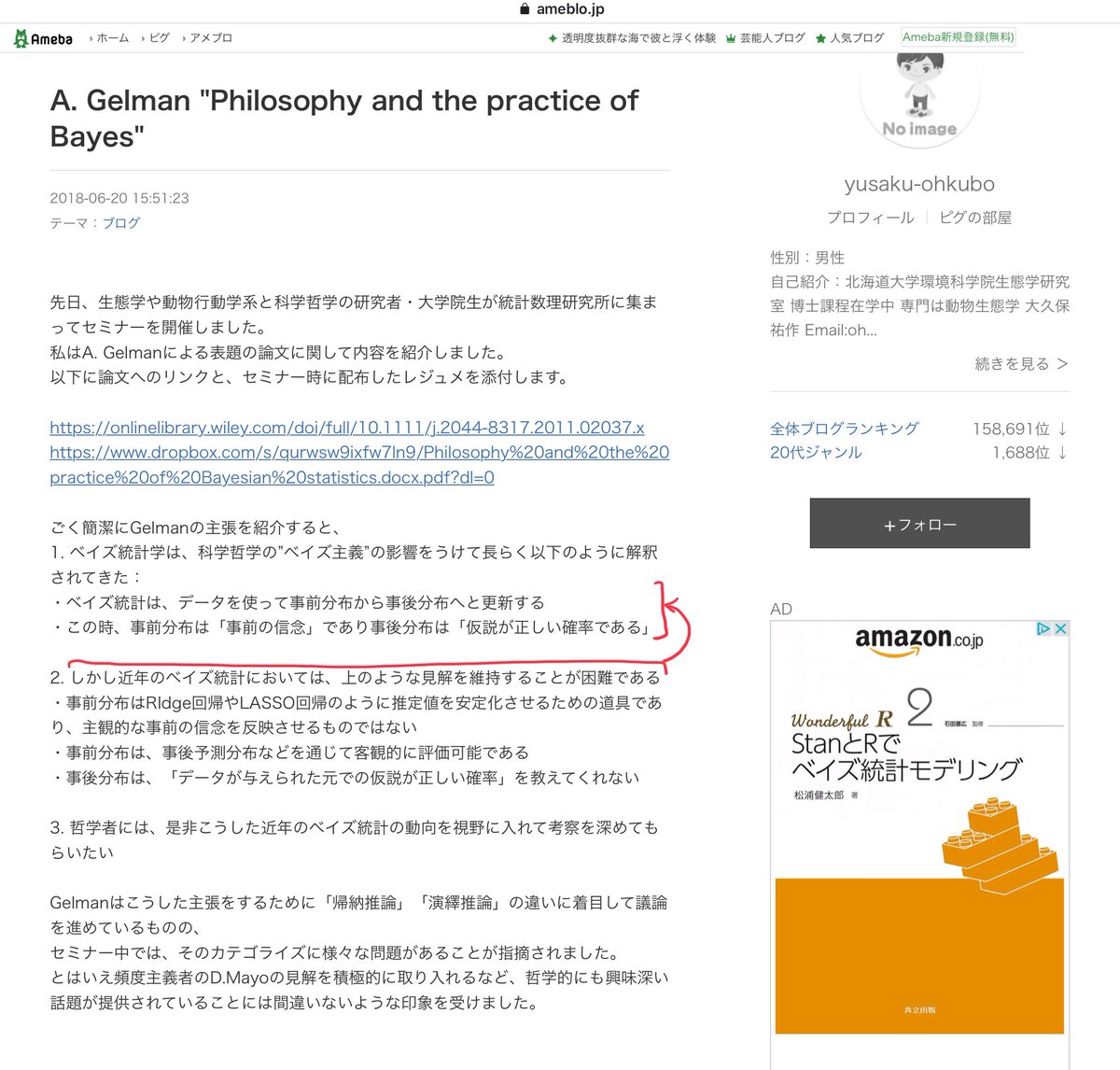
#統計 引用続き
【・事前分布はRIdge回帰やLASSO回帰のように推定値を安定化させるための道具であり、主観的な事前の信念を反映させるものではない
・事前分布は、事後予測分布などを通じて客観的に評価可能である
・事後分布は、「データが与えられた元での仮説が正しい確率」を教えてくれない】
【・事前分布はRIdge回帰やLASSO回帰のように推定値を安定化させるための道具であり、主観的な事前の信念を反映させるものではない
・事前分布は、事後予測分布などを通じて客観的に評価可能である
・事後分布は、「データが与えられた元での仮説が正しい確率」を教えてくれない】
#統計 引用続き
ベイズ主義の下でのベイズ統計観は現代では時代遅れで、合理的な考え方が広まっていることについて、ゲルマンさん曰く
【3. 哲学者には、是非こうした近年のベイズ統計の動向を視野に入れて考察を深めてもらいたい】
せめて半世紀前の赤池弘次さんくらいまでは追いつくべき。
ベイズ主義の下でのベイズ統計観は現代では時代遅れで、合理的な考え方が広まっていることについて、ゲルマンさん曰く
【3. 哲学者には、是非こうした近年のベイズ統計の動向を視野に入れて考察を深めてもらいたい】
せめて半世紀前の赤池弘次さんくらいまでは追いつくべき。
#統計 ベイズ統計の予測分布を使わなくても、事前分布を使うMAP法によって推定の平均二乗誤差を最尤法より下げられることを示す非常にシンプルな例(James-Stein推定)については以下のノートを参照。事前分布は推定誤差を下げるためにも役に立つ。今では常識の1つだと思う。
nbviewer.jupyter.org/github/genkuro…
nbviewer.jupyter.org/github/genkuro…
#統計 事前分布(を含むモデル全体)を客観的に評価する方法については以下を参照。
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
および以下のリンク先のリンク先
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
および以下のリンク先のリンク先
#統計 事前分布は「推定誤差を下げるためにも使える道具の1つ」であり、モデル評価時に客観的に評価される対象でもある。このようなことは数学的技術の発展によって可能になった。
【事前分布は「事前の信念」であり事後分布は「仮説が正しい確率である」】という考え方をする必要はない。
【事前分布は「事前の信念」であり事後分布は「仮説が正しい確率である」】という考え方をする必要はない。
#統計 悪い方の事例追加
時間の無駄なので読む必要はないが、豊田秀樹さんの本を絶賛している。内容的にもかなり呆れたものだ。
怖いのはこのブログ記事のような感覚で学生に「ベイズ統計」(もどき)について教えているかのうせいがあること。
kosugitti.net/archives/5211
時間の無駄なので読む必要はないが、豊田秀樹さんの本を絶賛している。内容的にもかなり呆れたものだ。
怖いのはこのブログ記事のような感覚で学生に「ベイズ統計」(もどき)について教えているかのうせいがあること。
kosugitti.net/archives/5211
#統計 現実に確率モデルに基いたベイズ統計の技術を応用するときには、採用したモデルの妥当性が事前には不明。
妥当かどうか不明の確率モデルを使って、信念の度合いを確率で表現した事前分布を事後分布に更新した結果を本当に信じているとしたら、その人は合理性に欠けた精神の持ち主です。続く
妥当かどうか不明の確率モデルを使って、信念の度合いを確率で表現した事前分布を事後分布に更新した結果を本当に信じているとしたら、その人は合理性に欠けた精神の持ち主です。続く
#統計 続き。以上のような理由で、ベイズ統計の技術の適用を、「普通の常識的な意味で合理的な人による信念の度合いの更新」とみなすことはナンセンスだと思う。
要するにベイズ主義とやらはつまらないナンセンスなことを大真面目に考えているだけだと思う。
非現実的なトイモデルとしても苦しい。
要するにベイズ主義とやらはつまらないナンセンスなことを大真面目に考えているだけだと思う。
非現実的なトイモデルとしても苦しい。
#統計 普通の意味で科学的に合理的な人物を想定するのではなく、数学的モデルの中だけにいる仮想的な「何か」の信念の度合いの更新とみなし、不完全な例え話であることを忘れなければ、「信念の更新」と言ってもよいかもしれないが、そういう発想を捨てても困らないことも理解しておかないとまずい。
#統計 ベイズ統計の普遍的な性質によって、ベイズ更新の結果が収束して、ひどく誤差の大きな(間違った)結論について「それが正しい確率は100%である」と結論してしまうようになってしまうことがあるんですね。
これを知っていたら「仮説が正しい確率が分かる」とはとても言えない。
これを知っていたら「仮説が正しい確率が分かる」とはとても言えない。
#統計 私ごときをブロックしていることが判明しても残念に思う必要はないと思います。
しかし、三浦麻子さんは、三浦さんが筆頭著者である
team1mile.com/sjpr61-1/
→ team1mile.com/sjpr61-1/miura…
に添付画像のように書いてあることの学問的責任は取らなければいけなくなるだろうと思いました。
しかし、三浦麻子さんは、三浦さんが筆頭著者である
team1mile.com/sjpr61-1/
→ team1mile.com/sjpr61-1/miura…
に添付画像のように書いてあることの学問的責任は取らなければいけなくなるだろうと思いました。

ブロックされていることに気付いたときに
なるほど。
という文字列が目に入って来て、ふきだしてしまいました(笑)。
こういうのはブロックされている本人にしかわからない楽しみ方かも。私自身はこの人のことは何も知りませんでした。人ではなく、言っている事柄の内容のみに興味がある。
なるほど。
という文字列が目に入って来て、ふきだしてしまいました(笑)。
こういうのはブロックされている本人にしかわからない楽しみ方かも。私自身はこの人のことは何も知りませんでした。人ではなく、言っている事柄の内容のみに興味がある。

#統計 もしもその【ベイズ主義の教科書を3ページ読んで】理解できた【尤度の解釈】が「仮説が正しい確率」「真値が含まれる確率」の類であれば、最近ツイッターでボコボコにフルボッコにされている考え方なので要注意。
詳しくはこのツイートがぶら下がっているスレッド全体を参照。続く
詳しくはこのツイートがぶら下がっているスレッド全体を参照。続く
#統計 「頻度論vs.ベイズ」的な見方に基くベイズ統計の解説は半世紀ほど時代遅れっぽいので避けた方が無難。
尤度の定義は「確率モデル内の仮想世界で現実から得たデータが生成される確率(密度)」で「確率モデルのデータへの適合度」を意味します。
尤度解説1↓
尤度の定義は「確率モデル内の仮想世界で現実から得たデータが生成される確率(密度)」で「確率モデルのデータへの適合度」を意味します。
尤度解説1↓
#統計 その型のミスリーディングな説明は普遍的で、そうでない教科書を見付けること自体が困難。これは日本語圏だけの問題では__ない__。
信頼区間の計算に使った確率モデルの標本分布で測った確率を考えると95%信頼区間に真の値が含まれる確率は(約)95%になる。続く
信頼区間の計算に使った確率モデルの標本分布で測った確率を考えると95%信頼区間に真の値が含まれる確率は(約)95%になる。続く
#統計 例えば、東京大学教養学部統計学教室編『統計学入門』にもミスリーディングな説明がある。標本分布の解説もその本にあるので、95%信頼区間の95%はモデル内の標本分布で測った確率だとはっきり説明すればよいのになぜかそうしていない。
#統計 「確率」という言葉をまっとうな議論で使う場合には「どのようにして測った確率なのか?」(どの確率分布で測った確率なのか)を即答できるようにすることが大事。
多くに場合に曖昧で混乱を招く原因になるので、「何で測った確率なのか」のも説明しながら「確率」という言葉を使った方が親切。
多くに場合に曖昧で混乱を招く原因になるので、「何で測った確率なのか」のも説明しながら「確率」という言葉を使った方が親切。
#統計 95%信用区間の95%が確率ではないかのような説明をする行為と「ベイズ統計の95%信用区間の95%は確率であり、解釈が分かりやすい」というデタラメな説明をする行為は表裏一体になっています。
これは大学での統計学教育の闇の一部分です。
日本語圏だけの問題では__ない__点が怖い。
これは大学での統計学教育の闇の一部分です。
日本語圏だけの問題では__ない__点が怖い。
#統計 ベイズ統計における事後分布はモデル内部の仮想世界内でのみ意味を持つ確率分布であり、現実世界に対応物がないので、事後分布で測った確率である「95%信用区間」の95%の現実世界での意味はよくわからないものになります。
この点は「頻度論」の95%信頼区間の方が分かり易いです。
この点は「頻度論」の95%信頼区間の方が分かり易いです。
#統計
scholar.google.com/scholar?cluste…
Andrew Gelman and Cosma Rohilla Shalizi
Philosophy and the practice of Bayesian statistics
2010
あちこちからダウンロードできますね。
scholar.google.com/scholar?cluste…
Andrew Gelman and Cosma Rohilla Shalizi
Philosophy and the practice of Bayesian statistics
2010
あちこちからダウンロードできますね。
#統計 資料
ベイズ統計に関しては半世紀程度時代遅れっぽい解説の方がスタンダード。
赤池弘次さんや渡辺澄夫さん的な考え方は無視されているように見える。
「主観的事前分布」「無情報事前分布」というような説明をしているだけで私はアウトだと感じる。
ベイズ統計に関しては半世紀程度時代遅れっぽい解説の方がスタンダード。
赤池弘次さんや渡辺澄夫さん的な考え方は無視されているように見える。
「主観的事前分布」「無情報事前分布」というような説明をしているだけで私はアウトだと感じる。
#統計 時代遅れなベイズ統計の考え方はこんな感じ。
1. ベイズの定理によって事前分布における信念の度合いが更新され、事後分布によって仮説が正しい確率を計算できる。
2. 主観を入れたくなければ無条件事前分布を使うべし。
3. 様々なベイズ推定量はリスク最小化によって合理的に正当化される。
1. ベイズの定理によって事前分布における信念の度合いが更新され、事後分布によって仮説が正しい確率を計算できる。
2. 主観を入れたくなければ無条件事前分布を使うべし。
3. 様々なベイズ推定量はリスク最小化によって合理的に正当化される。
#統計 Gelman-Shalizi (2010)は当時のウィキペディアにおける時代遅れのベイズ統計観をボコボコにしています。
ベイズ更新後に事後分布で仮説が正しい確率を計算して終わりにするには科学的に非常識で、普通は事後分布を求めた後にモデルのチェックを慎重に行う。
ベイズ更新後に事後分布で仮説が正しい確率を計算して終わりにするには科学的に非常識で、普通は事後分布を求めた後にモデルのチェックを慎重に行う。

