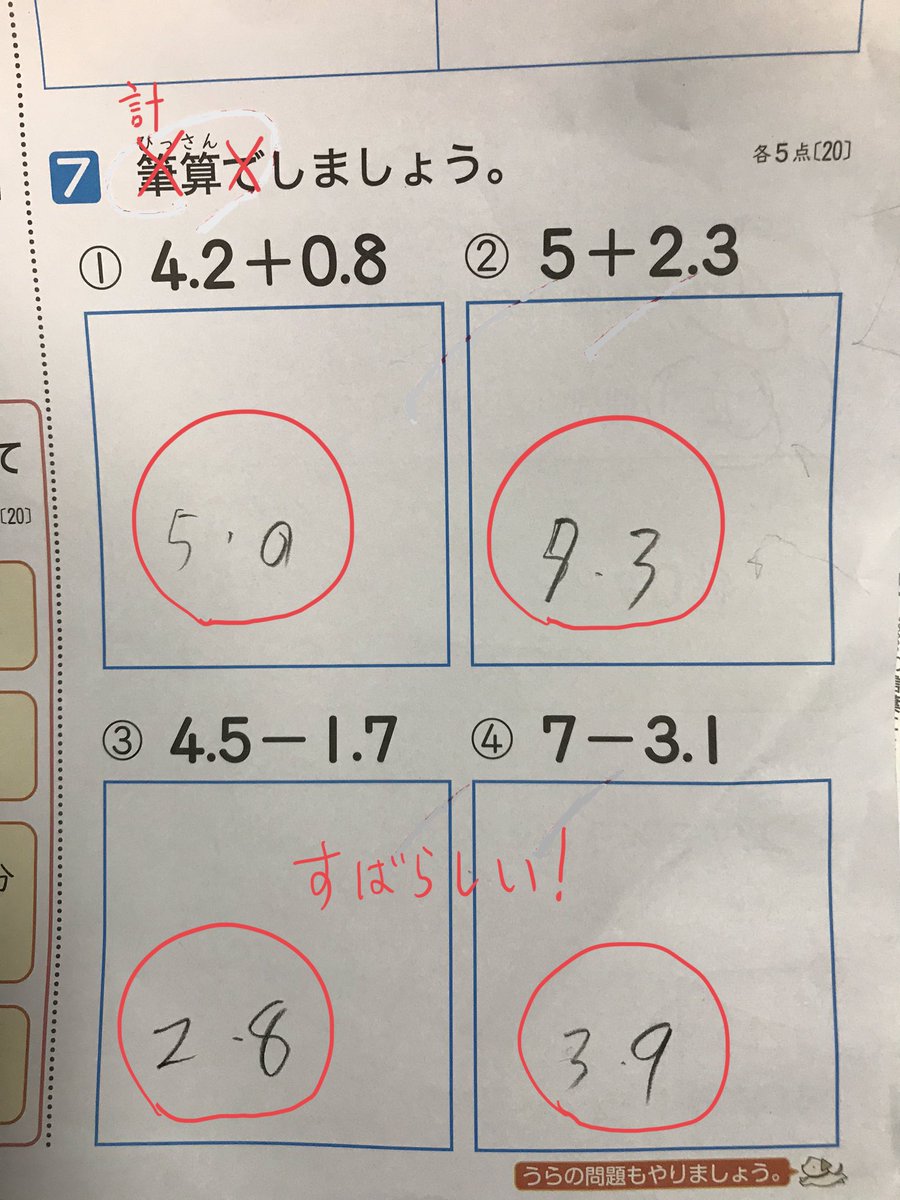
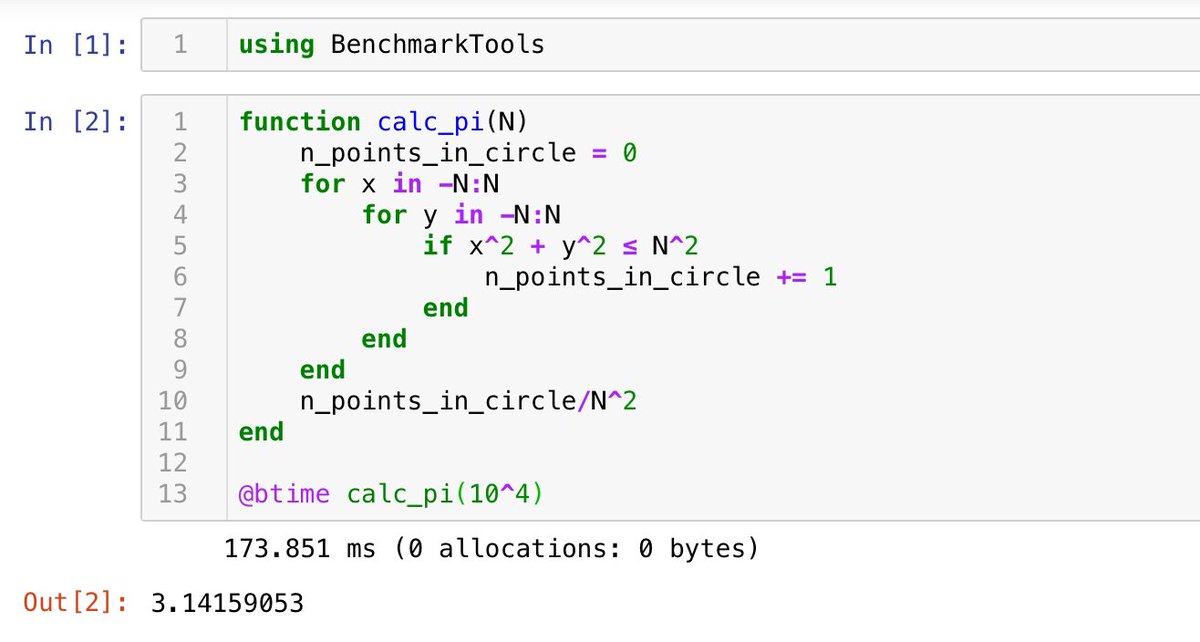
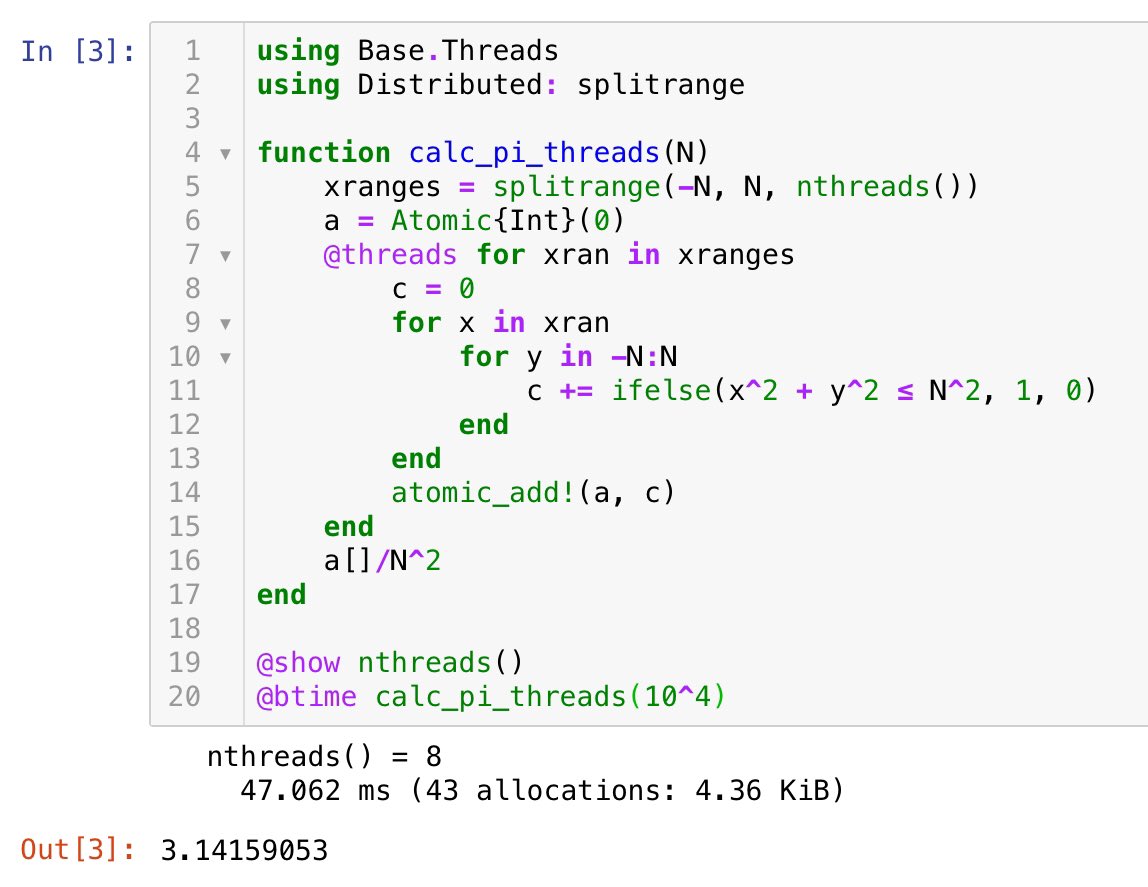
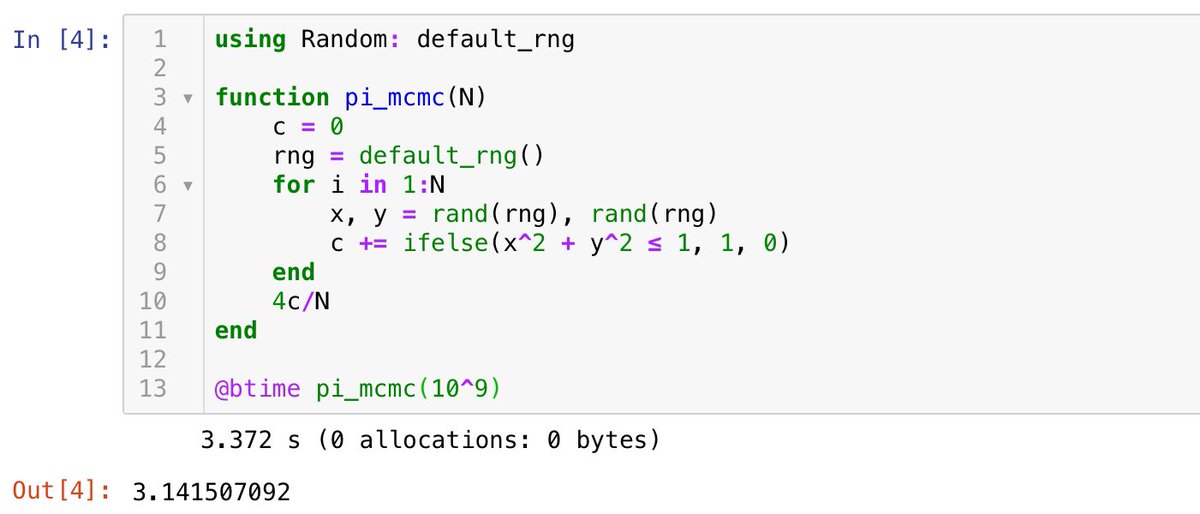
#統計 あと、小杉考司さんの添付画像のツイートが見えたので、クリックしてチラ見したら、
【2.「主観確率」「意思決定論」によるベイズ解釈は役に立つのか ⇒ 役に立つ/立たないでなく、それが前提である。】
と書いてあって、そっと閉じた。
確かに「ほんとうにわかりやすい」🤣
【2.「主観確率」「意思決定論」によるベイズ解釈は役に立つのか ⇒ 役に立つ/立たないでなく、それが前提である。】
と書いてあって、そっと閉じた。
確かに「ほんとうにわかりやすい」🤣

#統計 さらに
【3.ベイズ統計学において「パラメータは確率変数、データは定数」という説明は正しいか ⇒ 主義による。しかしながら、特に説明をおかないのであるば、メジャーである主観ベイズ主義で解釈すべきであろうから、この説明は正しいとすべき。】
とも書いてあった。
確かに「良記事」🤣
【3.ベイズ統計学において「パラメータは確率変数、データは定数」という説明は正しいか ⇒ 主義による。しかしながら、特に説明をおかないのであるば、メジャーである主観ベイズ主義で解釈すべきであろうから、この説明は正しいとすべき。】
とも書いてあった。
確かに「良記事」🤣
#統計
主義による
↓しかし
特に説明をおかないのであるば、
メジャーである主観ベイズ主義で解釈すべきであろう
↓ゆえに
この説明は正しいとすべき
こういう代物を「良記事」と紹介できる程度に恥知らずだと、議論では「無敵」だよね。
検索すれば小杉考司さんが書いた杜撰な解説も見つかります。
