Das @rki_de hat endlich offizielle Zahlen über den Anteil von #B117 in Deutschland veröffentlicht:
6% für Zeitraum 22.1.-29.1. (ca. vor 1 Woche)
In diesem Thread analysiere ich den Bericht und seine Schwachstellen. 🧵 ⬇️ 1/
rki.de/DE/Content/Inf…
6% für Zeitraum 22.1.-29.1. (ca. vor 1 Woche)
In diesem Thread analysiere ich den Bericht und seine Schwachstellen. 🧵 ⬇️ 1/
rki.de/DE/Content/Inf…

In einem Teil der deutschen Labore (auf welche 57% aller positiven Proben entfiel) wurden 70% der positiven Proben mithilfe spezieller PCR-Tests auf die Variante B.1.1.7 untersucht. Insgesamt also 40% aller positiven Proben zwischen 22.1.-29.1. 2/

Ausschließlich der Anteil der Variante B.1.1.7 (England) wurde bestimmt. Über den Anteil der Variante B.1.351 (Südafrika) kann nur gemutmaßt werden. Diese könnte bis zu 1,1% sein, da 1,1% der Proben die Mutation N501Y aber nicht die Deletion delH69/V70 aufwiesen. 3/

Die Analyse ist geografisch nicht repräsentativ, weil nur ein Teil der Labore in Deutschland teilnahm.
Über die genaue Verteilung lässt sich nur mutmaßen, bis (wenn überhaupt) das RKI die Rohdaten der Untersuchung veröffentlicht.
Weiße Löcher in Grafik sind erster Anhaltspunkt 4/
Über die genaue Verteilung lässt sich nur mutmaßen, bis (wenn überhaupt) das RKI die Rohdaten der Untersuchung veröffentlicht.
Weiße Löcher in Grafik sind erster Anhaltspunkt 4/

Erstes Zwischenfazit (Thread geht weiter):
Wir haben lange auf eine veraltete (1 Woche!), geografisch unrepräsentative Analyse einer einzigen Variante gewartet.
Keine Zeitentwicklung, keine Aufschlüsselung auf Bundesländer/Regionen, keine Daten zu B.1.351. Das geht besser. 5/
Wir haben lange auf eine veraltete (1 Woche!), geografisch unrepräsentative Analyse einer einzigen Variante gewartet.
Keine Zeitentwicklung, keine Aufschlüsselung auf Bundesländer/Regionen, keine Daten zu B.1.351. Das geht besser. 5/
Warum ist es wichtig, dass die Daten veraltet sind? Pro Woche erhöht sich der Anteil von B.1.1.7 um ca. 50-70%! Das heißt, dass die gleiche Studie mit aktuellen Daten mittlerweile einen Anteil von 10% feststellen würde. Das wird sicherlich in den Medien vergessen werden. 6/
Das RKI schreibt, dass die Analyse in KW4 statt fand. Das stimmt nur halb. Freitag der 22.1. fällt eindeutig in KW3. Die Analyse ist also eher KW3-4. Das ist eine Kleinlichkeit, aber das könnte reichen um Aktualität vorzutäuschen.
Warum nicht genau sein und schreiben KW3-KW4? 7/
Warum nicht genau sein und schreiben KW3-KW4? 7/

