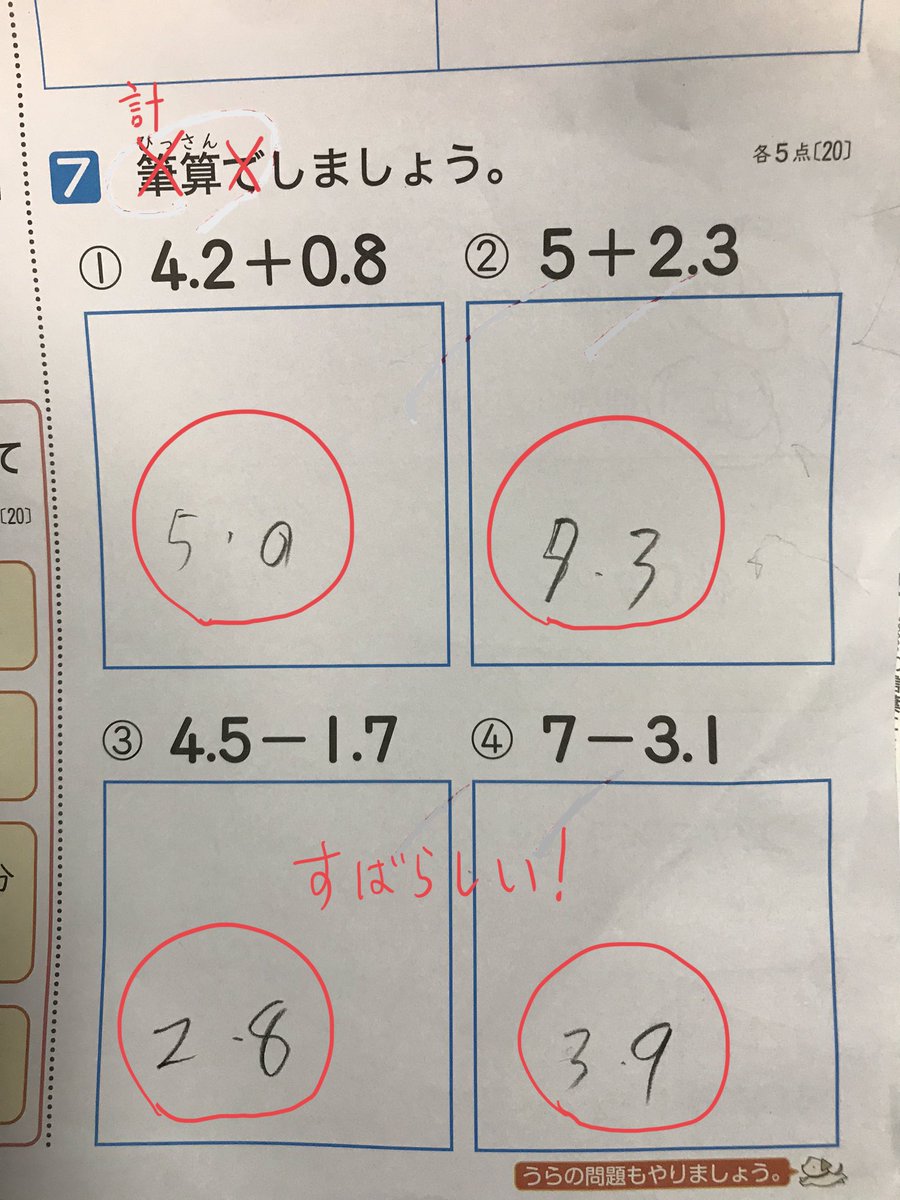
#統計 渡辺澄夫さんを悪い意味での「形式的ベイズ統計」の解説者扱いする人が登場するという事件がありました。
そこでは美添泰人さんが書いた1994年の文献が引用されていたのですが、それは参照できていない。しかし、
yoshizoe-stat.jp/stat/reference…
の
yoshizoe-stat.jp/stat/textbook/…
ベイズ推論
を発見。
そこでは美添泰人さんが書いた1994年の文献が引用されていたのですが、それは参照できていない。しかし、
yoshizoe-stat.jp/stat/reference…
の
yoshizoe-stat.jp/stat/textbook/…
ベイズ推論
を発見。
https://twitter.com/genkuroki/status/1319503985317871618