主義による
↓しかし
特に説明をおかないのであるば、
メジャーである主観ベイズ主義で解釈すべきであろう
↓ゆえに
この説明は正しいとすべき
こういう代物を「良記事」と紹介できる程度に恥知らずだと、議論では「無敵」だよね。
検索すれば小杉考司さんが書いた杜撰な解説も見つかります。
#統計 正確に引用するだけで、
「(笑)これってネタ?」
「いいえマジみたいです」
「(笑)」「(笑)」
となるような代物を「良記事」とみなして、ツイッターで拡散しちゃうような人が日本語圏の心理統計においてベイズ統計の宣伝を行なっていたというのはかなり不幸なことだよね。
「(笑)これってネタ?」
「いいえマジみたいです」
「(笑)」「(笑)」
となるような代物を「良記事」とみなして、ツイッターで拡散しちゃうような人が日本語圏の心理統計においてベイズ統計の宣伝を行なっていたというのはかなり不幸なことだよね。
#統計 【「渡辺ベイズ解釈」】なる文字列も発見できるが、もちろん馬鹿げたことしか書かれていない。
#統計 日本語圏ではなく、英語圏での議論についてはMayoさんのウェブサイトが面白いです。
例えば、添付画像の
errorstatistics.com/2017/04/01/er-…
Gelman-Shaliziについては私のツイログ
twilog.org/genkuroki/sear…
も参照。
例えば、添付画像の
errorstatistics.com/2017/04/01/er-…
Gelman-Shaliziについては私のツイログ
twilog.org/genkuroki/sear…
も参照。
https://twitter.com/genkuroki/status/1335209121633562627

#統計 Gelmanさん達の有名かつ影響力に強い本