Der Bericht wertet zusätzlich auch mehrere dem RKI bekannte Sequenzdatensammlungen aus (getrennt voneinander!).
Das Ergebnis ist höchst ernüchternd. Es gibt einen Vergleich der Kalenderjahre mit Datenstand 29.1., die zu überhaupt nichts taugt. 6/
Das Ergebnis ist höchst ernüchternd. Es gibt einen Vergleich der Kalenderjahre mit Datenstand 29.1., die zu überhaupt nichts taugt. 6/
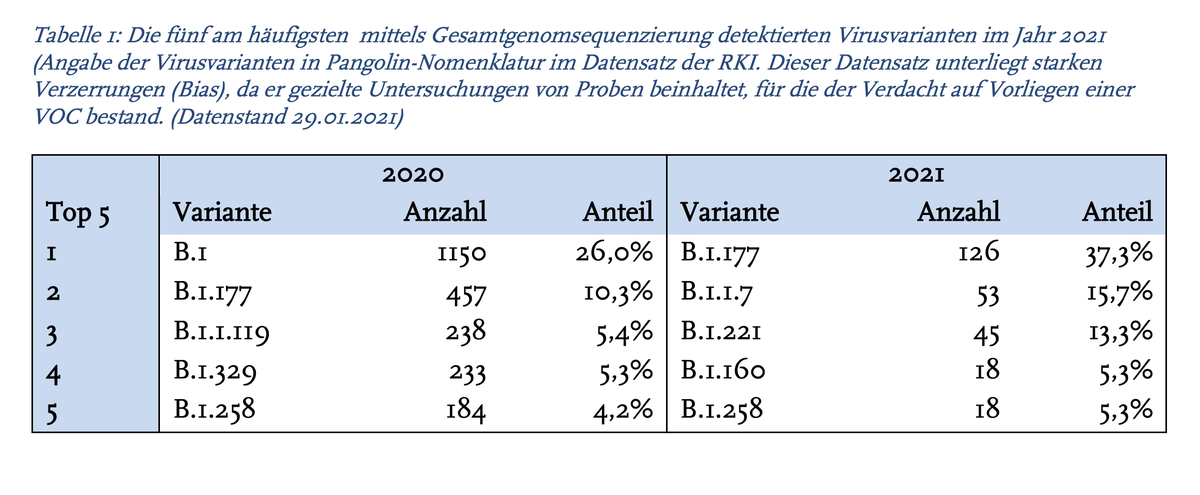
Dazu gibt es eine Grafik, die mehr verwirrt als aufklärt. Hier wird der Anteil verschiedener Varianten pro KW (nur 3!) schön farbig geplottet (Nebelkerze!). Da die Zahlen sehr klein sind, und Sequenzen mit großer Verzögerung ankommen, sieht es so aus als ob #B117 fällt. Fatal! 7/

Seit zwei Wochen, seit der Sequenzierungsverordnung, werden dem RKI jetzt viele aktuelle Sequenzen übermittelt.
Im Bericht werden diese Daten fast völlig ignoriert.
Die Daten werden nicht nach Probendatum analysiert, für eine zeitliche Entwicklung, sondern zusammengeworfen. 10/
Im Bericht werden diese Daten fast völlig ignoriert.
Die Daten werden nicht nach Probendatum analysiert, für eine zeitliche Entwicklung, sondern zusammengeworfen. 10/

Kurzer Exkurs:
Das RKI sagt es habe allein bis zum 1.2. 1308 Sequenzen aus 2021 bekommen. Es wäre extrem wichtig, diese Daten zeitnah mit Wissenschaftlern weltweit über @GISAID zu teilen, um damit unabhängige (bessere) Analysen zu ermöglichen. Bisher: nichts. 11/
Das RKI sagt es habe allein bis zum 1.2. 1308 Sequenzen aus 2021 bekommen. Es wäre extrem wichtig, diese Daten zeitnah mit Wissenschaftlern weltweit über @GISAID zu teilen, um damit unabhängige (bessere) Analysen zu ermöglichen. Bisher: nichts. 11/
Jetzt wird es extrem peinlich. Das RKI hat Tabellen erstellt (Stand 31.1.) mit Zahlen der Varianten-Nachweise (PCR oder Sequenzierung) aus den Bundesländern.
Das Problem: die Zahlen sind falsch, um Faktor 10 (!) zu niedrig. Bsp Bawü:
Laut RKI 20.
Laut Lagebericht BaWü 266. 12/
Das Problem: die Zahlen sind falsch, um Faktor 10 (!) zu niedrig. Bsp Bawü:
Laut RKI 20.
Laut Lagebericht BaWü 266. 12/