#統計 おそらく、「13 ベイズ推論」 yoshizoe-stat.jp/stat/textbook/… は、ウェブサイト主の美添泰人さんが1989年に行った放送大学での講義のテキストからの抜粋だと思う。
これは読み易くて、内容的にひどいので、事情がよく分かる良い資料だと思いました。
キーワードである「主観確率」の扱いも杜撰。
これは読み易くて、内容的にひどいので、事情がよく分かる良い資料だと思いました。
キーワードである「主観確率」の扱いも杜撰。
#統計 別の資料
yoshizoe-stat.jp/stat/reference…
↓
yoshizoe-stat.jp/stat/stat9602.…
ベイジアン統計学はいつでも有用か 「統計」1996年2月
添付画像はこれのp.5より。この批判は正当かもしれない。
しかし、批判している側も主観主義的ベイジアンの流儀の強制も意図しているなら問題ありすぎ。
yoshizoe-stat.jp/stat/reference…
↓
yoshizoe-stat.jp/stat/stat9602.…
ベイジアン統計学はいつでも有用か 「統計」1996年2月
添付画像はこれのp.5より。この批判は正当かもしれない。
しかし、批判している側も主観主義的ベイジアンの流儀の強制も意図しているなら問題ありすぎ。

#統計 「推測用のモデルの確率分布族+事前分布+データ→事後分布→事後分布の要約」という手続きだけで、何かまともな統計分析をしたつもりになるのは馬鹿げています。
しかし、複雑なモデルを採用して事前分布をテキトーに取ったという理由だけで、まともでないとは言えません。
しかし、複雑なモデルを採用して事前分布をテキトーに取ったという理由だけで、まともでないとは言えません。
#統計
yoshizoe-stat.jp/stat/stat9602.…
ベイジアン統計学はいつでも有用か 「統計」1996年2月
のp.2より。典型的な主観確率に基くベイズ主義者の言い分。
仮に各個人の合理的な行動の結果として主観確率がwell-definedに確定すると認めても、推測が当たるか外れるかという重大な問題は扱えません。続く
yoshizoe-stat.jp/stat/stat9602.…
ベイジアン統計学はいつでも有用か 「統計」1996年2月
のp.2より。典型的な主観確率に基くベイズ主義者の言い分。
仮に各個人の合理的な行動の結果として主観確率がwell-definedに確定すると認めても、推測が当たるか外れるかという重大な問題は扱えません。続く

#統計 ある人が、適当なギャンブルの設定によって適切に計測した自分自身の真の効用に基く主観確率によって事前分布を決定し、自分自身にとってベストの推測用モデルの確率分布族を用意し、データに基くベイズ更新によって事後分布を求めたとします。
問題:その人はそれだけで常に合理的か?
続く
問題:その人はそれだけで常に合理的か?
続く
#統計 「合理性」を「自分自身の主観的効用に基いて最良の行動を取ること」と定義したならば、「その人はそれだけで常に合理的か?」という問いへの答えはYesです。
Savageさんなどの名前を持ち出しがちな、主観確率のベイズ主義者にとってにベイズ統計の合理性はそういう意味になってしまいます!
Savageさんなどの名前を持ち出しがちな、主観確率のベイズ主義者にとってにベイズ統計の合理性はそういう意味になってしまいます!
#統計 そういう主観主義ベイジアンの態度を否定している論文 Gelman-Shalizi (2013) stat.columbia.edu/~gelman/resear… は何が問題なのかが分かりやすくなる引用(脚注34)をしてくれています。
【我々はすでに合理的なのに、どうして真理への収束というもう1つの規準について心配する必要があるのかね?】ひどい
【我々はすでに合理的なのに、どうして真理への収束というもう1つの規準について心配する必要があるのかね?】ひどい

#統計 自分自身にとっての最良の知識と情報をもとに、自分自身が本当に信じている事前の主観確率と、自分自身が最良だと信じているモデルの確率分布族と、実際に得られたデータから、ベイズの定理を使って正しく計算された事後分布による判断はすでに十分合理的なので、別の規準は無用である、と。😱
#統計 そういう意味での「合理性」を外で振り回されても迷惑なだけ。
普通の常識的な合理性はもっと穏健なものです。
事前分布を自分の事前の主観的信念の忠実な表現とすること自体は、まともな統計分析をできるかどうかと無関係であると、謙虚に考えられる人だけが通常の意味で合理的な人です。
普通の常識的な合理性はもっと穏健なものです。
事前分布を自分の事前の主観的信念の忠実な表現とすること自体は、まともな統計分析をできるかどうかと無関係であると、謙虚に考えられる人だけが通常の意味で合理的な人です。
#統計 仮に主観確率の概念が正当化されて、それで事前分布を決めても、まともな統計分析をできるかどうかとは無関係。
これを知っていれば、「サヴェジによれば云々」と言って来る人達がどれだけ考えの足りない人達であるかが明瞭になります。
これを知っていれば、「サヴェジによれば云々」と言って来る人達がどれだけ考えの足りない人達であるかが明瞭になります。
#統計 実際には、赤池弘次さんなども指摘しているように、Savageさんが主観確率の正当化に用いている前提自体がアドホック
↓
ismrepo.ism.ac.jp/index.php?acti…
の第7節
バケツの底が抜けている上に、仮にバケツの底を修理しても、まともな統計分析をできるかどうかとは無関係の話をしているだけなのです。
↓
ismrepo.ism.ac.jp/index.php?acti…
の第7節
バケツの底が抜けている上に、仮にバケツの底を修理しても、まともな統計分析をできるかどうかとは無関係の話をしているだけなのです。
#統計 以上のような予備知識のもとで
Gelman-Shalizi (2013)
Philosophy and the practice of Bayesian statistics
stat.columbia.edu/~gelman/resear…
を読めば、この論文の著者達が主観確率のベイズ主義の哲学を全否定せざるを得なかった理由がよくわかると思います。
詭弁潰しのために必要な訳です。
Gelman-Shalizi (2013)
Philosophy and the practice of Bayesian statistics
stat.columbia.edu/~gelman/resear…
を読めば、この論文の著者達が主観確率のベイズ主義の哲学を全否定せざるを得なかった理由がよくわかると思います。
詭弁潰しのために必要な訳です。
#統計 GelmanさんやShaliziさん以外のベイジアンがどのようにおかしなことを言っているかについては、Mayoさんのウェブサイトの
errorstatistics.com/2017/04/01/er-…
がとても面白いです。GelmanさんとShaliziさんは添付画像のように言っている。
真っ当なことを言っている人達の苦労がよくわかる感じ。
errorstatistics.com/2017/04/01/er-…
がとても面白いです。GelmanさんとShaliziさんは添付画像のように言っている。
真っ当なことを言っている人達の苦労がよくわかる感じ。