stat.columbia.edu/~gelman/book/
Bayesian Data Analysis
(非商用目的ならpdfをダウンロードできる)
で添付画像のように、渡辺澄夫『ベイズ統計の理論と方法』のメインディッシュであるWAICが紹介されています。
stat.columbia.edu/~gelman/book/
Bayesian Data Analysis
(非商用目的ならpdfをダウンロードできる)
で添付画像のように、渡辺澄夫『ベイズ統計の理論と方法』のメインディッシュであるWAICが紹介されています。

#統計 「8割おじさん」の西浦さん達の研究では、Gelmanさん達が開発しているStanが使われており、渡辺澄夫さんによる情報量規準WAICでモデルの比較を行おうとしています。
https://twitter.com/genkuroki/status/1250100950196301824
#統計 検索の都合でミュートしまくった状態でツイッターを使用しているのでよく分からないのですが、大昔のサヴェジさんが言っていたようなことを根拠に主観確率のベイズ主義が至高であるかのような発言をした人がいたとしたら、さすがに機械学習の技術が普及した現代においてはひどい時代錯誤です。
#統計 穏健に「事前分布は事前の主観的信念の表現だと思う必要は全然ないよね。そのような制限をつけた人達は単純に間違っていた。事前分布という道具をみんなで自由に使って行こうね」とどうして言えないかが不思議。
掛算順序問題に非常に似ている。
掛算順序問題に非常に似ている。
「掛算の式の順序はどちらでもいいよね。100年以上前から掛算順序が逆なら誤りだとしていたのは単純に間違っていた。これからは子供達に掛算の順序はどちらでもいいよと教えて行こうね」となれない人たちがいるという問題が掛算順序問題。