Das RKI hat keine Ahnung und null Recherchefähigkeit. Warum sind Tabellen dazu noch 5 Tage alt?
Der Bawü Bericht ist im Internet: gesundheitsamt-bw.de/lga/DE/Fachinf…
Seit 8. Januar tracken wir alle in der Presse gemeldeten Mutationsfälle. Das RKI hat keinen Plan. 13/
Der Bawü Bericht ist im Internet: gesundheitsamt-bw.de/lga/DE/Fachinf…
Seit 8. Januar tracken wir alle in der Presse gemeldeten Mutationsfälle. Das RKI hat keinen Plan. 13/
https://twitter.com/CorneliusRoemer/status/1357385172417675265?s=20
Sind die RKI-Zahlen eine Überraschung? Nein.
Zahlen aus Baden-Württemberg, Schleswig-Holstein, Köln, Solingen zeigen bereits seit mehrere Tagen, dass die Verbreitung von #B117 regional zwischen 5-15% liegt. 14/
Zahlen aus Baden-Württemberg, Schleswig-Holstein, Köln, Solingen zeigen bereits seit mehrere Tagen, dass die Verbreitung von #B117 regional zwischen 5-15% liegt. 14/
https://twitter.com/CorneliusRoemer/status/1357392396288462852?s=20
Damit die Daten des RKIs wirklich nützlich sind, fordere ich das RKI auf, die Rohdaten zu veröffentlichen. Damit könnte man eine Analyse zu regionalen Unterschieden (sehr wichtig!) in der Verbreitung machen, und den Varianten-Anteil mit den Fallzahlen korrelieren. 15/
Für die internationale Wissenschaftscommunity ist die Analyse, so wie sie ist, insbesondere ohne Daten, fast komplett wertlos. Dass D bei ca. 10% Anteil liegt war ohnehin klar. Darüber hinaus ist nichts Interessantes enthalten
Warum nicht wie in DK/UK? 16/
Warum nicht wie in DK/UK? 16/
https://twitter.com/wavecrestthinks/status/1357669138924244994?s=20
Wer wissen will, was der Anteil von 10% für Deutschland in den kommenden Wochen bedeutet, der sei auf diesen Thread verwiesen. Da Köln damals den gleichen Anteil hatte, gelten alle Aussagen genauso für Deutschland als ganzes. 17/
https://twitter.com/CorneliusRoemer/status/1356301674516795393?s=20
Anstatt die Sequenzdaten wirklich zu veröffentlichen, entwirft das RKI lieber eine nette Grafik, die zeigt, wie das RKI plant, die Sequenzdaten zu veröffentlichen. Bahnbrechend! Leider sind immer noch keine Sequenzen bei @GISAID. Spahn versagt. 18/
rki.de/DE/Content/Inf…
rki.de/DE/Content/Inf…

Warum wird diese Untersuchung nur alle zwei Wochen wiederholt? Es sollte ein leichtes sein, zweimal wöchtentlich upzudaten. Das ist wirklich keine Rocket-Science.
Wir müssen auch nicht 34k positive Proben typisieren. 5k reichten völlig. Overengineered bis zur Nutzlosigkeit. 19/
Wir müssen auch nicht 34k positive Proben typisieren. 5k reichten völlig. Overengineered bis zur Nutzlosigkeit. 19/