#統計 おそらく、以下のリンク先の1,2,3の考え方を「時代遅れ」と批判しても、ベイズ統計について教科書で勉強した人達の大部分は「普通の標準的な考え方なのにどうして批判されなければいけないのだろうか?」と感じると思う。
下手をすれば「専門家」の間でもそうかもしれない。
下手をすれば「専門家」の間でもそうかもしれない。
#統計 「ベイズ推定量」を特徴付ける条件は、事前分布φ(w)と確率モデルp(x|w)で作られる分布
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に関するリスク(←別に決めておく)の期待値の最小化です。
どこにも推定先の未知の(真の)確率分布は出て来ない!
モデル内の非現実的設定でのリスク最小化。
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に関するリスク(←別に決めておく)の期待値の最小化です。
どこにも推定先の未知の(真の)確率分布は出て来ない!
モデル内の非現実的設定でのリスク最小化。
#統計 しかも例として出て来るのは、分布の平均が平均二乗誤差最小化で特徴付けられるというベイズ統計と無関係の超一般論の特殊な場合だったりする。条件付き確率分布にも一般的なその手の特徴付けがあって、ベイズ予測分布の特徴付けはその特殊な場合に過ぎない。
そういうつまらない話をよく見る。
そういうつまらない話をよく見る。
#統計 Z(x_1,…,x_n)はベイズ統計で使うモデル内部における標本分布。モデル内部でサンプル(データ)X_1,…,X_nが生成されたとき、そのデータに応じて〇〇することのリスクの期待値を最小にするというようなことを考える。
現実世界とは縁が切れた純粋にモデル内部における議論でしかない。
現実世界とは縁が切れた純粋にモデル内部における議論でしかない。
#統計 「ベイズ推定量」の平均リスク最小化による特徴付けが、数学的にはtrivialでつまらないだけではなく、現実世界とは縁が切れたモデル内部の非現実的な仮想世界内における平均リスク最小化に過ぎないことも十分に認識されているかどうか、極めて疑わしいです。
#統計 訂正
❌無条件事前分布
⭕️無情報事前分布
ベイズ統計のユーザーは自分が採用した事前分布を「主観的事前分布」「無情報事前分布」に主観的に分類して満足せずに、採用した事前分布を使った推定・推測・推論の性質を確認した方が無難かも。
❌無条件事前分布
⭕️無情報事前分布
ベイズ統計のユーザーは自分が採用した事前分布を「主観的事前分布」「無情報事前分布」に主観的に分類して満足せずに、採用した事前分布を使った推定・推測・推論の性質を確認した方が無難かも。
#統計 「歪んだコインを投げて表と裏のどちらが出るか」のモデル化のベルヌイ分布モデルは表の出る確率wをパラメータとして持つのですが、予測分布が最尤法と一致するような事前分布は全積分を1にできない所謂improper priorになります。1/(w(1-w))を0近傍または1近傍で積分すると発散する。続く
#統計 別の言い方。歪んだコインをn回投げたらk回表が出たときに、最尤法では表の出る確率wはk/nと推定します(自然で分かり易い)。同じ結果をベイズ予測分布で得るためには、事前分布を1/(w(1-w))の定数倍にする必要があるのですが、積分が発散するので定数倍して全積分を1にできません。
#統計 ベイズ統計でも表の出る確率の推定値がk/nになるような事前分布を主観が入らない「無情報事前分布」だと思いたい人は、0と1の両端で発散し、積分も発散するような 1/(w(1-w)) が「無情報事前分布」だと思わなければいけないのです。
#統計 しかし、何も知らないと、0から1の間の一様分布を「無情報事前分布」だと思う人の方が多いのでは?
さらに、「無情報事前分布」にはJeffreys事前分布(1(w(1-w))と一様分布のちょうど中間に位置する事前分布)という有力な選択肢があります。
さらに、「無情報事前分布」にはJeffreys事前分布(1(w(1-w))と一様分布のちょうど中間に位置する事前分布)という有力な選択肢があります。
#統計 個人的な意見では「主観が入らないように無情報事前分布を選ぶ」という発想自体が不毛でかつ時間の無駄。
そうではなく、事前分布もモデルの立派な一部分であり、採用した事前分布によってモデル全体がどのような性質を持つことになるかを理解しておく方が重要。目的によって使い分ければよい。
そうではなく、事前分布もモデルの立派な一部分であり、採用した事前分布によってモデル全体がどのような性質を持つことになるかを理解しておく方が重要。目的によって使い分ければよい。
#統計 例えば、自分の使用目的には、事前分布1と事前分布2のどちらでも無視できる違いしか生じないことが前もって分かっているなら、どちらを選ぶかについて悩む必要はなくなります。
しかし、結果に無視できない違いが生じる可能性があるなら、目的に応じてどちらが優れているかを考える必要がある。
しかし、結果に無視できない違いが生じる可能性があるなら、目的に応じてどちらが優れているかを考える必要がある。
#統計 時代遅れの「事前分布は主観や信念を表す」というような考え方を捨てて、「目的ごとに自分で使う道具を適切に選ぶ」という基本原則に戻ればよい。
「無情報事前分布vs.主観的事前分布」という「頻度論vs.ベイズ」という非科学的な発想のサブセットを捨てるべきだと思います。
「無情報事前分布vs.主観的事前分布」という「頻度論vs.ベイズ」という非科学的な発想のサブセットを捨てるべきだと思います。
このスレッドだけで本1冊分くらいの分量がありそうだな。
#統計 モデルの一部分に過ぎない事前分布だけについて特に主観的か否かを問題にしている時点で「こいつダメだな」と判断して問題ないと思う。
#統計 事前分布だけが主観的だと感じるダメな感覚ができあがる背後には、仮説検定や区間推定が確率モデルの選び方に強く依存していることを正直に強調しない統計学教育の問題があると思います。
検定や信頼区間で正規分布モデルを安易に前提にする行為は「非科学的だ」という意味で主観的。
検定や信頼区間で正規分布モデルを安易に前提にする行為は「非科学的だ」という意味で主観的。
#統計 はなだてさん、どうもありがとうございます。
実際の「米国統計学会の統計的有意性とP値に関する声明」の実質的内容は「P値入門」になっていて、それを読めばP値の概念をより正確につかめ、誤用する心配もなくなる類のものですよね。
ベイズ云々と無関係にこういうことは大事だと思う。続く
実際の「米国統計学会の統計的有意性とP値に関する声明」の実質的内容は「P値入門」になっていて、それを読めばP値の概念をより正確につかめ、誤用する心配もなくなる類のものですよね。
ベイズ云々と無関係にこういうことは大事だと思う。続く
#統計 「米国統計学会の統計的有意性とP値に関する声明」の日本語訳が
biometrics.gr.jp/news/all/ASA.p…
にあります。
検定について教えなければならなくなった人にとってこれは非常にありがたい翻訳だと思いました。
biometrics.gr.jp/news/all/ASA.p…
にあります。
検定について教えなければならなくなった人にとってこれは非常にありがたい翻訳だと思いました。
#統計 仮説検定でずるをした方が有利な環境があるなら、環境の側を改善するべきだと思う。
仮説検定自体はシンプルな数学的道具の1つに過ぎず、仮説検定自体に罪はない。
仮説検定を別の何かに置き換えても、ずるをした方が有利な状況がそのままなら、ずるをする人達が必ず出て来ると思う。
仮説検定自体はシンプルな数学的道具の1つに過ぎず、仮説検定自体に罪はない。
仮説検定を別の何かに置き換えても、ずるをした方が有利な状況がそのままなら、ずるをする人達が必ず出て来ると思う。
#統計 階層モデル(表に出て来ない変数で内部で積分されるものを含む確率モデル)は、確率モデルp(x|w)のベイズ統計においては、パラメータwの事前分布にさらにパラメータzが入っていて、事前分布がφ(w|z)の形のときに、パラメータzについても事前分布ψ(z)を設定するモデルを考えれば自然に出て来ます。
#統計 続き。その場合の階層モデルの確率モデルは
r(x|z) = ∫p(x|w)φ(w|z) dw
と積分で表されることになり、表に出ているパラメータzの事前分布としてψ(z)が採用されている場合になります。
r(x|z) = ∫p(x|w)φ(w|z) dw
と積分で表されることになり、表に出ているパラメータzの事前分布としてψ(z)が採用されている場合になります。
#統計 以前どこかで「階層ベイズでは渡辺澄夫さんのベイズ本に書いてある漸近論は使えない」というような__ひどい誤解__を見たことがあるような気がします。ひどい誤解なのでそういう主張を見つけた人は要注意。
その手の誤解はStanでモデルを書くときに生じる可能性があると思う。続く
その手の誤解はStanでモデルを書くときに生じる可能性があると思う。続く
#統計 サンプルのサイズがnの場合には
(1) Zが分布ψ(z)に従ってランダムに生成される。
(2) k=1,…,nについて、W_k が分布 φ(w_k|Z) に従ってランダムに生成される。
(3) k=1,…,nについて、X_kが分布 p(x_k|W_k) に従ってランダムに生成される。
Stanなどではこれを素直にコード化できる。続く
(1) Zが分布ψ(z)に従ってランダムに生成される。
(2) k=1,…,nについて、W_k が分布 φ(w_k|Z) に従ってランダムに生成される。
(3) k=1,…,nについて、X_kが分布 p(x_k|W_k) に従ってランダムに生成される。
Stanなどではこれを素直にコード化できる。続く
#統計 このとき、nが大きくなると、パラメータw_kの個数のnも増えて行くので、「階層ベイズでは渡辺澄夫さんの本に書いてある漸近論を使えない」という__ひどい誤解__が生じる危険性があると思う。
これがひどい誤解である理由は w_k はモデル内部で積分されて消えることを見逃しているからです。続く
これがひどい誤解である理由は w_k はモデル内部で積分されて消えることを見逃しているからです。続く
#統計 モデル内部におけるサンプルX_1,…,X_nの生成のされ方は、積分表示された確率モデル
r(x|z) = ∫p(x|w)φ(w|z) dw
を使うと、
(1) Z が分布ψ(z)に従ってランダムに生成される。
(2) 必要なくなる。
(3) k=1,…,nについて、X_kが分布r(x_k|Z)に従ってランダムに生成される。
と書き直される。
r(x|z) = ∫p(x|w)φ(w|z) dw
を使うと、
(1) Z が分布ψ(z)に従ってランダムに生成される。
(2) 必要なくなる。
(3) k=1,…,nについて、X_kが分布r(x_k|Z)に従ってランダムに生成される。
と書き直される。
#統計 この書き直した側では w_k 達は積分されて消えて見えなくなっており、渡辺澄夫さんのベイズ本の設定に戻る。
「だったら、最初からw_kを消して、階層ベイズとか言わなければいいのに」と思う人がいるかもしれませんが、モデルを数値的に解くためには「階層ベイズ」という見方が有効なのです。
「だったら、最初からw_kを消して、階層ベイズとか言わなければいいのに」と思う人がいるかもしれませんが、モデルを数値的に解くためには「階層ベイズ」という見方が有効なのです。
#統計 階層ベイズの確率モデルは
r(x|z)=∫p(x|w)φ(w|z)dw
と積分表示されているので、モデルを直接的に数値的に解くためには、この積分を数値的に求める必要が生じます。
r(x|z) が初等函数や有名な特殊函数で書けるなら、r(x|z)のコンピュータでの計算は易しくなります。
一般にはそうではない!
r(x|z)=∫p(x|w)φ(w|z)dw
と積分表示されているので、モデルを直接的に数値的に解くためには、この積分を数値的に求める必要が生じます。
r(x|z) が初等函数や有名な特殊函数で書けるなら、r(x|z)のコンピュータでの計算は易しくなります。
一般にはそうではない!
#統計 もしも r(x|z) を数値積分で求めなければいけないとすると、尤度 r(X_1|z)…r(X_n|z) を計算するたびにn回数値積分が実行されてしまうことになります。数値積分は重い計算なので、実際にそれをやると、容易に、実用的な時間内で計算が終わらなくなります。
#統計 そうするのではなく、以下のリンク先の形式(階層モデルのスタイル)でモデル内でのサンプル生成法を記述して、そのスタイルを用いてコンピューターで事後分布のサンプルを作ることであれば、実用的な時間内で比較的容易に実行できる場合が多数あるのです。
#統計 まとめ: 確率モデルr(x|z)が
r(x|z) = ∫p(x|w)φ(w|z)dw
と書けているとき、
(i) r(x|z)をコンピューターで楽に計算できるなら、w_k達を持ち出さずに数値的にモデルを解ける。
(ii) そうでなくても、階層モデルのスタイルでMCMC法を使えば事後分布のサンプルを作れる。
続く
r(x|z) = ∫p(x|w)φ(w|z)dw
と書けているとき、
(i) r(x|z)をコンピューターで楽に計算できるなら、w_k達を持ち出さずに数値的にモデルを解ける。
(ii) そうでなくても、階層モデルのスタイルでMCMC法を使えば事後分布のサンプルを作れる。
続く
