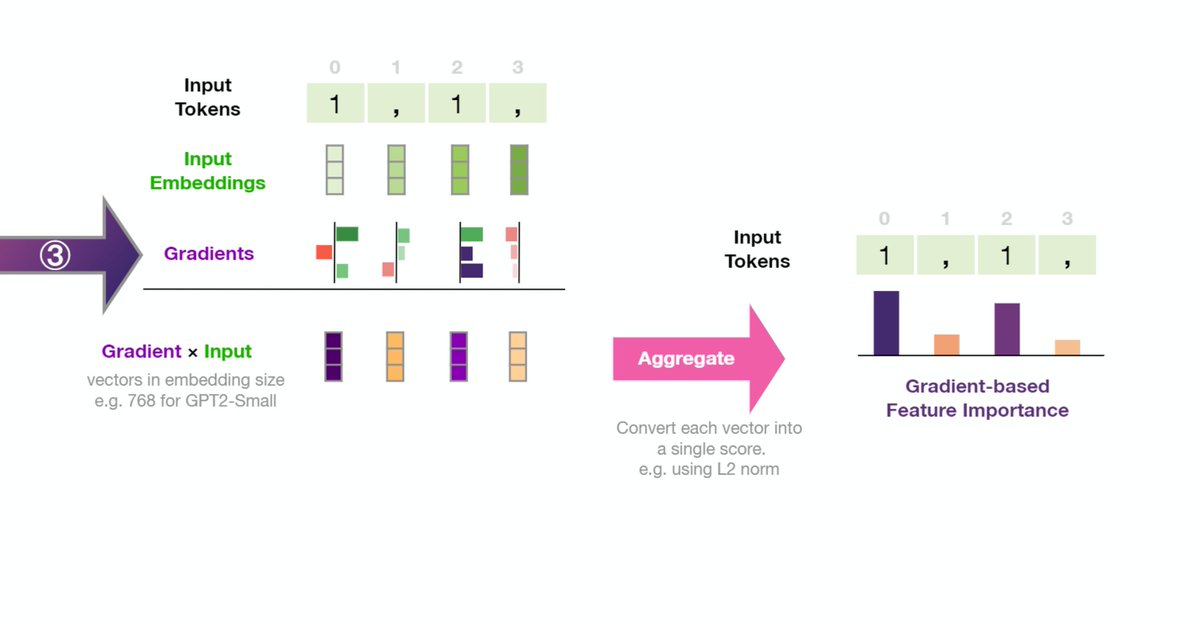
Einsum is a key method in summing and multiplying tensors. It's implemented in @numpy_team , @TensorFlow , AND @PyTorch. Here's a visual intro to Einstein summation functions.
1/n
1/n

The einsum expression has two components.
1) Subscripts string -- notation indicating what we want to do with the input arrays.
2) The input arrays. It can be one or more arrays/tensors of varying dimensions.
1) Subscripts string -- notation indicating what we want to do with the input arrays.
2) The input arrays. It can be one or more arrays/tensors of varying dimensions.

The subscript follows the notation of mathematical formulas.
Here's an example of of summing the rows of one array.
Einsum sees that
1) The input array has two dimensions.
2)The subscripts have two unique letters.
It assigns the letters to the axes.
And then sums
Here's an example of of summing the rows of one array.
Einsum sees that
1) The input array has two dimensions.
2)The subscripts have two unique letters.
It assigns the letters to the axes.
And then sums

This is how the subscripts correspond to the important pieces of information in the mathematical formula.

This is how it maps for multiplication. The comma indicates multiplication. It is necessary when we pass more than one array/tensor to einsum.
A lot more examples in @_rockt's excellent post: rockt.github.io/2018/04/30/ein…
A lot more examples in @_rockt's excellent post: rockt.github.io/2018/04/30/ein…

• • •
Missing some Tweet in this thread? You can try to
force a refresh