Hier mein Lieblingszitat von Mike Ryan (WHO Emergency Response Team).
"If you need to be right before you move, you will never win. Perfection is the enemy of the good. In a pandemic, speed trumps perfection."
Das RKI hat das noch nicht verstanden. 20/
"If you need to be right before you move, you will never win. Perfection is the enemy of the good. In a pandemic, speed trumps perfection."
Das RKI hat das noch nicht verstanden. 20/
https://twitter.com/CorneliusRoemer/status/1357310819546062849?s=20
Hier zeigt sich direkt, wie der RKI-Bericht aufgrund schlechter Daten-Auswahl und -Visualisierung Zweifel säht, wo gar keine sind.
Die Daten sind so alt (31.1.), wie konnte da niemand drüber schauen und sagen: lasst das raus, das ist missverständlich! 21/
Die Daten sind so alt (31.1.), wie konnte da niemand drüber schauen und sagen: lasst das raus, das ist missverständlich! 21/
https://twitter.com/thomas_wachtler/status/1357639303682211840?s=20

Weitere Fragezeichen aus der Pressekonferenz.
Weiß beim RKI wirklich niemand, wie die Konvention für die Benennung der Varianten ist? Liest niemand die Reden von Wieler Kontrolle? 21/
Weiß beim RKI wirklich niemand, wie die Konvention für die Benennung der Varianten ist? Liest niemand die Reden von Wieler Kontrolle? 21/
https://twitter.com/CorneliusRoemer/status/1357720825735053314?s=20
Dies ist, wie das RKI die (Sequenz-)Daten in Deutschland analysieren sollte. Ist das so schwer? 23/
https://twitter.com/C_Althaus/status/1357732521602088967?s=20
Wielers Falschaussagen sind kritisch, weil sie direkt von den Medien in die Schlagzeilen übernommen werden - ohne Kritik oder Einordnung. Das ist fatal! Ich bin es leid, dass führende Medien wie @tagesschau Minister/Behörden blindlings zitieren. 24/
https://twitter.com/CorneliusRoemer/status/1357765377074360324?s=20

Die tagesaktuellen (!) Baden-Württembergischen Daten stützen die Arbeitshypothese, dass der momentan Anteil von Mutanten in Deutschland bei ca. 9% liegt, statt 6%
25/
25/
https://twitter.com/CorneliusRoemer/status/1357772953396600836?s=20
Hoffentlich werden Entscheidungen nächste Woche nicht auf Basis der 6% gemacht. Wünsche mir, dass beratende Wissenschaftler wie @rki_de Wieler, @c_drosten, @Karl_Lauterbach klar machen dass wir dann bei 10+% sind. 26/
https://twitter.com/Jssy_Lnn/status/1357773357278781443?s=20
Im Raum München ist der Mutanten-Anteil laut @LaborBecker bei 18,4%, Stand 4.2., das ist plausibel.
Vielen Dank an das Labor, dass es die Daten veröffentlicht. Wir können uns nicht auf das Faultier @rki_de verlassen!
h/t @Stina2312 27/
Vielen Dank an das Labor, dass es die Daten veröffentlicht. Wir können uns nicht auf das Faultier @rki_de verlassen!
h/t @Stina2312 27/
https://twitter.com/LaborBecker/status/1357737258137354240?s=20
Hier sind die Ergebnisse aus München im Zeitverlauf. Das ist nur eine Stichprobe und relativ rauschig, passt aber in den Gesamtkontext. In München gibt's also sehr bald einen starken Anstieg von R um 0,3. 28/

Wer denkt meine Kritik am RKI-Bericht sei kleinlich, der sehe sich an, was passiert, wenn missverständliche Grafiken in die Hände von Schwurblern gelangen. Das war total unnötig, die Grafik musste wirklich nicht in den Bericht. /29
https://twitter.com/CorneliusRoemer/status/1357669053599539212?s=19

Übrigens möchte ich klarstellen, dass meine RKI-Kritik dem System und den Prozessen gilt, nicht den Mitarbeitern, die sich sicher den Arsch für uns aufreißen.
Verantwortlich ist zuallererst @jensspahn, der das @rki_de nicht ausreichend mit Personal ausstattet in der Krise. 30/
Verantwortlich ist zuallererst @jensspahn, der das @rki_de nicht ausreichend mit Personal ausstattet in der Krise. 30/

• • •
Missing some Tweet in this thread? You can try to
force a refresh