#統計 続き。同等のことを最尤法やMAP法でやろうとすると、(ii)の方法が使えないので面倒なことになります。モデルを数値的に解くときに、ベイズ法の場合の方が道具が揃っていて、ライトユーザーが楽に参入できるということがあるのです。
ベイズ統計にはこのようなテクニカルなメリットがある。
ベイズ統計にはこのようなテクニカルなメリットがある。
#統計 せっかくなので、
(A) 事前分布 φ(w), 確率モデル p(x|w)
(B) 事前分布 ψ(z), 確率モデル r(x|z) = ∫p(x|w)φ(w|z)dw
の違いと関係についても説明しておきましょう。
(B)の場合については既に詳しく説明したので、(A)のモデル内でのサンプルX_kの生成の仕方を説明します。続く
(A) 事前分布 φ(w), 確率モデル p(x|w)
(B) 事前分布 ψ(z), 確率モデル r(x|z) = ∫p(x|w)φ(w|z)dw
の違いと関係についても説明しておきましょう。
(B)の場合については既に詳しく説明したので、(A)のモデル内でのサンプルX_kの生成の仕方を説明します。続く
#統計 (A)の場合にモデル内でサンプルX_kは以下のように生成されていると考える。
(1) Wが分布φ(w)に従ってランダムに生成される。
(2) k=1,…,nについて、X_kが分布p(x_k|W)に従ってランダムに生成される。
これと以下のリンク先の(B)の場合の注目するべき違いはWとW_kの違いです。続く
(1) Wが分布φ(w)に従ってランダムに生成される。
(2) k=1,…,nについて、X_kが分布p(x_k|W)に従ってランダムに生成される。
これと以下のリンク先の(B)の場合の注目するべき違いはWとW_kの違いです。続く
#統計 (A)の場合には、X_k達は同一のパラメータ値Wで決まる確率分布p(x_k|W)で生成されます。
それに対して、階層モデルの(B)の場合に、X_k達は(一般には)互いに異なるパラメータ値W_kで決まる分布p(x_k|W_k)で生成されます。
(A)と(B)の違いは、(B)では各kが異なる「個性」を持つことだと言える。
それに対して、階層モデルの(B)の場合に、X_k達は(一般には)互いに異なるパラメータ値W_kで決まる分布p(x_k|W_k)で生成されます。
(A)と(B)の違いは、(B)では各kが異なる「個性」を持つことだと言える。
#統計 例えば、科学者1,…,nによる物理的に同じ量の測定結果の数値がデータX_1,…,X_nとして得られているとします。
このとき、すべての科学者の測定技術が同等で同じ程度の誤差で測定できるという想定でモデルを作ると(A)型になります。
科学者ごとに測定技術に違いがあると想定すると(B)になる。
このとき、すべての科学者の測定技術が同等で同じ程度の誤差で測定できるという想定でモデルを作ると(A)型になります。
科学者ごとに測定技術に違いがあると想定すると(B)になる。
#統計 測定技術には個人差がありそうだという想定でモデルを作って統計分析したい人は(B)型のモデルを数値的に解かなければいけなくなります。
その場合には、r(x|z)を直接コンピュータで計算できるようにモデル化することもできるだろうし、階層ベイズ化してMCMCをぶん回す方法も使える。
その場合には、r(x|z)を直接コンピュータで計算できるようにモデル化することもできるだろうし、階層ベイズ化してMCMCをぶん回す方法も使える。
#統計 そして、再度、誤解をし易い部分だと思うので強調しておきますが、「個性」を考えると、サンプルサイズnを増やすごとにモデルのパラメータw_kが増えるので、渡辺澄夫さんのベイズ本にある漸近論は使えない、のように考えることは__ひどい誤解__になるので注意した方が良いです。
#統計 #Julia言語 補足: 私が
nbviewer.jupyter.org/github/genkuro…
で解説し、数値例を作ったStein推定では、n個の別々の期待値を持つ分散1の正規分布でX_1,…,X_nが生成されると想定しているので、「個性」を考える(B)の話に関係しており、この場合も渡辺澄夫さんのベイズ本の範囲内の話題になります。
nbviewer.jupyter.org/github/genkuro…
で解説し、数値例を作ったStein推定では、n個の別々の期待値を持つ分散1の正規分布でX_1,…,X_nが生成されると想定しているので、「個性」を考える(B)の話に関係しており、この場合も渡辺澄夫さんのベイズ本の範囲内の話題になります。
#統計 #Julia言語
nbviewer.jupyter.org/gist/genkuroki…
測定スキルの異なる7人の科学者たち
このノートではまさに以下のリンク先の問題の練習問題を扱っています。(B)でr(x|w)の積分後の結果が分かっている場合なので、ベイズ法ではなく、最尤法を使いました(へそ曲がり(笑))。AICとLOOCVも計算しています。
nbviewer.jupyter.org/gist/genkuroki…
測定スキルの異なる7人の科学者たち
このノートではまさに以下のリンク先の問題の練習問題を扱っています。(B)でr(x|w)の積分後の結果が分かっている場合なので、ベイズ法ではなく、最尤法を使いました(へそ曲がり(笑))。AICとLOOCVも計算しています。
#統計 #Julia言語 最尤法版の
nbviewer.jupyter.org/gist/genkuroki…
測定スキルの異なる7人の科学者たち
のベイズ統計版のノート(計算&プロット)を作れば勉強になると思います。WAICやLOOCVも計算する。
さらに(B)で(ii)の方法も使ってみて、(i)の結果と比較して一致することを確認するとよいと思う。
nbviewer.jupyter.org/gist/genkuroki…
測定スキルの異なる7人の科学者たち
のベイズ統計版のノート(計算&プロット)を作れば勉強になると思います。WAICやLOOCVも計算する。
さらに(B)で(ii)の方法も使ってみて、(i)の結果と比較して一致することを確認するとよいと思う。
#統計 訂正
❌1(w(1-w))
⭕️1/(w(1-w))
パラメータ0≦w≦1のベルヌイ分布モデルの共役事前分布は
w^{a-1} (1-w)^{b-1}
の形。定数倍部分は本質的でないので省略。
a=b=0の場合の、両端のw=0,1に分布の集中度が最も高い場合の事前分布が最尤法に対応しています。続く
❌1(w(1-w))
⭕️1/(w(1-w))
パラメータ0≦w≦1のベルヌイ分布モデルの共役事前分布は
w^{a-1} (1-w)^{b-1}
の形。定数倍部分は本質的でないので省略。
a=b=0の場合の、両端のw=0,1に分布の集中度が最も高い場合の事前分布が最尤法に対応しています。続く
#統計 n回中k回表が出たとき、表の出る確率はk/nだと推定するのが最尤法の場合で、ベイズ統計の予測分布をそれと一致させるためには、大雑把に言って事前分布を「表の出る確率はほぼ0または1に非常に近く、それ以外の可能性は小さい」とする必要があるのです。続く
#統計 だから、事前分布を「表の出る確率は0から1のあいだの値のどれでも平等にあり得る」(a=b=1、一様分布)にした場合には、最尤法と比較すると、両端の0,1近くの予測誤差が増えて、それ以外では予測誤差が下がることになります。
Jeffreys事前分布(a=b=1/2)では、以上の2つの場合の中間になる。続く
Jeffreys事前分布(a=b=1/2)では、以上の2つの場合の中間になる。続く
#統計 #Julia言語 添付画像は
nbviewer.jupyter.org/gist/genkuroki…
より。平均予測誤差(KL情報量の平均)と平均二乗誤差のプロット。サンプルサイズがn=10,20,50の場合。MLEは最尤法、Bayes(0.5,0.5)がJeffreys事前分布、Bayes(1.0,1.0)が一様事前分布の場合。
1つ前のツイートで説明した通りになっています。
nbviewer.jupyter.org/gist/genkuroki…
より。平均予測誤差(KL情報量の平均)と平均二乗誤差のプロット。サンプルサイズがn=10,20,50の場合。MLEは最尤法、Bayes(0.5,0.5)がJeffreys事前分布、Bayes(1.0,1.0)が一様事前分布の場合。
1つ前のツイートで説明した通りになっています。
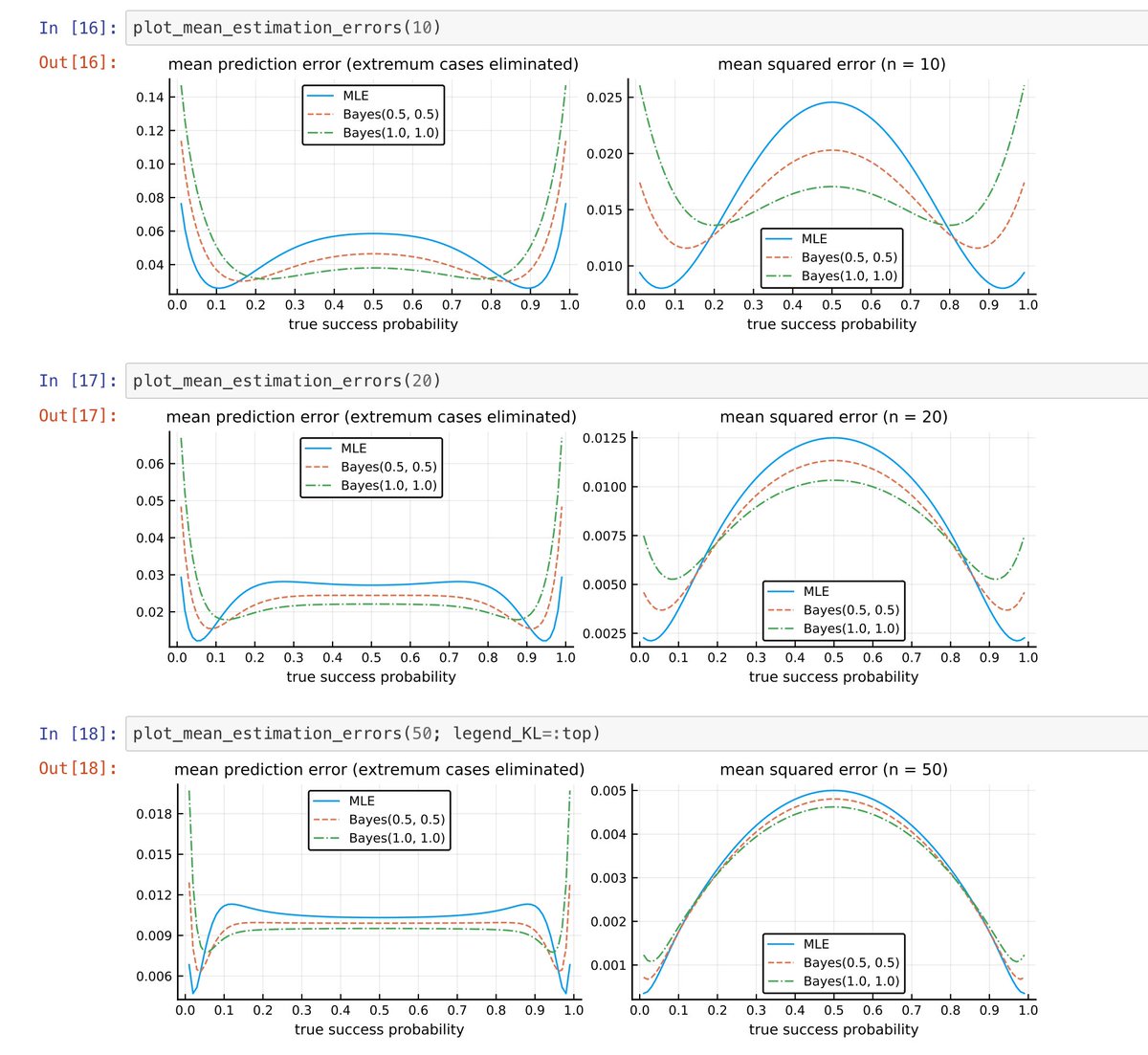
#統計 こんな感じで、平均予測誤差がどうなるかを見れば、複数の事前分布を客観的な指標で比較できる。
そういう計算を実際にしてみて、百聞は一見に如かずの精神で、観察を積み重ねれば様子がわかる。
こういう考え方は「事前分布は主観を表現している」という発想にこだわると出て来なくなる。
そういう計算を実際にしてみて、百聞は一見に如かずの精神で、観察を積み重ねれば様子がわかる。
こういう考え方は「事前分布は主観を表現している」という発想にこだわると出て来なくなる。
#統計 それ、いい質問!😊
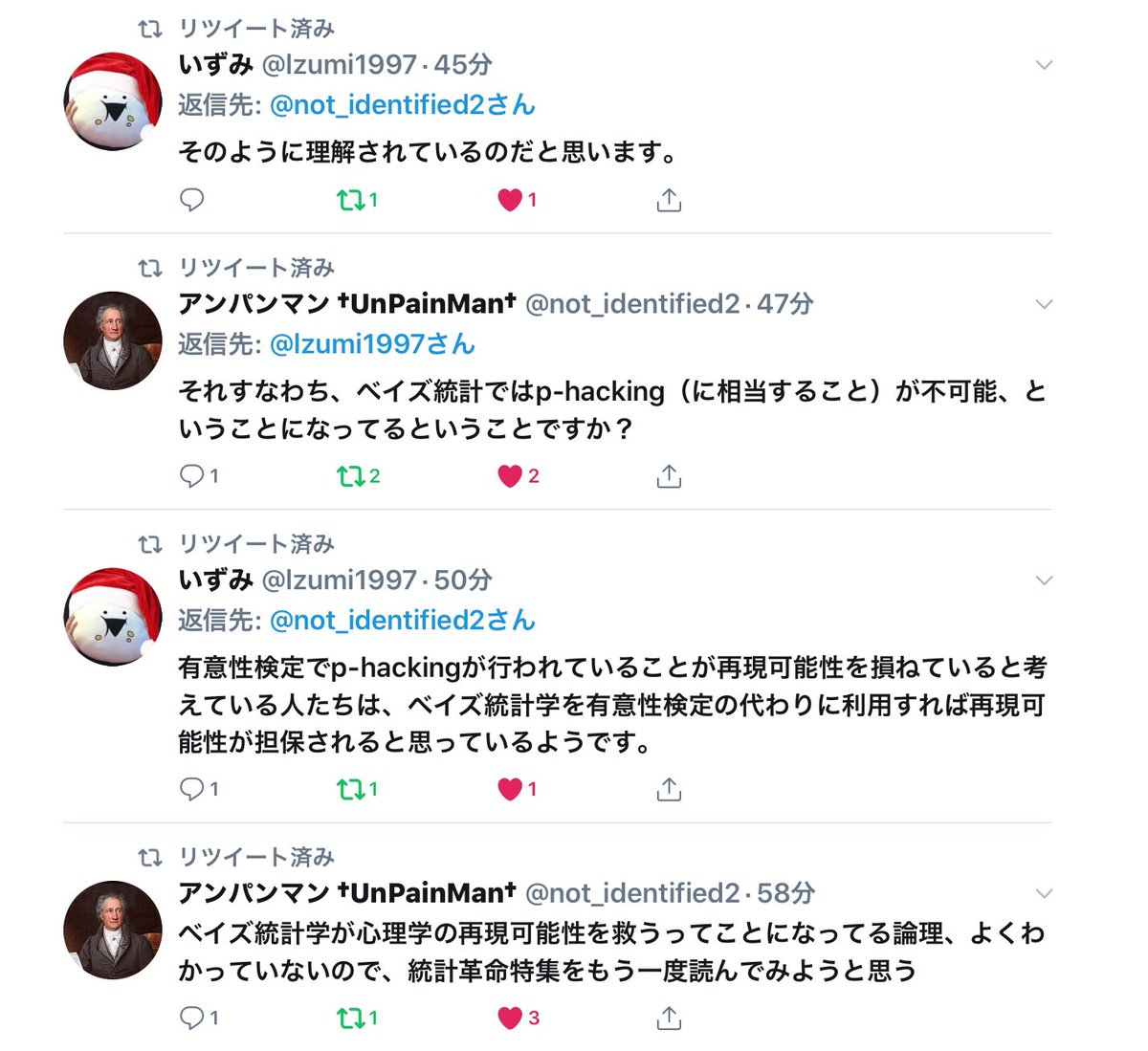
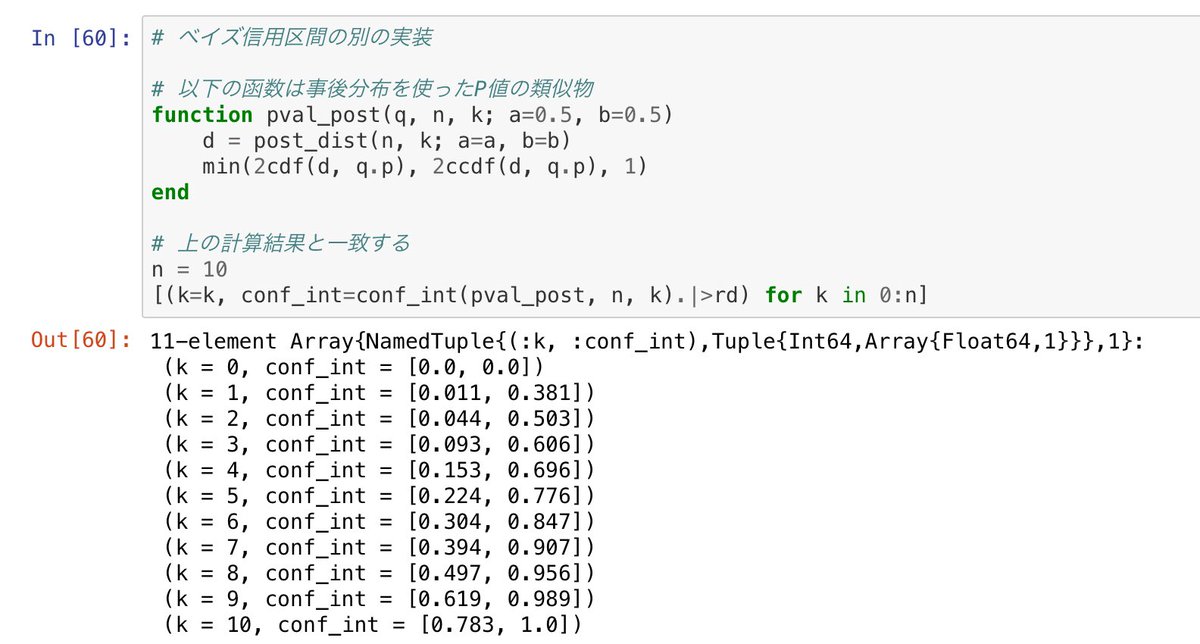
#統計 歪んだコインを投げてn回中k回表が出たときに、二項分布モデルでの帰無仮説をp=0~1(横軸)としたときのP値。
Normal→二項分布の正規分布近似で定義したP値
Posterior→ベイズ統計の事後分布に関するP値の類似物
2つの線の一致は「頻度論」信頼区間と「ベイズ」信用区間の一致を意味する。
Normal→二項分布の正規分布近似で定義したP値
Posterior→ベイズ統計の事後分布に関するP値の類似物
2つの線の一致は「頻度論」信頼区間と「ベイズ」信用区間の一致を意味する。
#統計 1つ前のツイートに添付した動画を見れば分かるように、例えばベルヌイ分布モデル(二項分布モデル)の場合には、
「頻度論」でのP値信頼区間
と
「ベイズ」でのP値の類似物と信用区間
はよく一致しています。
「頻度論」でp-hacking可能ならば「ベイズ」でも全く同じ方法で可能です。
「頻度論」でのP値信頼区間
と
「ベイズ」でのP値の類似物と信用区間
はよく一致しています。
「頻度論」でp-hacking可能ならば「ベイズ」でも全く同じ方法で可能です。
#統計 所謂情報量基準を使ったモデル選択でもいくらでもずるをできます。
ずるをした側が得をする環境では、ずるをするやつは必ず出て来ると思う。
そして、嘘がばれ難くするには、嘘をついた人自身も嘘をついていないと信じていた方がよい。
ああ、いやだ、いやだ。
ずるをした側が得をする環境では、ずるをするやつは必ず出て来ると思う。
そして、嘘がばれ難くするには、嘘をついた人自身も嘘をついていないと信じていた方がよい。
ああ、いやだ、いやだ。
#統計 なるほど、これはおもろいな。
What’s wrong with Bayes « Statistical Modeling, Causal Inference, and Social Science statmodeling.stat.columbia.edu/2019/12/03/wha…
What’s wrong with Bayes « Statistical Modeling, Causal Inference, and Social Science statmodeling.stat.columbia.edu/2019/12/03/wha…
#統計 「ベイズ」という語の使用が流行している時期(今のこと)に教育を受けたせいで、「ベイズの定理」が素晴らしい定理だと誤解してしまった若い人達が、後に、「偽陽性云々についてはベイズの定理で理解するとよい」などと教えるようになって、被害者から加害者側にまわる危険性があると思う。
#統計
ベイズ統計に関するそれらの【とにかくわかりやすかった説明】は(厳密には具体的にどういう説明なのか特定する必要がありますが)、ことごとく間違っていたと判断する方が無難だと思いました。本当はすっきりしようがない話のはずなので。
「騙された!」と感じることは結構大事なことかも。
ベイズ統計に関するそれらの【とにかくわかりやすかった説明】は(厳密には具体的にどういう説明なのか特定する必要がありますが)、ことごとく間違っていたと判断する方が無難だと思いました。本当はすっきりしようがない話のはずなので。
「騙された!」と感じることは結構大事なことかも。
#統計 以下は2017年08月13日に投稿の記事だが、よく見る教科書的俗説を知るために便利な解説になっている。こういう解説を信じて他人に教えると、騙された被害者から、嘘を教える加害者になってしまう。
信頼区間を正しく理解してますか?
確信区間との違いって何ですか?
qiita.com/katsu1110/item…
信頼区間を正しく理解してますか?
確信区間との違いって何ですか?
qiita.com/katsu1110/item…
#統計 添付画像のこれのことかな?リンクをはりたいのですが、ブロックされています。
「ベイズ統計では仮説が正しい確率がわかる」
「頻度論の信頼区間より、ベイズ信用区間の方が解釈が容易で分かり易い」
の様なデタラメを学生に言えなくなるだけ「萎縮」してもらえたら、とてもうれしいです。😊
「ベイズ統計では仮説が正しい確率がわかる」
「頻度論の信頼区間より、ベイズ信用区間の方が解釈が容易で分かり易い」
の様なデタラメを学生に言えなくなるだけ「萎縮」してもらえたら、とてもうれしいです。😊

