
Day 12 of #31DaysofML
I played with Teachable Machine today and created a #nocode classification model in less than 5 mins! It's a web-based tool making #machinelearning models fast, easy, and accessible to everyone.
See how I created a yoga pose classification model 🧵👇
I played with Teachable Machine today and created a #nocode classification model in less than 5 mins! It's a web-based tool making #machinelearning models fast, easy, and accessible to everyone.
See how I created a yoga pose classification model 🧵👇
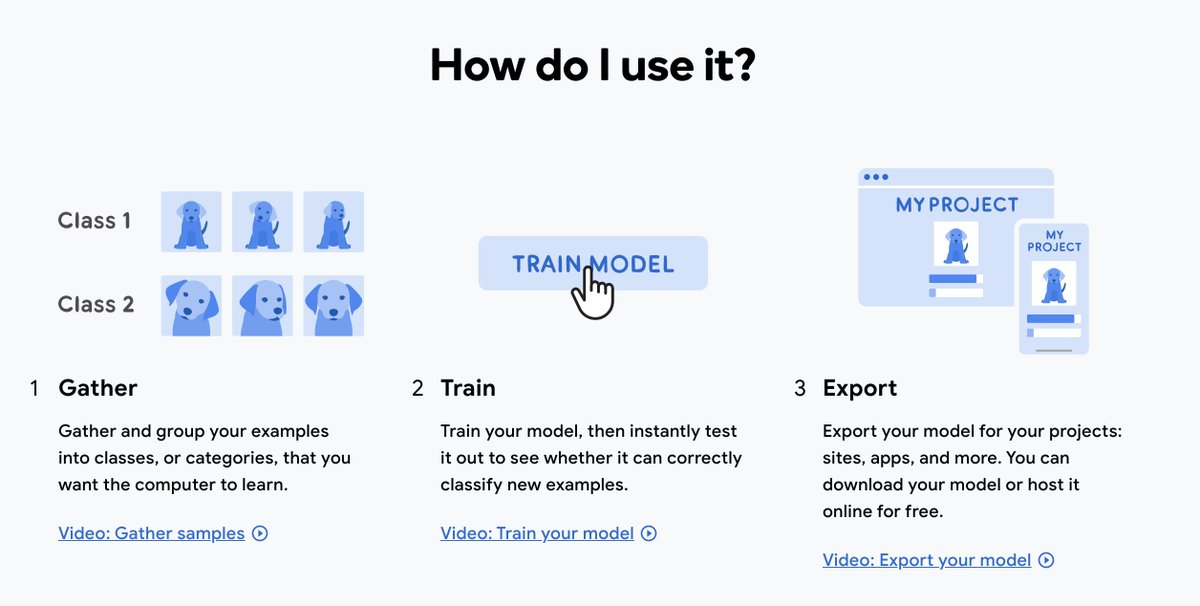
🤔 How to use Teachable Machines?
📌Gather data (upload it or use webcam/microphone)
📌Train model (in the web interface)
📌Export the model (use it in your app)
🤔 What type of data can I use to train the model?
🖼 Images
🔊 Sounds
🧘♀️ Poses
#31DaysofML
📌Gather data (upload it or use webcam/microphone)
📌Train model (in the web interface)
📌Export the model (use it in your app)
🤔 What type of data can I use to train the model?
🖼 Images
🔊 Sounds
🧘♀️ Poses
#31DaysofML
Now, get out of your chair 🪑 and try out my yoga 🧘♀️ pose classification model with any of these poses:
📌 Goddess
📌 Warrior2
📌 Tree
📌 Downdog
Here is my model 👉 teachablemachine.withgoogle.com/models/vkzpnwt…
#31DaysofML
📌 Goddess
📌 Warrior2
📌 Tree
📌 Downdog
Here is my model 👉 teachablemachine.withgoogle.com/models/vkzpnwt…
#31DaysofML
• • •
Missing some Tweet in this thread? You can try to
force a refresh