高等教育に従事している人達は、掛算順序問題に代表される算数教育の問題について、「自分達ならああいうことはしない」とはそう簡単に言えないと思う。結構みんな統計学を使っていますよね。
「大昔からそういうことになっている」とか「偉い人が書いた教科書にもそう書いてある」の類は正しいことの根拠にならないという教育を高等教育機関では徹底するべき。
ある程度以上難しい事柄については教えている側もひどい誤りを犯すことも謙虚に認めて、みんなで賢くなって行ければ良い。
ある程度以上難しい事柄については教えている側もひどい誤りを犯すことも謙虚に認めて、みんなで賢くなって行ければ良い。
結構みんな統計学を使っているようですが、「大昔からそういうことになっている」とか「偉い人が書いた教科書にもそう書いてある」の類を根拠に使っていたりする場合が多いのではないか?
根拠にならない根拠を挙げるのではなく、「本当は理解していない」と言えればスッキリする。
根拠にならない根拠を挙げるのではなく、「本当は理解していない」と言えればスッキリする。
#統計 言うまでもない補足
AICやWAICの情報量規準やLOO-CVのような交差検証は、未知の真の分布に対する事後予測分布の汎化誤差(もしくはその期待値)の推定量です。
それらは「真の分布」を想定したときの各モデルごとのリスクの指標なわけです。
「真の分布」の想定も大事な基本の1つ。
AICやWAICの情報量規準やLOO-CVのような交差検証は、未知の真の分布に対する事後予測分布の汎化誤差(もしくはその期待値)の推定量です。
それらは「真の分布」を想定したときの各モデルごとのリスクの指標なわけです。
「真の分布」の想定も大事な基本の1つ。
• • •
Missing some Tweet in this thread? You can try to
force a refresh