#統計 ただし、「ベイズ統計モデリング」と「WAIC, LOOCV, 自由エネルギー, BIC, WBICなどを使ったモデル選択」は原理的に、p-hackingなどが原因と思われる研究の再現性の危機の問題を解決__しない__と考えられます。
この点に関しては非常に要注意。
この点に関しては非常に要注意。
#統計 あびこ(牛)さんも紹介なさっていますが、
watanabe-www.math.dis.titech.ac.jp/users/fujiwara…
特異モデルにおけるベイズ検定と変化点発見への応用
藤原香織 渡辺澄夫
の話は「仮説検定とベイズ統計は水と油だ」のような印象論が__誤り__であることの証拠になっている。
間違った印象論を広めるような教育はまずい
watanabe-www.math.dis.titech.ac.jp/users/fujiwara…
特異モデルにおけるベイズ検定と変化点発見への応用
藤原香織 渡辺澄夫
の話は「仮説検定とベイズ統計は水と油だ」のような印象論が__誤り__であることの証拠になっている。
間違った印象論を広めるような教育はまずい
#統計
asakura.co.jp/books/isbn/978…
で公開されている豊田秀樹『瀕死の統計学を救え! 』のプロローグを見てみました(添付画像に引用)。
ひどかった。
ベムの超能力論文の話。まず的中率5割の帰無仮説のP値は1%と非常に低かったという話をしています。nは1000のオーダーであることがわかる。続く
asakura.co.jp/books/isbn/978…
で公開されている豊田秀樹『瀕死の統計学を救え! 』のプロローグを見てみました(添付画像に引用)。
ひどかった。
ベムの超能力論文の話。まず的中率5割の帰無仮説のP値は1%と非常に低かったという話をしています。nは1000のオーダーであることがわかる。続く