#統計 論文のGelman-Shalizi (2013)ではそれほど直接的にひどい表現はしていなかったと思うのですが、Gelmanさんは「標準的な主観主義的ベイジアンのやり方は統計学を傷つけてきた」と言ったらしい。Shaliziさんも「ベイズ統計の標準的な哲学の大部分が間違っている」と。
非常にごもっとも。
非常にごもっとも。

#統計 知らない人のために補足しておくと、Gelmanさんは
stat.columbia.edu/~gelman/book/
Bayesian Data Analysis
というベイズ統計の有名な教科書の著者の一人で、Stan開発者の一人でもあります。上の教科書はPDFを誰でもダウンロードできます。
「8割おじさん」の西浦博さん達もStanを使っています。
stat.columbia.edu/~gelman/book/
Bayesian Data Analysis
というベイズ統計の有名な教科書の著者の一人で、Stan開発者の一人でもあります。上の教科書はPDFを誰でもダウンロードできます。
「8割おじさん」の西浦博さん達もStanを使っています。
#統計 Stanを使っている人達は、その開発者の1人でベイズ統計の有名な教科書の筆者が2010年(preprint)に、標準的な主観主義ベイジアンの考え方を否定する論文を書いており、その後も否定する発言を続けていることを思い出しながら、ベイズ統計教育をどうするべきかについて考えるとよいと思います。
#統計 自分自身の能力的にベストの主観確率に基く事前分布から得られる事後分布が、単峰型で非常に狭い範囲にしか分布が広がっていないときに、どう思うかが問題。
穏健で謙虚な合理性を持っていれば「自分自身によるモデル(事前分布を含む)の設定は大外ししているかもしれない」と心配できる。続く
穏健で謙虚な合理性を持っていれば「自分自身によるモデル(事前分布を含む)の設定は大外ししているかもしれない」と心配できる。続く
#統計 しかし、「自分自身のベストの統計分析の結果で、しかも事後分布がいい感じに収束しているのだから、これで十分に合理的である」などと言える余地が残っていて、それに誘惑されてしまうとダークサイドに取り込まれる。
事後分布だけを見ても自分が妥当な統計分析をできているかは分からない。
事後分布だけを見ても自分が妥当な統計分析をできているかは分からない。
#統計 日本語圏では、心理統計の人たちの中に、主観主義ベイジアンの問題のある考え方を広めている人達が目立つ。例の『瀕死本』の豊田秀樹さんが代表例。
騙されないように要注意。
事後分布で計算した「仮説が正しい確率」を真面目に受け取るとトンデモさんになってしまう。続く
騙されないように要注意。
事後分布で計算した「仮説が正しい確率」を真面目に受け取るとトンデモさんになってしまう。続く
#統計 困りもののベイズ主義宣伝者達は「ベイズ統計なら仮説が正しい確率が得られるので分かり易い」などとトンデモないことを平気で言って恥じません。
実際には、事後分布がどのような意味で的を射ているか、いないかは非自明な難しい問題です。(「仮説が正しい確率」は事後分布で計算される。)
実際には、事後分布がどのような意味で的を射ているか、いないかは非自明な難しい問題です。(「仮説が正しい確率」は事後分布で計算される。)
#統計 「事後分布を見ただけでは、まともに統計分析できたかどうかどうかは分からない」とはっきり教わった人だけが、トンデモさんでない人にベイズ統計を教わったことになると思います。
• • •
Missing some Tweet in this thread? You can try to
force a refresh