#統計 次に、P値は仮説が間違っている確率ではないことを強調し(それは正しい)、仮説が正しい確率は別の方法で計算できると言う。
そして、的中率が7割以上という仮説が正しい確率はほぼ0だと計算され、【「予知能力がない」という仮説が正しい確率は100%】と結論します。
色々ひどい。
そして、的中率が7割以上という仮説が正しい確率はほぼ0だと計算され、【「予知能力がない」という仮説が正しい確率は100%】と結論します。
色々ひどい。



#統計 仮説が正しい確率はおそらくベルヌイ分布モデルのベイズ統計の事後分布で計算した確率なのでしょう。実はその場合には適切な対応をつけるとと事後分布で計算した確率の値はP値にほぼ一致することを示せます。ベイズ統計を使っても大して意味がない場合。続く
#統計 nが1000のオーダーでデータ中の的中率が53%のとき、「的中率は7割以上である」という仮説のP値もほぼ0になります。プロローグ内での「予知能力がある」(的中率7割以上)という仮説が正しい確率は近似的にそのP値を計算したものとみなされます。
あれ?P値って仮説が正しい確率ではないですよね!
あれ?P値って仮説が正しい確率ではないですよね!



#統計 シンプルなベルヌイ分布モデルの場合には、所謂「頻度論」と「ベイズ」のあいだの違いは n=1000 のオーダーでは本質的にないと思って構いません。事後分布を使ってP値を近似的に求めることさえできる(笑)。
豊田秀樹さんはデタラメを書いていると思いました。
豊田秀樹さんはデタラメを書いていると思いました。



#統計 添付動画は、ベルヌイ分布モデルの場合に、二項分布の正規分布近似で作ったP値とベイズ法で得られる事後分布から作ったP値の類似物を同時にプロットしたものです。
それらはほとんど一致!
ベイズ統計を使えば所謂「頻度論」では出せなかった強い結論を出せるという考え方は完全に誤り。
それらはほとんど一致!
ベイズ統計を使えば所謂「頻度論」では出せなかった強い結論を出せるという考え方は完全に誤り。
#統計 #Julia言語 動画作成のためのソースファイルは
nbviewer.jupyter.org/gist/genkuroki…
で公開していています。
ベイズ統計のWAICから作ったP値の類似物もn=100で所謂「頻度論」のP値にほぼ一致していること
を示す動画もそちらにはあります(笑)。こういう動画作成は徹底した方が楽しい。
nbviewer.jupyter.org/gist/genkuroki…
で公開していています。
ベイズ統計のWAICから作ったP値の類似物もn=100で所謂「頻度論」のP値にほぼ一致していること
を示す動画もそちらにはあります(笑)。こういう動画作成は徹底した方が楽しい。
#統計 ベイズ統計のWAICからP値の類似物を作ると「頻度論」のP値にほぼ一致している場合があることを知れば、「頻度論」のP値ユーザーがベイズ統計のWAICを怖がる必要がないことも分かると思います。
「頻度論vs.ベイズ」的な発想自体が根本的に時代遅れで間違っているわけです。
「頻度論vs.ベイズ」的な発想自体が根本的に時代遅れで間違っているわけです。
#統計 注意: 正直な話をすると、WAICからP値の類似物を作ったのではなく、ベイズ統計の予測分布の対数尤度比からP値の類似物を作っています。添付動画のAIC版のP値も同様で最尤法の予測分布の対数尤度比から作っています。ベルヌイ分布モデルのn=100では全部ほぼ一致する。
シンプルなモデルの特徴。
シンプルなモデルの特徴。
#統計 清水裕士さんには議論の途中でブロックされたので見ないようにしていたのですが(現在もブロックされている)、
norimune.net/3339
「研究仮説が正しい確率」について
を見てみました。
論外にひどい内容だった。
分かり易い部分を添付画像に引用。
【頻度主義】とやらの意味が不明。
norimune.net/3339
「研究仮説が正しい確率」について
を見てみました。
論外にひどい内容だった。
分かり易い部分を添付画像に引用。
【頻度主義】とやらの意味が不明。

#統計 私が指摘した誤りを素直に認めるかのようなことも書いてありますが、ツイッター上では私をずっとブロックしているのも興味深いです。
そういう「こったこと」をやらずに、気持ち良く議論したいものだと思いました。
そういう「こったこと」をやらずに、気持ち良く議論したいものだと思いました。
#統計 清水裕士さん曰く【頻度主義の場合は=の仮説しか立てられません】はさすがにまずいです。多くに大学生は大学2年生あたりでの講義で「片側検定」についても教わっているはずです。
このスレッドでも少し上の方で「的中率が7割以上」という仮説の検定(片側検定になる)のP値を話題にしています。
このスレッドでも少し上の方で「的中率が7割以上」という仮説の検定(片側検定になる)のP値を話題にしています。

#統計 「的中率が7割以上」を帰無仮説としたときの片側検定のP値を求めることができないと、大学2年での統計の講義の単位を取れないと思う。
なるほど、こういうレベルで所謂「頻度主義」を理解したつもりになっているから、論外な議論もきっちり否定できないのかと思いました。
なるほど、こういうレベルで所謂「頻度主義」を理解したつもりになっているから、論外な議論もきっちり否定できないのかと思いました。
#統計 片側検定の考え方を理解していれば、それを一般化することによって「的中率は6割以上8割以下である」のような仮説の検定も行うことができるようになります。
#統計 あと、所謂「頻度主義」の結果とベイズ統計の事後分布から得た結果が一致する場合には(上でベルヌイ分布モデルの場合にそうなることを動画とソースコードの形式で示した)、ベイズで何をやっても所謂「頻度主義」を超える結果は決して得られません。
こういうことも多分知らないのではないか?
こういうことも多分知らないのではないか?
#統計 F主義で計算したxとB主義で計算したx'が近似的によく一致することがわかっている場合には、F主義による結論とB主義による結論を別にすることは、単なる主義の違いで結論を変えているに過ぎないので、そういう考え方をすることは非科学的あると断じておくべきだと私は思います。
警告: 私は統計学については経験の足りない単なるど素人に過ぎません。これ、ほんとの話。統計学におけるスタンダードな専門用語の多くを私は知りません。
上では酷評しましたが、清水裕士さんはとても有能で素晴らしい人であるとも思っています。むしろ、そうであるからこそ、周囲に信頼されている可能性が高いので、酷評する必要性を感じました。
清水さんが共著者の1人になっている『社会科学のためのベイズ統計モデリング』は良い本だと思います。
清水さんが共著者の1人になっている『社会科学のためのベイズ統計モデリング』は良い本だと思います。
#統計 特異モデルのベイズ統計をバリバリ使うということであれば「ベイズ統計でないと困るよね」という意見は強い説得力を持ちます。
特異モデルの場合に事後分布は単峰型にならず、非常に複雑な形にもなりえます。だから「パラメータの推定」という発想は有効ではなくなる。続く
特異モデルの場合に事後分布は単峰型にならず、非常に複雑な形にもなりえます。だから「パラメータの推定」という発想は有効ではなくなる。続く
#統計 続き。特異モデルのケースでは異なるパラメータに対応するモデル内分布がほぼ同じになることがあります。
一方、事後分布が単峰型になる場合には、所謂「頻度主義」の最尤法や信頼区間とベイズ統計はほぼ同じ結果を出します。所謂「頻度主義」を真に超えたことをベイズではできなくなる。続く
一方、事後分布が単峰型になる場合には、所謂「頻度主義」の最尤法や信頼区間とベイズ統計はほぼ同じ結果を出します。所謂「頻度主義」を真に超えたことをベイズではできなくなる。続く
#統計 続き。「頻度主義ではなく、ベイズ統計では仮説が正しい確率を計算できる」などと言っている人達は、所謂「頻度主義」を真に超えたことをできないはずのケースを例に出してそう言っているんです。
これ、やっぱり、相当にひどい話だと思いました。
これ、やっぱり、相当にひどい話だと思いました。
#統計 補足: 所謂「頻度主義」を真に超えることをベイズ統計で原理的にはできない場合であっても、ベイズ統計のモデルを近似的に解く技術が便利なのでベイズ統計の使用の方が優位な場合が結構あります。
本質的に同じ結果が得られるなら楽な方がよい。
本質的に同じ結果が得られるなら楽な方がよい。
#統計 これは!さっそくダウンロードして最初の頃は方を見てみました。
github.com/kosugitti/psyc…
「はじめに」(添付画像)に
【母数を知るための推測 大学での統計,心理統計は~母集団を表す数字を求めるための推測統計である。】
と書いてあって、「ああ!またか!」と思いました。
github.com/kosugitti/psyc…
「はじめに」(添付画像)に
【母数を知るための推測 大学での統計,心理統計は~母集団を表す数字を求めるための推測統計である。】
と書いてあって、「ああ!またか!」と思いました。

#統計 統計学入門の文脈におけるパラメータの推定は
現実の未知の母集団から得たサンプルを使って、モデルのパラメータ(現実の未知の母集団をあらわす数字ではなく、モデルを表す数字)を推定すること
を意味し、モデルの妥当性が不明な場合には、その推定結果の妥当性も不明になります(当たり前)。
現実の未知の母集団から得たサンプルを使って、モデルのパラメータ(現実の未知の母集団をあらわす数字ではなく、モデルを表す数字)を推定すること
を意味し、モデルの妥当性が不明な場合には、その推定結果の妥当性も不明になります(当たり前)。
#統計 例えば単純な二項分布モデルを使ったパラメータの推定では、「個人差がほぼない」「無作為抽出がほぼ理想的に行なわれている」(確率論的な独立性を近似的に仮定できる)などを前提にしており、その前提が崩れれば推定結果の妥当性も失われます。
こういう当たり前のことが大事だと思う。
こういう当たり前のことが大事だと思う。
#統計
初学者を混乱させる説明の仕方
↓
母集団分布は正規分布であると仮定する。
正直かつより正確な説明の仕方
↓
未知の母集団分布について推定・推測するために正規分布モデルを利用する。母集団分布とモデルの正規分布を混同しないように注意して欲しい。
初学者を混乱させる説明の仕方
↓
母集団分布は正規分布であると仮定する。
正直かつより正確な説明の仕方
↓
未知の母集団分布について推定・推測するために正規分布モデルを利用する。母集団分布とモデルの正規分布を混同しないように注意して欲しい。
#統計 さらに次のように付け加えるべき。
母集団分布が未知である状況では、正規分布モデルを使った推定が妥当であるかどうかは不明になる。ゆえに、正規分布モデルを使った推定結果を客観的に信頼できると信じてはいけない。統計学は不良設定問題を扱うので、こういう点に注意し続ける必要がある。
母集団分布が未知である状況では、正規分布モデルを使った推定が妥当であるかどうかは不明になる。ゆえに、正規分布モデルを使った推定結果を客観的に信頼できると信じてはいけない。統計学は不良設定問題を扱うので、こういう点に注意し続ける必要がある。
#統計 統計学入門の教科書を読んだ人の多くは、区間推定や仮説検定の説明に
「母集団分布は正規分布であると仮定する」
と書いてあるのを見て、
えっ?正規分布だと仮定しちゃっていいの?
と思った人は多いと思う。当然そう思うべきで、思わなかった人は危ない状態に陥っている。
「母集団分布は正規分布であると仮定する」
と書いてあるのを見て、
えっ?正規分布だと仮定しちゃっていいの?
と思った人は多いと思う。当然そう思うべきで、思わなかった人は危ない状態に陥っている。
#統計 未知の母集団分布について勝手に正規分布を仮定してまともな議論をできるはずがない。
実際には、推定用の数学的モデルとして正規分布を使っているだけで、母集団分布は未知のままだと思ったままで推定作業を行うのです。サンプルの様子を見て正規分布モデルが妥当でないと分かることもある。
実際には、推定用の数学的モデルとして正規分布を使っているだけで、母集団分布は未知のままだと思ったままで推定作業を行うのです。サンプルの様子を見て正規分布モデルが妥当でないと分かることもある。
#統計 サンプルサイズが巨大でそのプロットが正規分布とよく一致しているように見えるなら、「母集団分布は正規分布でよく近似できている」という仮説の妥当性は高まりますが、そうであることが分かる前に勝手に「母集団分布は正規分布である」と仮定するのはナンセンスです。
#統計 あと、母集団分布が正規分布からずれていることがほぼ確実であっても、正規分布モデルを使った平均の区間推定が許容される誤差の範囲内で十分な妥当性を持つこともあります。(この点は色々微妙で難しい。中心極限定理という数学的法則がどれだけ効いてきているかが問題になる。)
#統計 いずれにせよ、学生時代に
「母集団分布は正規分布であると仮定する」
と書いてあるのを見て、
えっ?正規分布だと仮定しちゃっていいの?
と思わずに受け入れてしまった人は自分自身の洗脳を解く必要があります。そして学生時代に受けた統計学教育に疑問を持つべきだと思います。
「母集団分布は正規分布であると仮定する」
と書いてあるのを見て、
えっ?正規分布だと仮定しちゃっていいの?
と思わずに受け入れてしまった人は自分自身の洗脳を解く必要があります。そして学生時代に受けた統計学教育に疑問を持つべきだと思います。
#統計 「正規分布と仮定してよいのか?」という質問への
「統計分析は何らかの仮定がないと不可能である。ゆえにここでは母集団分布は正規分布であると仮定する」
という回答は
非科学的な詭弁
に過ぎない。そういう回答をして来た統計学教師は学生に集団に批判されるべきだと思います。
「統計分析は何らかの仮定がないと不可能である。ゆえにここでは母集団分布は正規分布であると仮定する」
という回答は
非科学的な詭弁
に過ぎない。そういう回答をして来た統計学教師は学生に集団に批判されるべきだと思います。
#統計 より適切な回答は
「教科書には確かにそう書いてあるが、実際には母集団分布が正規分布になっていると仮定したりしない。正規分布モデルの妥当性は常に疑われ続ける。分析の過程でサンプルおよび他の様々な情報によって正規分布モデルの使用の妥当性が崩れることもある」
だと思います。
「教科書には確かにそう書いてあるが、実際には母集団分布が正規分布になっていると仮定したりしない。正規分布モデルの妥当性は常に疑われ続ける。分析の過程でサンプルおよび他の様々な情報によって正規分布モデルの使用の妥当性が崩れることもある」
だと思います。
#統計 具体的には、正規分布モデルとt分布を用いた平均の信頼区間を求める方法がよく教科書に書いてありますが、それを読んで「頻度論の信頼区間は客観的に信用できる」と思っている人はひどく誤解しています。
正規分布モデルの妥当性を疑うことができない人には統計学を使って欲しくないです。
正規分布モデルの妥当性を疑うことができない人には統計学を使って欲しくないです。
#統計 添付画像は
github.com/kosugitti/psyc…
【心理学データ解析基礎1/2
担当:小杉考司
2020年2月20日】
より。一様事前分布の場合のベイズ推定値が最尤推定値に一致すると書いてあるが、ずさんな説明。正しくはベイズ統計とは異なるMAP法の推定値が一様事前分布のとき最尤法と一致するだけ。
github.com/kosugitti/psyc…
【心理学データ解析基礎1/2
担当:小杉考司
2020年2月20日】
より。一様事前分布の場合のベイズ推定値が最尤推定値に一致すると書いてあるが、ずさんな説明。正しくはベイズ統計とは異なるMAP法の推定値が一様事前分布のとき最尤法と一致するだけ。

#統計 続き。「確率分布の推定」ではなく、モデルと現実の混同を引き起こし易い「パラメータの推定」という発想に固執しているせいで、ベイズ統計と「事後分布の代表値を求めること」を同一視してしまっているように見える。例えば「MAP法などはベイズ統計ではない」という認識が全くないと思われる。

#統計 続き。脚注がすごい!
【モデルがそもそも間違っていればその推定値が正しい保証はない】
と書いてあるのに、その続きが、ゆえに心理学においても統計分析に用いたモデルの妥当性を常に疑い続ける、ではなく
【心理学の場合は~誤差に正規分布を仮定するものがほとんどである】
😱😱😱
【モデルがそもそも間違っていればその推定値が正しい保証はない】
と書いてあるのに、その続きが、ゆえに心理学においても統計分析に用いたモデルの妥当性を常に疑い続ける、ではなく
【心理学の場合は~誤差に正規分布を仮定するものがほとんどである】
😱😱😱

#統計 モデルが間違っていればその推定値が正しい保証はないという注意の続きが、ゆえにモデルの妥当性について慎重に検討することが必要になる、であれば普通の説明だと思うのですが、以上で引用した小杉考司氏のシラバスを見れば分かるようにそうなっていない点が非常に怖いと思いました。
#統計 いつのまにか、ブロックされていたのが解除されてフォローされていました。もちろんこういうのは大歓迎です。😊
#統計 引用したHashimotoさんの感想は典型的な誤解の1つかもしれない。
異なる分析ツールX,Yについて、ある場合にはX,Yを用いた結果がほぼ同じで、別のある場合には全然違うとしよう。
そのとき、X,Yの両方をBと呼ぶだけで終わるようでは、読者はX,Yの道具としての違いを認識できなくなります。続く
異なる分析ツールX,Yについて、ある場合にはX,Yを用いた結果がほぼ同じで、別のある場合には全然違うとしよう。
そのとき、X,Yの両方をBと呼ぶだけで終わるようでは、読者はX,Yの道具としての違いを認識できなくなります。続く
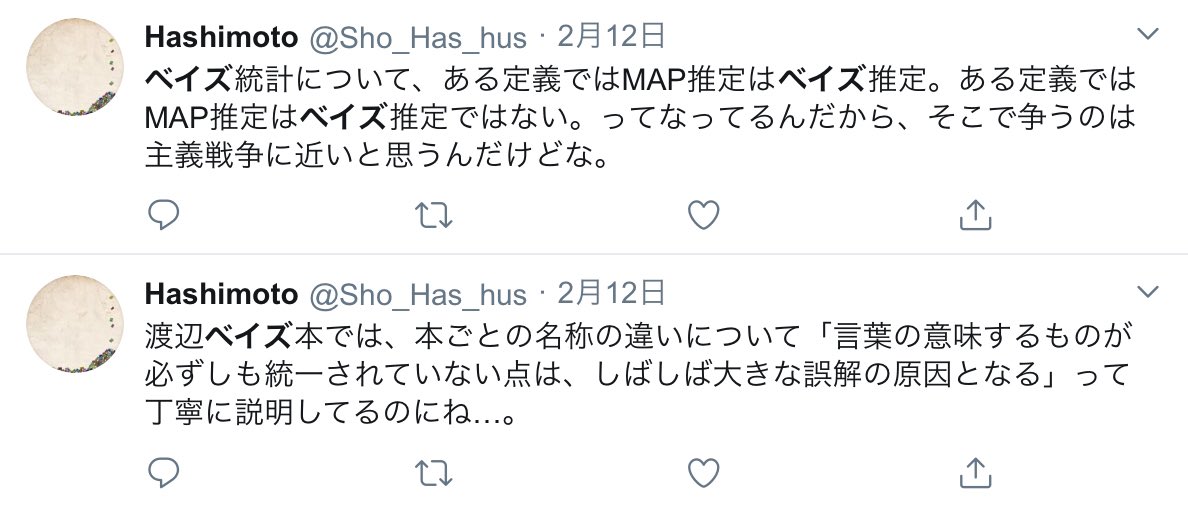
#統計 実際、事後分布の最頻値や平均値などを求めることをベイズ統計と呼び、それらとは異なる「予測分布として確率モデルを事後分布による平均で定義する方法」については満足な説明をしない。そして、それらがどのように異なる道具であるかについては何も触れない。続く
#統計 このスレッドの主題は「ある種の人達が、ベイズ統計では仮説が正しい確率を求められる」と主張していることでした。しかも、そういう人達が扱っているケースは、おとなしめの事前分布の場合には、通常の仮説検定や区間推定と事後分布を用いて得た数値がほぼ同じになるケースです。続く
#統計 続き。数学的に似たような数値が得られることがわかっているのに、事後分布を用いて計算した数値(彼らの言葉使いではそれが「ベイズ統計」で得られた数値)については、「研究仮説が正しい確率が求まった」というような強い主張ができるとしている。
続く
続く
#統計 「事後分布の代表値や事後分布から『仮説が正しい確率』を求めること」を特に「ベイズ統計」と呼ぶだけではなく、
* 異なる道具の区別を明瞭に説明しない。
* 「ベイズ統計」と名付けた途端に不可能だった強い主張をすることが可能になると説明する。
としていることが批判されているわけ。
* 異なる道具の区別を明瞭に説明しない。
* 「ベイズ統計」と名付けた途端に不可能だった強い主張をすることが可能になると説明する。
としていることが批判されているわけ。
#統計
「ベイズ統計」という用語の使い方が杜撰であること
や
そもそもまともに科学的な考え方をできていないんじゃないかという疑いがあること
を批判しているのであり、「ベイズ統計」と名付けることそのものを批判しているのではありません。
「ベイズ統計」という用語の使い方が杜撰であること
や
そもそもまともに科学的な考え方をできていないんじゃないかという疑いがあること
を批判しているのであり、「ベイズ統計」と名付けることそのものを批判しているのではありません。
#統計 このスレッドではめちゃくちゃ厳しい指摘を勇気をふりしぼってしているつもりなのに、単なる名付け方の問題だと受け取られるのは心外です。
私が、ベイズ云々だけにこだわっているのではなく、ベイズに限らない統計学入門のスタイルを批判していることを思い出して下さい。
私が、ベイズ云々だけにこだわっているのではなく、ベイズに限らない統計学入門のスタイルを批判していることを思い出して下さい。
#統計 ベイズ統計の道具としての性質は数学的に非自明です。その非自明な点を理解していないと、私による統計学入門の伝統的スタイルへの批判の一部分であるベイズ云々の話は理解できません。
だから、その辺についての説明も必要になりました。
その辺はかなり重たい作業になりました。続く
だから、その辺についての説明も必要になりました。
その辺はかなり重たい作業になりました。続く
#統計 以下のリンク先動画は、ベルヌーイ分布モデルでn=100の場合には、二項分布の正規分布近似によるP値とJeffreys事前分布のベイズ更新で得られる事後分布から作ったP値の類似物がほぼぴったり一致していることを示しています。(ゆえに通常の信頼区間とベイズ信用区間はその場合にはほぼ一致する。)
#統計 続き。その場合には、ベイズ側の事後分布で計算した「仮説が正しい確率」とほぼ同じ値の「頻度論」での対応物があり、「頻度論」側では「仮説が正しい確率」だと解釈してはいけないことになっています。続く
#統計 ほぼ同じになることがわかっている値について、「頻度論では『仮説が正しい確率』だと解釈するのは誤りだが、ベイズ統計であれば『仮説が正しい確率』だと解釈してよい」と主張することは、科学的には意味がありません。
少なくとも研究の再現性の問題はそれでは絶対に解決しない。
少なくとも研究の再現性の問題はそれでは絶対に解決しない。
#統計 以下のリンク先動画では、真の分布は{1,2,3,4,5,6}上の一様分布に近く、ほんの少しだけ3が出る確率が高い。確率モデル中の分布Bでは3,4の確率が非常に高く、一様分布からほど遠い。しかし、事後分布(posterior)で計算した「真の分布がBである確率」は100%に収束しています!
#統計 真の分布はBから程遠いにもかかわらず、ベイズ統計における事後分布で確率を計算すると「真の分布がBである確率は100%である」という結論が出てしまうことがあるのです。
この性質を説明せずに「ベイズ統計では仮説が正しい確率が分かる」などと解説するのはひどい。
この性質を説明せずに「ベイズ統計では仮説が正しい確率が分かる」などと解説するのはひどい。
#統計 補足: 事後分布は数学的モデル内部の仮想世界における確率分布に過ぎず、その外部(例えば現実世界)との直接的な関係はありません。
数学的モデル内部ではいくらでもナンセンスなことが起こり得るので、事後分布で計算した確率が有益な指標にならない場合があっても不思議でもなんでもない。
数学的モデル内部ではいくらでもナンセンスなことが起こり得るので、事後分布で計算した確率が有益な指標にならない場合があっても不思議でもなんでもない。
#統計 補足の補足: モデル内部の確率分布は、
その外部から得たデータと比較できるものの確率分布
と
その外部に比較対象がないものの確率分布
に分類されます。事前・事後分布は後者の分布であり、それそのものをデータと比較することは不可能なのです。間接的にその妥当性を調べるしかない。
その外部から得たデータと比較できるものの確率分布
と
その外部に比較対象がないものの確率分布
に分類されます。事前・事後分布は後者の分布であり、それそのものをデータと比較することは不可能なのです。間接的にその妥当性を調べるしかない。
#統計 事後分布のみに特に注目して、事後分布で測った確率を「仮説が正しい確率」のように安易に呼んでしまいことの危険性は、既出の以下のリンク先の動画を理解すればわかる。
確率モデルが大外ししていると、事後分布からミスリーディングな結論が得られてしまうのです。
確率モデルが大外ししていると、事後分布からミスリーディングな結論が得られてしまうのです。
#統計 以上のような諸々の事情を理解していれば、事後分布に特に注意を引きつけて、事後分布の代表値を求めたり、事後分布で「仮説が正しい確率」を求めることを、「ベイズ統計」と呼んで済ませることは、単なる名付け方の問題にはならず、極めて有害であることが分かると思います。
#統計 杜撰なベイズ統計の解説が多いことの原因は、ベイズ云々以前の基本的な事柄を理解していない人達が解説を書いていることが原因だと思っています。
特に、モデルと現実の区別が曖昧で、モデルの妥当性の吟味が必要であることを徹底的に強調しようとしない非科学的な態度が問題だと思います。
特に、モデルと現実の区別が曖昧で、モデルの妥当性の吟味が必要であることを徹底的に強調しようとしない非科学的な態度が問題だと思います。
#統計 そういう視点で統計学入門の教科書を見直すと、
母集団分布は正規分布であると仮定する
と書いてあることが多くて、
えっ?正規分布だと仮定していいのかよ?
という真当な疑問を蔑ろにするスタイルが標準的であることに気付くわけです。正規分布はモデル内確率分布に過ぎません。
母集団分布は正規分布であると仮定する
と書いてあることが多くて、
えっ?正規分布だと仮定していいのかよ?
という真当な疑問を蔑ろにするスタイルが標準的であることに気付くわけです。正規分布はモデル内確率分布に過ぎません。
#統計 私は名付け方を問題にしているのではなく、
ベイズ統計の名の下で
事後分布の代表値を求めることや
事後分布で『仮説が正しい確率』を求めること
を特に強調して済ませること
を批判しています。
もしもそういうスタイルが妥当であるとお考えならば、意見が正反対であることになります。
ベイズ統計の名の下で
事後分布の代表値を求めることや
事後分布で『仮説が正しい確率』を求めること
を特に強調して済ませること
を批判しています。
もしもそういうスタイルが妥当であるとお考えならば、意見が正反対であることになります。
#統計 注意: 「事前分布に尤度函数をかけて事後分布を作ること」という見方にこだわると、より基本的で一般的な「モデル内部の確率分布を外部から得たデータを用いて制限した条件付き確率分布を考える」という見方をできなくなるので注意が必要だと思います。この話も何度も繰り返しています。続く
#統計 注意続き: 尤度函数を事前分布にかけて確率の総和が1になるように正規化する手続きは、条件付き確率分布を作る手続きになっています。
ベイズの定理を形式的に適用すると、ベイズの定理よりも基本的な条件付き確率分布の概念が見えなくなります。続く
ベイズの定理を形式的に適用すると、ベイズの定理よりも基本的な条件付き確率分布の概念が見えなくなります。続く
#統計 注意続き: さらに大事なことは、モデル内部における確率分布を扱っていることの明瞭な認識です。モデル内部の様子と外部の様子の関係は別問題として扱う必要があります。
事前分布と尤度函数から事後分布を作る手続きを特に強調すると、この点が見えなくなりがちだと思います。
事前分布と尤度函数から事後分布を作る手続きを特に強調すると、この点が見えなくなりがちだと思います。
#統計
(1) 数学的モデルを使ってデータからの推定・推測・推論を行う。
(2) その妥当性を吟味する。
「事前分布と尤度函数から事後分布を作って、事後分布の代表値を求めたり、事後分布での確率を計算する」は(1)に属することで、(2)は別に行う必要があります。
(2)が難しくて重要な部分。
(1) 数学的モデルを使ってデータからの推定・推測・推論を行う。
(2) その妥当性を吟味する。
「事前分布と尤度函数から事後分布を作って、事後分布の代表値を求めたり、事後分布での確率を計算する」は(1)に属することで、(2)は別に行う必要があります。
(2)が難しくて重要な部分。
#統計 同じことを繰り返して言うより、新たな有益な情報を拡散する方が良さそうなので、最近見つけた面白そうな本を紹介します。
島谷健一郎著『ポアソン分布・ポアソン回帰・ポアソン過程』
統計スポットライト・シリーズ2、近代科学社、2017、iv+124頁
amazon.co.jp/dp/B076LVLLSF
島谷健一郎著『ポアソン分布・ポアソン回帰・ポアソン過程』
統計スポットライト・シリーズ2、近代科学社、2017、iv+124頁
amazon.co.jp/dp/B076LVLLSF


#統計 島谷「ポアソン³」本から引用(pp.115-116)
ポアソン過程モデルによる推定を詳しく解説した後で
【5.8 正解はなくてもモデルを創る
~そもそもこれらの樹種がポアソン過程に従って分布している可能性は皆無である~こうした影響を考慮したモデルを考案したり、その検証に有効なデータを~】
ポアソン過程モデルによる推定を詳しく解説した後で
【5.8 正解はなくてもモデルを創る
~そもそもこれらの樹種がポアソン過程に従って分布している可能性は皆無である~こうした影響を考慮したモデルを考案したり、その検証に有効なデータを~】


#統計 島谷「ポアソン³」本は、uniqueな本で以下を含んでいます。
* 離散分布の中で最も基本的な確率分布だと思われるポアソン分布についての易しい解説
* ポアソン分布モデルを例に使った最尤法入門
* ポアソン回帰を例に使ったAIC(所謂赤池情報量規準)入門
* 非定常ポアソン過程とその応用
* 離散分布の中で最も基本的な確率分布だと思われるポアソン分布についての易しい解説
* ポアソン分布モデルを例に使った最尤法入門
* ポアソン回帰を例に使ったAIC(所謂赤池情報量規準)入門
* 非定常ポアソン過程とその応用
#統計 続き。島谷「ポアソン3乗」本のpp.83-85では、カルバック・ライブラー情報量が真の分布との近さを測る尺度になっている理由(その本ではSanovの定理と呼んでいないが、Sanovの定理)についても説明されています。
そして、全編に渡って、真の分布が未知であることを強調した解説がされています。
そして、全編に渡って、真の分布が未知であることを強調した解説がされています。
#統計 島谷「ポアソン³」本ではコンピュータによる数値実験を自分で行うとよいことがあちこちで強調されています。
この本を読んで、実際に数値実験してみて、結果とソースコードを公開する人が出て来たり、そのベイズ版も試してみる人が出て来ると、さらに楽しくなりそうな本だと思いました。
この本を読んで、実際に数値実験してみて、結果とソースコードを公開する人が出て来たり、そのベイズ版も試してみる人が出て来ると、さらに楽しくなりそうな本だと思いました。
#統計 真の法則は未知であり、その推測のために用いた確率モデルの妥当性はそう簡単に分かることではなく、妥当性が不明の確率モデルを使って作った事後分布で測った確率が適切な指標になっていると考えることの妥当性も不明。
それなのに、その確率を「仮説が正しい確率」などと呼ぶのはまずい。
それなのに、その確率を「仮説が正しい確率」などと呼ぶのはまずい。
#統計 こういう当たり前の話をしているのに、困る人達がいるということ自体がおかしいのです。
上で紹介した島谷「ポアソン³」本は、当たり前であるべき話を「ポアソン尽くし」の本を書くことによって説明することを試みた本とみなせると思いました。
上で紹介した島谷「ポアソン³」本は、当たり前であるべき話を「ポアソン尽くし」の本を書くことによって説明することを試みた本とみなせると思いました。
#統計 違いの説明:「いんだよ、こまけえことは」のセンスで、尤度函数がサンプルサイズn→大で台の狭い単峰型になって行く場合には、最尤法、事後分布の最頻値を選ぶ(MAP法)、事後分布の平均を選ぶ(EAP法)、事後分布による確率モデルの平均を予測分布とする(ベイズ法)は、同じ結果になると思ってよい。
#統計 続き。事後分布の台が凸型になっていない場合には、事後分布に平均は事後分布の台の外に出てしまいます。そういう場合には事後分布の平均を推定値とするEAP法は極めて不適切な推定法になります。
#統計 続き。事後分布で測ったモデル内での平均二乗誤差を最小にする意思決定論の意味では適切な推定量は、事後分布の平均に一致するので、事後分布の台が凸型でない場合には極めて不適切な推定法になります。
意思決定論によるベイズ推定の説明は絶対に鵜呑みしてはいけません。
意思決定論によるベイズ推定の説明は絶対に鵜呑みしてはいけません。
#統計学 事後分布の最頻値を推定量とするMAP法は「正則化」「罰則項付き最適化」と同じなので、最尤法では起こるオーバーフィッティングが緩和されることがあります。
#統計 モデルが複雑で事後分布の形状が非常に複雑になる場合には、事後分布の平均や最頻値を代表値として選ぶ必然性がなくなり、予測分布として確率モデルの事後分布による平均を選ぶことが自然になり、収束性も保証し易くなります。
#統計 事後分布に代表値を選ぶことと、予測分布として何を選ぶかについては以上のように複数の選択肢があり、どれを選んでも「いんだよ、こまけえことは」のセンスで同じになる場合もあれば、その一部が他との比較で極めて不適切になる場合もあります。
#統計 こういう事情があるので、実際にベイズ統計を応用して使ってみたいと思っている人に「事前分布と尤度函数から事後分布を作ること」がベイズ統計だと教えることは好ましくなく、注意するべき点についてしっかり説明することが大事になるのです。
#統計 すべてについて詳細な説明が無理な場合には「安全牌」についてのみ重点的に説明してすませるのもありだと思います。
そして、安全牌は「事後分布による確率モデルの平均を予測分布とみなすこと」です。
事後分布の平均(EAP)を推定値として採用するのはとても危ない。
そして、安全牌は「事後分布による確率モデルの平均を予測分布とみなすこと」です。
事後分布の平均(EAP)を推定値として採用するのはとても危ない。
#統計 ベイズ統計について何も知らない人向けの解説で、危険な選択肢とそうでない選択肢について平等にかつごちゃ混ぜに説明するのはやめた方がよいという話をしています。
これも私には単なる常識的配慮に過ぎないと思うのですが、どうでしょうか?
これも私には単なる常識的配慮に過ぎないと思うのですが、どうでしょうか?
#統計 このスレッドの主題である「ベイズなら仮説が正しい確率が分かる」について、豊田秀樹さんがどのように述べているかについてはこのスレッドの以下のリンク先以降を参照。
#統計 あと以下のリンク先以降も参照
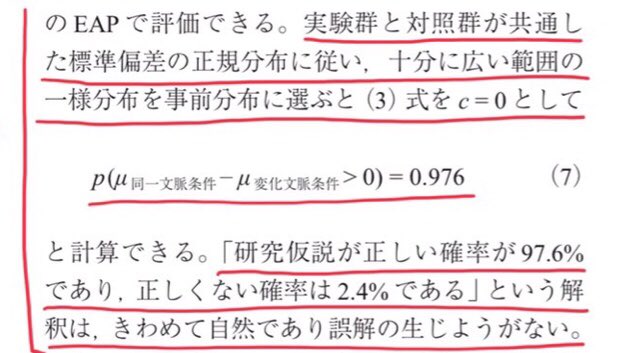
リンク先の添付画像の一部をこのツイートに添付。豊田秀樹さんは「共通した標準偏差を持つ2つの正規分布モデル」と「十分に広い範囲の一様事前分布」から作った事後分布で計算した確率を「研究仮説が正しい確率」と呼んでいます。
リンク先の添付画像の一部をこのツイートに添付。豊田秀樹さんは「共通した標準偏差を持つ2つの正規分布モデル」と「十分に広い範囲の一様事前分布」から作った事後分布で計算した確率を「研究仮説が正しい確率」と呼んでいます。
#統計 未知の分布のサンプルを扱うベイズ統計の文脈で、事後分布は現実世界に比較対象が存在しないモデル内確率分布なので、それが何を意味しているかを理解することは、間違いなく、多くの人達にとって非常に難しい。
それに対して通常のP値や信頼区間が何を意味しているかはずっと分かり易いです。
それに対して通常のP値や信頼区間が何を意味しているかはずっと分かり易いです。
#統計 ベイズ統計に興味がある人は
未知の確率分布で生成されたサンプルを扱うベイズ統計
と
有病率と有病者の陽性率と無病者の陰性率からの陽性者が有病者である確率の計算
では難易度が段違いであることを知っておくべきです。後者は大学入試でも出題される程度に易しく、前者は難解です。
未知の確率分布で生成されたサンプルを扱うベイズ統計
と
有病率と有病者の陽性率と無病者の陰性率からの陽性者が有病者である確率の計算
では難易度が段違いであることを知っておくべきです。後者は大学入試でも出題される程度に易しく、前者は難解です。
#統計 ついでに述べておくと
モンティ・ホール問題
も確率計算としては易しい話です。
その手の易しい話と、未知の確率法則が生成したサンプルを扱うベイズ統計では難易度が違い過ぎるので、無関係の話題だと思った方がよいです。
多くの伝統的解説はその意味で誤解に誘導する内容になっています。
モンティ・ホール問題
も確率計算としては易しい話です。
その手の易しい話と、未知の確率法則が生成したサンプルを扱うベイズ統計では難易度が違い過ぎるので、無関係の話題だと思った方がよいです。
多くの伝統的解説はその意味で誤解に誘導する内容になっています。
#統計 「ベイズ統計なら仮説が正しい確率が分かる」的な言説はクズそのものなので、そういうクズそのものと、モンティ・ホール問題や検査陽性者の罹患確率を求める問題をもベイズ統計に話題だとするせいぜいミスリーディングなだけの解説を並べるのは不適切だという意見があるかもしれませんが~続く
#統計 続き~、本物のベイズ統計は難解であり、その難解さは噂の形で既に広まっているので、陽性者の罹患確率の計算にまで「ベイズ」の名を冠せてしまうと、大学入試レベルの易しい問題であることを認識できる人が減り、今のような緊急時の危険度が上がってしまいます。想像以上に有害かもしれない。
#統計 ‼️‼️‼️
島谷健一郎『ポアソン分布・ポアソン回帰・ポアソン過程』(2017)はコンピューターシミュレーションでも遊べるくらい具体的な例を通して、基本的かつ普遍的な考え方を解説している気持ちの良い本です。
数学が得意な人が娯楽で読むには非常に良い本だと思う。
島谷健一郎『ポアソン分布・ポアソン回帰・ポアソン過程』(2017)はコンピューターシミュレーションでも遊べるくらい具体的な例を通して、基本的かつ普遍的な考え方を解説している気持ちの良い本です。
数学が得意な人が娯楽で読むには非常に良い本だと思う。
#統計 補足説明
パラメータに関する事後分布の平均は
パラメータ空間の座標の取り方に強く依存します。
事後分布の台が凸型になるかどうかも座標の取り方に依存。
事後分布の平均(所謂EAP)を推定値として採用することはこの意味でもかなり危険です。具体例に続く
パラメータに関する事後分布の平均は
パラメータ空間の座標の取り方に強く依存します。
事後分布の台が凸型になるかどうかも座標の取り方に依存。
事後分布の平均(所謂EAP)を推定値として採用することはこの意味でもかなり危険です。具体例に続く
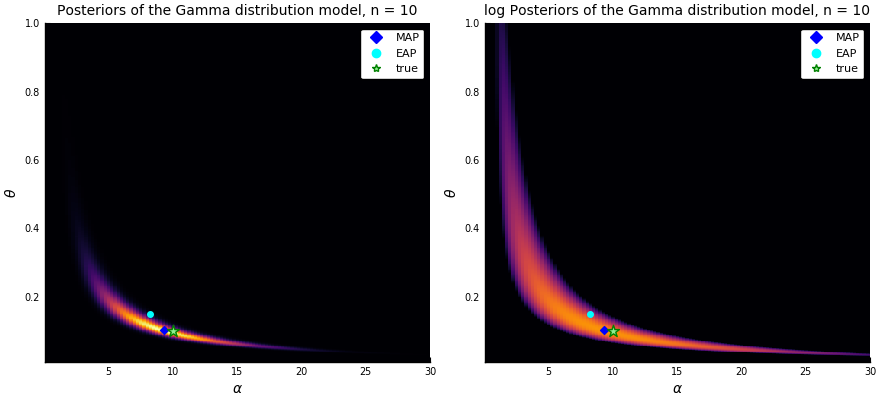
#統計 例: Gamma(α=10, θ=0.1) 分布で生成したサイズn=10のガンマ分布モデルの事後分布をプロット。事前分布は台が十分広い一様分布。
☆が真値、◆がMAP推定値(今の場合は最尤推定値と同じ)、◯は事後分布(posterior)の平均(=EAP推定値)です。
EAP推定値が事後分布の台から外れていることに注目。
☆が真値、◆がMAP推定値(今の場合は最尤推定値と同じ)、◯は事後分布(posterior)の平均(=EAP推定値)です。
EAP推定値が事後分布の台から外れていることに注目。
#統計 サンプルを生成した分布がGamma(α=2, θ=0.5)の場合
☆が真値、◆がMAP推定値(今の場合は最尤推定値と同じ)、◯は事後分布(posterior)の平均(=EAP推定値)です。
EAP推定値が事後分布の台から外れかけている。
#Julia言語 ソースコード↓ (汚いです)
nbviewer.jupyter.org/gist/genkuroki…
☆が真値、◆がMAP推定値(今の場合は最尤推定値と同じ)、◯は事後分布(posterior)の平均(=EAP推定値)です。
EAP推定値が事後分布の台から外れかけている。
#Julia言語 ソースコード↓ (汚いです)
nbviewer.jupyter.org/gist/genkuroki…
#統計 事後分布の台が凸型ではない場合には、事後分布の平均は事後分布が集中している場所から外れることになります。こういう意味でEAP推定値(=事後分布の平均)は要注意だと思う。
選択肢が多い場面では至る所に落とし穴が隠れているので要注意。
選択肢が多い場面では至る所に落とし穴が隠れているので要注意。
#統計 リスク函数として事後分布に関する平均二乗誤差を採用すると、リスク最小化は以上で__要注意__であることを指摘した事後分布の平均(EAP)で実現されます。
リスク最小化を「主観に基く合理性」だと解釈して、「主観主義」によって「ベイズ推定」を説明している文献は沢山あるので要注意です。
リスク最小化を「主観に基く合理性」だと解釈して、「主観主義」によって「ベイズ推定」を説明している文献は沢山あるので要注意です。
#統計 渡辺澄夫『ベイズ統計の理論と方法』では、以上で__要注意__であることを指摘したEAP法=平均プラグイン法への注意がp.125の4.6.1節にあります。
引用【最適なパラメータの集合が凸集合でないときには、平均プラグイン法は統計的推測には適していないので注意が必要である】
引用【最適なパラメータの集合が凸集合でないときには、平均プラグイン法は統計的推測には適していないので注意が必要である】
#統計 気軽に使えるようになったMCMC法では事後分布のサンプルが得られるので、事後分布のサンプルから気軽に近似計算できる事後分布の代表値ごとに「どのような危険があるか」に関する情報はユーザー側にとって必須の予備知識だと思われます。
#統計 事後分布の平均のずれ方に納得できなかったので(不安はいつも消えない)、事後分布の対数の例もプロットしてみました。
対数を取って確認したら(添付画像の右半分)、左側と上側に結構のびていました。
足し上げ時の重みが小さくても遠く離れていれば平均には影響を与えることができる。
対数を取って確認したら(添付画像の右半分)、左側と上側に結構のびていました。
足し上げ時の重みが小さくても遠く離れていれば平均には影響を与えることができる。
#統計 リスク最小化で「主観主義」に基く「ベイズ推定」を解説しているとみなせるものには
to-kei.net/bayes/decision…
決定理論とは?簡単にわかりやすく説明
to-kei.net/bayes/bayes-es…
ベイズ推定量は、事後分布の平均と一致する
(互いに相互リンク)
などがあります。
to-kei.net/bayes/decision…
決定理論とは?簡単にわかりやすく説明
to-kei.net/bayes/bayes-es…
ベイズ推定量は、事後分布の平均と一致する
(互いに相互リンク)
などがあります。
#統計 損失やリスク最小化のような条件付き最適化問題のスタイルでの定式化は数学的に素性がよいので、「これは合理的だ!」と信じてしまいそうになるのですが、統計的意思決定論によるベイズ推定の解釈では推定結果と現実の関係の問題を一切扱わないので、現実にそのまま応用するのは危険です。
#統計 現実の確率法則のモデル化として未知の確率分布q(x)を用意して、統計分析用の確率モデルp(x|w)と明瞭に区別して議論を進めていればよいのですが、q(x)を一切出さずに、p(x|w)だけで押し通している解説が結構多いので、初学者が非科学的でおかしなスタイルを身に付ける危険性があると思います。
#統計 統計的意思決定論によるベイズ推定の解説でも、q(x)を一切出さずに、なんと、サンプルが
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に従って生成されているという設定での平均リスク最小化を扱うことになる。q(x)との関係は一切考慮しない。
その結果、EAP推定を勧めて来たりするわけ。
Z(x_1,…,x_n) = ∫p(x_1|w)…p(x_n|w)φ(w)dw
に従って生成されているという設定での平均リスク最小化を扱うことになる。q(x)との関係は一切考慮しない。
その結果、EAP推定を勧めて来たりするわけ。
#統計 q(x)との関係を一切考慮していないくせに「統計学」を名乗るとは一体どういうことか?と言いたくなる人もいるかもしれませんが、まさにそれこそが「主観主義」だということなのだと思います。
現実での予測の失敗には一切配慮せずに、主観内部でリスクが最小化できれば合理的だとみます方針。
現実での予測の失敗には一切配慮せずに、主観内部でリスクが最小化できれば合理的だとみます方針。
#統計 条件付き最適化問題による数学的定式化は「よい数学的定式化」の典型例です。
数学をよく知っているほど、そういうことがわかって来るので、数学をよく知ってるせいで「おお!なるほど、これは合理的だ!」と感じて騙される可能性がある。
この辺は本当に要注意な部分だと思う。
数学をよく知っているほど、そういうことがわかって来るので、数学をよく知ってるせいで「おお!なるほど、これは合理的だ!」と感じて騙される可能性がある。
この辺は本当に要注意な部分だと思う。
#統計 関連スレッド。
ベイズにしても研究の再現性の危機の問題が解決しないことは自明だと思う。
ベイズ統計を理解していない人だけがベイズにすればバラ色であるかのようなことを言えるのだと思う。
理解している人が適切に使えば強力な道具になり得るとは思いますが。
ベイズにしても研究の再現性の危機の問題が解決しないことは自明だと思う。
ベイズ統計を理解していない人だけがベイズにすればバラ色であるかのようなことを言えるのだと思う。
理解している人が適切に使えば強力な道具になり得るとは思いますが。
#統計 当然の指摘。当該の本ではプロローグでベルヌーイ分布モデルのベイズ版でひどい説明をしていると思う。
意図1~4で異なる確率モデルを使う必要があるのは、ベイズであろうがなかろうが同じこと。めちゃくちゃ、当たり前の話。
意図1~4で異なる確率モデルを使う必要があるのは、ベイズであろうがなかろうが同じこと。めちゃくちゃ、当たり前の話。
#統計 続き。ベルヌーイ分布モデル(成功・失敗の確率を扱う最も簡単な確率モデル)では、
(1) 通常の「頻度論」での信頼区間と同じ意味での確率(モデル内標本分布で計算した確率)
と
(2) おとなしめの事前分布でのベイズ統計での事後分布で計算した確率
が互いに相手をよく近似することを示せます。
(1) 通常の「頻度論」での信頼区間と同じ意味での確率(モデル内標本分布で計算した確率)
と
(2) おとなしめの事前分布でのベイズ統計での事後分布で計算した確率
が互いに相手をよく近似することを示せます。
#統計 続き。実際、二項分布の正規分布近似に基くベルヌーイ分布モデルにおけるP値函数(Normalの線)と、それに対応するベイズ統計での事後分布でのP値函数の類似物(Posteriorの線)を同時にプロットするとn=100ではほとんどぴったり重なります!
#統計 上の動画中のPosteriorの線を描くために使った事後分布はJeffreys事前分布の事後分布です。おとなしめの他の事前分布(例えば一様事前分布)でも同じような感じになります。
要するに、ベルヌーイ分布モデルのような単純なモデルでは、ベイズ統計を行っても新しいことは出て来ないということ。
要するに、ベルヌーイ分布モデルのような単純なモデルでは、ベイズ統計を行っても新しいことは出て来ないということ。
#統計 それなのに、ベイズにすれば研究仮説が正しい確率を計算できるなどと言っているのはひどい。
プロローグでベイズ統計を使っている部分は(「7割以上云々」の部分)は「頻度論」の片側検定と本質的に同じことです。
公開されているプロローグだけでひどい内容であることが一目瞭然だと思う。
プロローグでベイズ統計を使っている部分は(「7割以上云々」の部分)は「頻度論」の片側検定と本質的に同じことです。
公開されているプロローグだけでひどい内容であることが一目瞭然だと思う。
#統計 動画解説。Normalの青の線は「100回中k回成功した」というデータが得られたときの「成功確率はθである」という仮説のP値です(横軸がθ)。二項分布の正規分布近似で定義。
Posteriorの橙の破線は、Jeffreys事前分布の事後分布で計算したP値函数の類似物。定義についてはソースファイルを参照。
Posteriorの橙の破線は、Jeffreys事前分布の事後分布で計算したP値函数の類似物。定義についてはソースファイルを参照。
#統計 ベルヌーイ分布モデルでの動画を作ったソースファイルは
nbviewer.jupyter.org/gist/genkuroki…
にあります。
事後分布のCDFを F(θ) と書くとき、P値函数の類似物 pval_post(θ) を
pval_post(θ) = min{2F(θ), 2(1-F(θ)), 1}
と定義しています。両側検定のP値の類似物です。
これが通常のP値にほぼ一致。
nbviewer.jupyter.org/gist/genkuroki…
にあります。
事後分布のCDFを F(θ) と書くとき、P値函数の類似物 pval_post(θ) を
pval_post(θ) = min{2F(θ), 2(1-F(θ)), 1}
と定義しています。両側検定のP値の類似物です。
これが通常のP値にほぼ一致。
#統計 世間一般では、ベイズ統計に関するまともな理解は全く浸透しておらず、成功と失敗の確率を扱う最も単純な確率モデル(ベルヌーイ分布モデル)の場合でさえ、ベイズ統計にするとどういう感じになるかを理解している人は少ないと思う。
そういう弱い人達をターゲットにして騙すための本にも見える。
そういう弱い人達をターゲットにして騙すための本にも見える。
#統計 「頻度論」と「ベイズ」で定義は異なるがリンク先動画のようにほとんど一致している値があるとき、ベイズにした途端に「研究仮説が正しい確率の値とみなせる」となるはずがない。
豊田秀樹さんがやっているのはそういうこと。
騙されずにみんなで批判しないとトンデモ側が普及してしまう。
豊田秀樹さんがやっているのはそういうこと。
騙されずにみんなで批判しないとトンデモ側が普及してしまう。
#統計 たぶん、理系も含めて世間一般では、正規分布分布モデルの尤度函数(もしくは事後分布)の形さえ見たことがない人の方が多数派だと思う。
リンク先動画は、正規分布モデルの尤度函数をそのまま正規化して確率密度函数にしたものに従う「乱数」を生成する動画になっています。
リンク先動画は、正規分布モデルの尤度函数をそのまま正規化して確率密度函数にしたものに従う「乱数」を生成する動画になっています。
#統計 #Julia言語
須山敦志『ベイズ推論による機械学習』p.80のPlots.jlによる再現!
nbviewer.jupyter.org/gist/genkuroki…
Bernoulli分布モデル
も参照するといいかも。このノートブックは、渡辺澄夫『ベイズ統計の理論と方法』の話+α (AIC, WAIC, LOOCV, 自由エネルギー, WBIC)も含む。
須山敦志『ベイズ推論による機械学習』p.80のPlots.jlによる再現!
nbviewer.jupyter.org/gist/genkuroki…
Bernoulli分布モデル
も参照するといいかも。このノートブックは、渡辺澄夫『ベイズ統計の理論と方法』の話+α (AIC, WAIC, LOOCV, 自由エネルギー, WBIC)も含む。
#統計 【須山ベイズもq(x)は持ち出してないですよね】
ポイントは「真の分布がモデルで実現不可能な場合」も扱っているか否かです。
モデルp(y|x,w)によってq(y|x)=p(y|x,w₀)の形で実現できない真の分q(y|x)が実質的に出て来ているかで明瞭に判別できる。続く
ポイントは「真の分布がモデルで実現不可能な場合」も扱っているか否かです。
モデルp(y|x,w)によってq(y|x)=p(y|x,w₀)の形で実現できない真の分q(y|x)が実質的に出て来ているかで明瞭に判別できる。続く
#統計 須山敦志『ベイズ推論による機械学習』pp.108-109では
y = sin x + noise, 0 ≦ x ≦ 2π
という法則で生成したデータと
y = M-1次の多項式 + noise
という多項式回帰モデルで作った予測分布を扱っています。このようにデータを生成した法則がモデルに含まれない場合も扱っています。
y = sin x + noise, 0 ≦ x ≦ 2π
という法則で生成したデータと
y = M-1次の多項式 + noise
という多項式回帰モデルで作った予測分布を扱っています。このようにデータを生成した法則がモデルに含まれない場合も扱っています。
#統計 そもそも機械学習の文脈では「真の法則を含むモデルを我々が得ることができる」という想定は最初から馬鹿げていると思う。本のタイトルにも「機械学習」とある。
モデルは単なる道具であるという割り切りがあった方が、科学的に怪しげな言説を排除し易いと思う。
モデルは単なる道具であるという割り切りがあった方が、科学的に怪しげな言説を排除し易いと思う。
#統計 ベルヌーイ分布モデルだけではなく、統計学入門でよく使われる各種の正規分布モデルでも、十分に大きなnでの「頻度論」と「ベイズ」の数値の近似的な一致を示せます(もっと広いクラスで成立)。
シンプルなモデルでは「頻度論」から「ベイズ」に移っても新しいことが出て来るわけではないです。
シンプルなモデルでは「頻度論」から「ベイズ」に移っても新しいことが出て来るわけではないです。
#統計 「ベイズ統計なら研究仮説が正しい確率を求められる」というおかしなことを言っている人を見たら、騙されないように注意が必要。
#統計 件の「瀕死本」はすでに書店に並んでいます。
私が恐れていることは、「瀕死本」の類が沢山売れて、通常の仮説検定や信頼区間について誤解し、「ベイズ統計なら仮説が正しい確率が分かる」というデタラメを信じる人達が増えることです。
知的被害者が加害者側に回るループができるのが怖い。
私が恐れていることは、「瀕死本」の類が沢山売れて、通常の仮説検定や信頼区間について誤解し、「ベイズ統計なら仮説が正しい確率が分かる」というデタラメを信じる人達が増えることです。
知的被害者が加害者側に回るループができるのが怖い。
#統計 リンク先動画解説
ベイズ統計では、モデルの範囲内で真実に最も近い仮説Bが真実から程遠くても、ベイズ更新によって仮説Bが正しい確率はモデル内で100%に近付きます。
こういう類の確率を単に「仮説が正しい確率」と呼ぶのは詐欺だと思う。
真実とは違うモデル内での確率に過ぎない。
ベイズ統計では、モデルの範囲内で真実に最も近い仮説Bが真実から程遠くても、ベイズ更新によって仮説Bが正しい確率はモデル内で100%に近付きます。
こういう類の確率を単に「仮説が正しい確率」と呼ぶのは詐欺だと思う。
真実とは違うモデル内での確率に過ぎない。
#統計 私による「瀕死本」的言説に対する批判は、ベイズ統計が持つ数学的性質をコンピュータを使った計算(ソースコードも公開)を示しながら解説している相当に具体的な内容になっています。
「瀕死本」的言説を全否定しながら、ベイズ統計の面白さを知ってもらえればうれしいです。
「瀕死本」的言説を全否定しながら、ベイズ統計の面白さを知ってもらえればうれしいです。
#統計 リンク先動画解説
真のサイコロXでは3の目が出る確率だけが他よりほんの少し大きいだけなのに、ベイズ更新によってモデル内での「3,4の目が出る確率は1,2,5,6が出る確率の3倍である」という仮説の正しい確率は100%に収束しています。
これはベイズ統計での「事後確率」が持つ普遍的性質。
真のサイコロXでは3の目が出る確率だけが他よりほんの少し大きいだけなのに、ベイズ更新によってモデル内での「3,4の目が出る確率は1,2,5,6が出る確率の3倍である」という仮説の正しい確率は100%に収束しています。
これはベイズ統計での「事後確率」が持つ普遍的性質。
#統計 数値実験では、真の確率分布をカンニングできるので、ベイズ更新によってモデル内で仮説Bの正しい確率が100%に近付いても、仮説Bが真実から程遠いことを確認できます。
しかし、カンニングできない場合にウソを見抜くのは一般に非常に難しい。相手が無知ならウソを通し易くなります。
しかし、カンニングできない場合にウソを見抜くのは一般に非常に難しい。相手が無知ならウソを通し易くなります。
#統計 「瀕死本」的な「ベイズ統計なら仮説が正しい確率が分かる」という言説の普及は、まさに無知で騙され易い人達の大量生産につながっています。
そういうことをやっちゃダメだと思います。
「瀕死本」の出版のタイミングで批判する人が増えるとよいと思います。
そういうことをやっちゃダメだと思います。
「瀕死本」の出版のタイミングで批判する人が増えるとよいと思います。
#統計 「瀕死本」のプロローグ
asakura.co.jp/books/isbn/978…
→ app.box.com/s/mju36d42ofg0…
の問題点の解説↓
nbviewer.jupyter.org/gist/genkuroki…
添付画像のケースでは、「ベイズ統計では仮説が正しい確率が分かる」という主張は「P値を仮説が正しい確率だと解釈してよい」と実質的に同じ意味になります。
asakura.co.jp/books/isbn/978…
→ app.box.com/s/mju36d42ofg0…
の問題点の解説↓
nbviewer.jupyter.org/gist/genkuroki…
添付画像のケースでは、「ベイズ統計では仮説が正しい確率が分かる」という主張は「P値を仮説が正しい確率だと解釈してよい」と実質的に同じ意味になります。
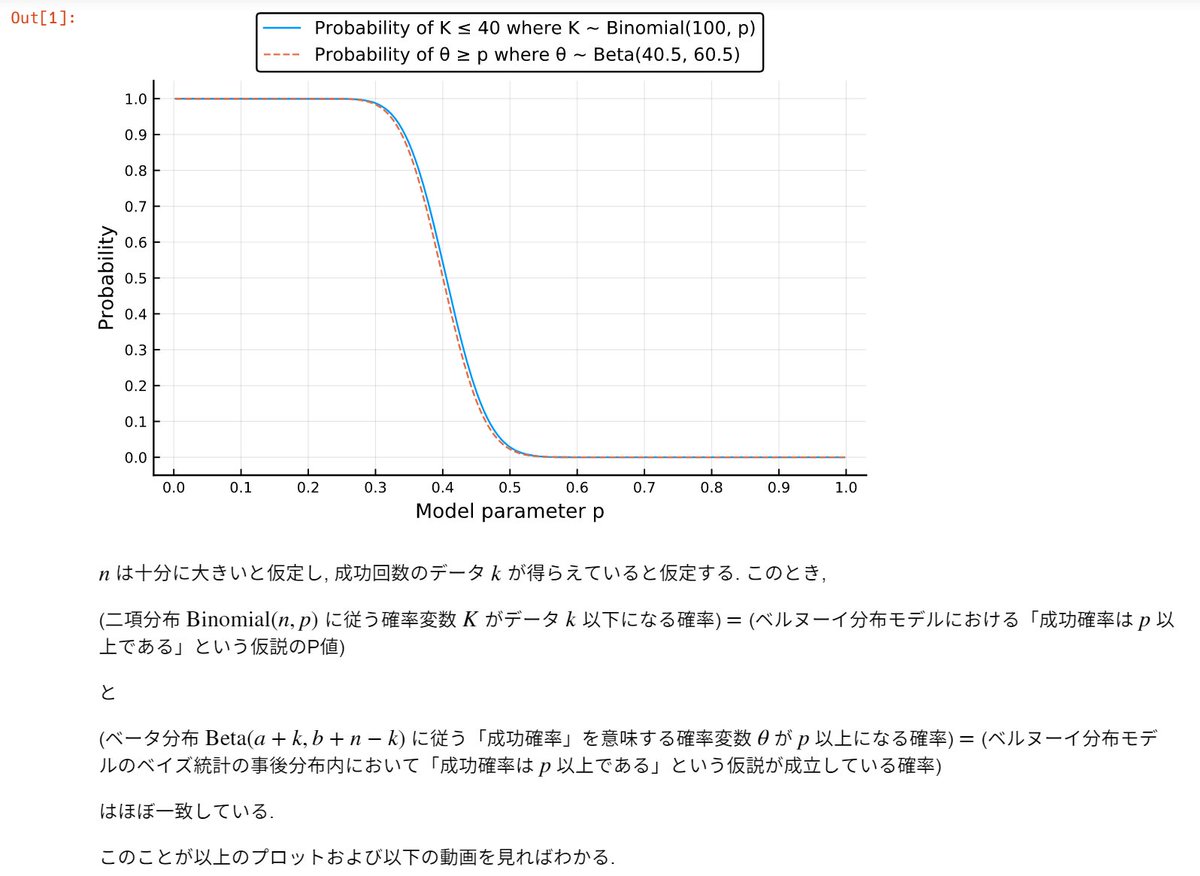

#統計 #Julia言語
nbviewer.jupyter.org/gist/genkuroki…
青の実線=ベルヌーイ分布モデルにおける「成功確率はp以上である」という仮説のP値
橙の破線=ベルヌーイ分布モデルのベイズ統計の事後分布内において「成功確率はp以上である」という仮説が成立している確率
これらはほぼ一致している。
nbviewer.jupyter.org/gist/genkuroki…
青の実線=ベルヌーイ分布モデルにおける「成功確率はp以上である」という仮説のP値
橙の破線=ベルヌーイ分布モデルのベイズ統計の事後分布内において「成功確率はp以上である」という仮説が成立している確率
これらはほぼ一致している。
#統計 実質的に小学校レベルの割合の計算に過ぎない「陽性的中率」の計算を「ベイズ推定」などと呼んでしまう分かっていない人達が大部分の中で、「ベイズ統計では仮説が正しい確率が分かる」という言説が通ってしまう可能性は相当に高いと思う。
これは非常によろしくないことだと思います。
これは非常によろしくないことだと思います。
#統計 数値計算ではなく、手計算で2つの確率曲線の近似的な一致を確認したい人は
(1) 二項分布Binomial(n, p)に従う確率変数 K 対する K/n の分布の中心極限定理
と
(2) ベータ分布Beta(a+k, b+n-k)の中心極限定理
を比較してみるとよいです(中心極限定理=正規分布近似)。難しくないです。
(1) 二項分布Binomial(n, p)に従う確率変数 K 対する K/n の分布の中心極限定理
と
(2) ベータ分布Beta(a+k, b+n-k)の中心極限定理
を比較してみるとよいです(中心極限定理=正規分布近似)。難しくないです。
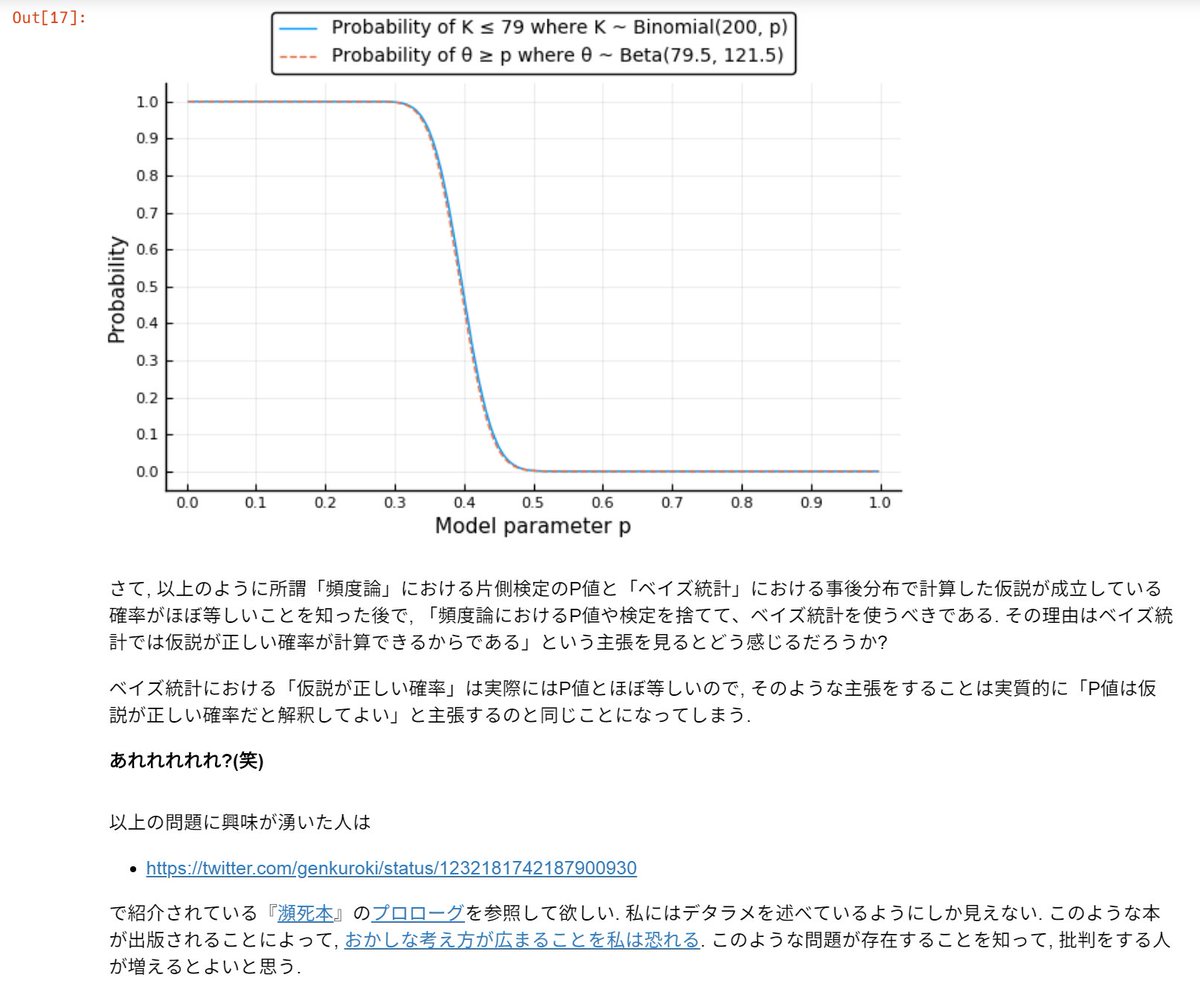
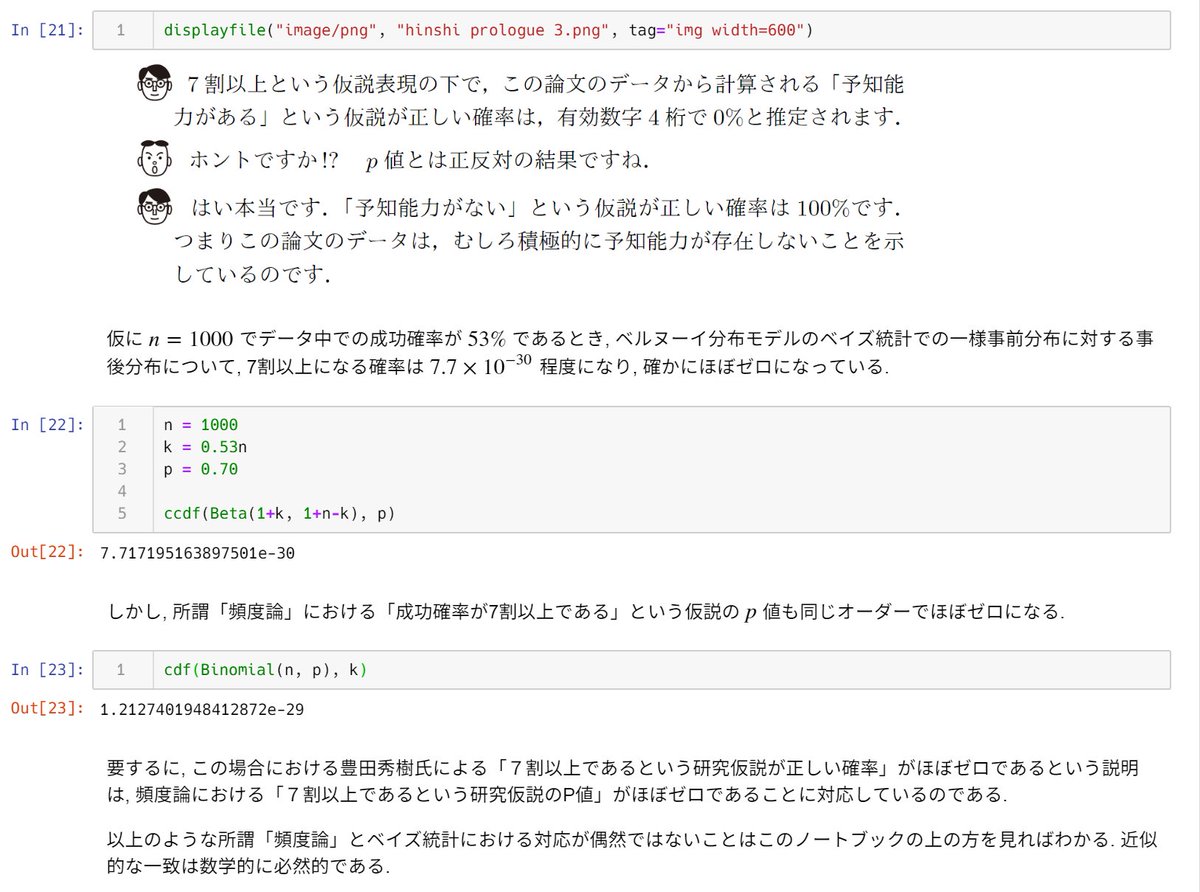
#統計 豊田秀樹氏の『瀕死本』的な「ベイズ統計では仮説が正しい確率が分かる」という言説への批判を含むノートブックを更新した。公開されている『瀕死本』のプロローグから引用して批判的解説を加えておいた。
nbviewer.jupyter.org/gist/genkuroki…
ベルヌーイ分布モデルにおける「頻度論」と「ベイズ」の比較
nbviewer.jupyter.org/gist/genkuroki…
ベルヌーイ分布モデルにおける「頻度論」と「ベイズ」の比較
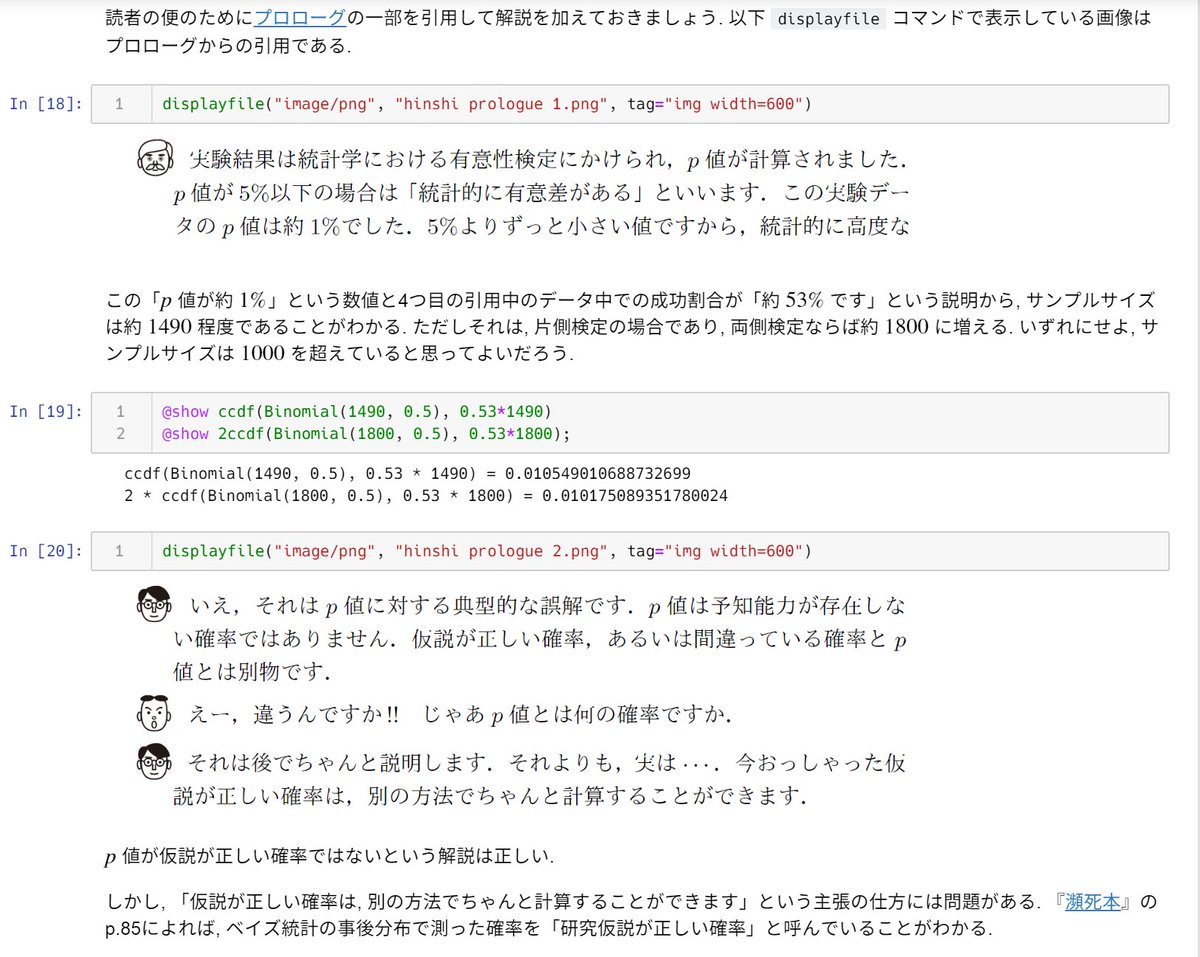

#統計 『瀕死本』p.86から引用
【p値と比較して phc (~)は, このような直観的な理解を与える指標です. しかも何回計算しても多重比較のような補正が必要ありません.】
ベイズ統計の事後確率なら多重比較の問題が起こらないと考えているようですが、「業界」ではそう信じられているのでしょうか?
【p値と比較して phc (~)は, このような直観的な理解を与える指標です. しかも何回計算しても多重比較のような補正が必要ありません.】
ベイズ統計の事後確率なら多重比較の問題が起こらないと考えているようですが、「業界」ではそう信じられているのでしょうか?
#統計 ベルヌーイ分布モデルや各種の単純な正規分布モデルにおいては、おとなしめの事前分布に対する事後分布で測った確率には、それと近似的に一致する所謂「頻度論」側でのP値(もしくはその一般化)がある。
だから、所謂「頻度論」で問題になることは、ベイズ統計でも問題になると考えられます。
だから、所謂「頻度論」で問題になることは、ベイズ統計でも問題になると考えられます。
#統計 所謂「頻度論」であろうがベイズであろうが、n→∞での漸近論が一致しているならば、それらは互いを近似し合う関係になるので、どの方法を使って推定しても大きな違いない。
豊田秀樹氏はそういう場合にもベイズ統計にすると頻度論ではできなかったことができると主張しているのでアウト。
豊田秀樹氏はそういう場合にもベイズ統計にすると頻度論ではできなかったことができると主張しているのでアウト。