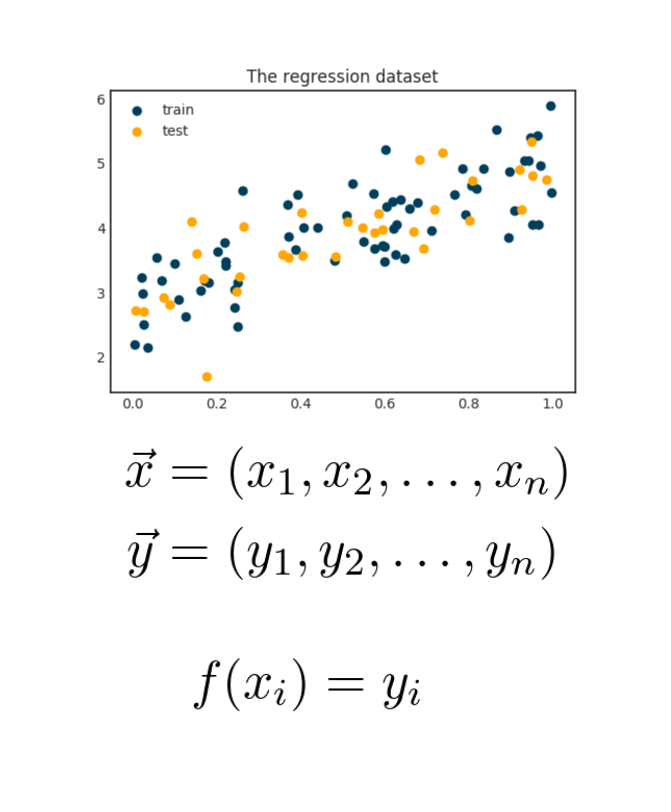
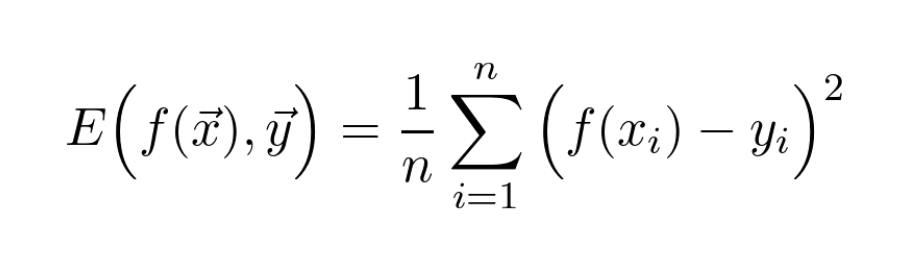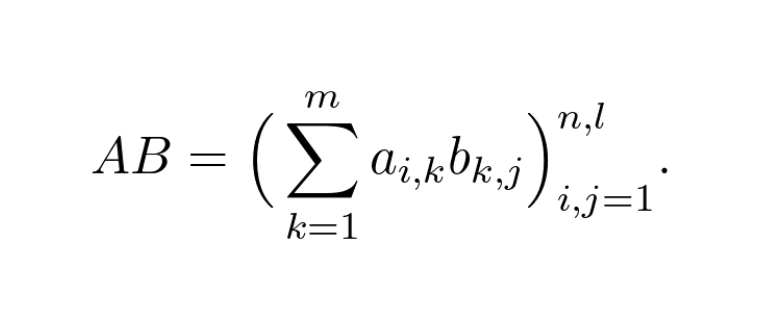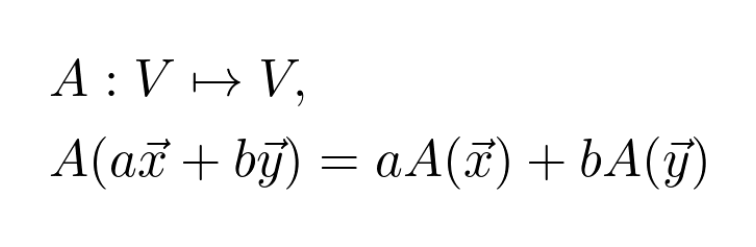It is the weekend now, so let's talk about something different, but still awesome and beautiful!
This image has been my desktop wallpaper for years.
Can you guess what is it?
This machine represents one of the most brilliant ideas I have seen. (Answer in the next tweet.)
This image has been my desktop wallpaper for years.
Can you guess what is it?
This machine represents one of the most brilliant ideas I have seen. (Answer in the next tweet.)

This is the Wankel engine, a surprisingly innovative type of internal combustion engines.
Why is it so brilliant? In short, because it parallelizes the classical four-stage Otto cycle, all in one chamber!
To elaborate a bit, let's see how a four-stroke piston engine works!
Why is it so brilliant? In short, because it parallelizes the classical four-stage Otto cycle, all in one chamber!
To elaborate a bit, let's see how a four-stroke piston engine works!
The common four-stroke piston engine essentially has four stages:
1. Intake
2. Compression
3. Combustion
4. Exhaust
These happen in sequence inside a cylinder-shaped chamber, as shown below.
(Gifs and images in the thread are all from Wikipedia.)
1. Intake
2. Compression
3. Combustion
4. Exhaust
These happen in sequence inside a cylinder-shaped chamber, as shown below.
(Gifs and images in the thread are all from Wikipedia.)
The Wankel engine performs the same "strokes", but all stages are present simultaneously in its chamber!
What makes it possible is the shape its rotor. That shape is called the Reuleaux triangle, and it has a very special property: it has constant width.
What makes it possible is the shape its rotor. That shape is called the Reuleaux triangle, and it has a very special property: it has constant width.
Constant width means that no matter how you squeeze the it between two parallel lines, the distance between those will always be the same.
(One other constant width shape is the circle, but the Reuleaux triangle is far more exciting.)
(One other constant width shape is the circle, but the Reuleaux triangle is far more exciting.)
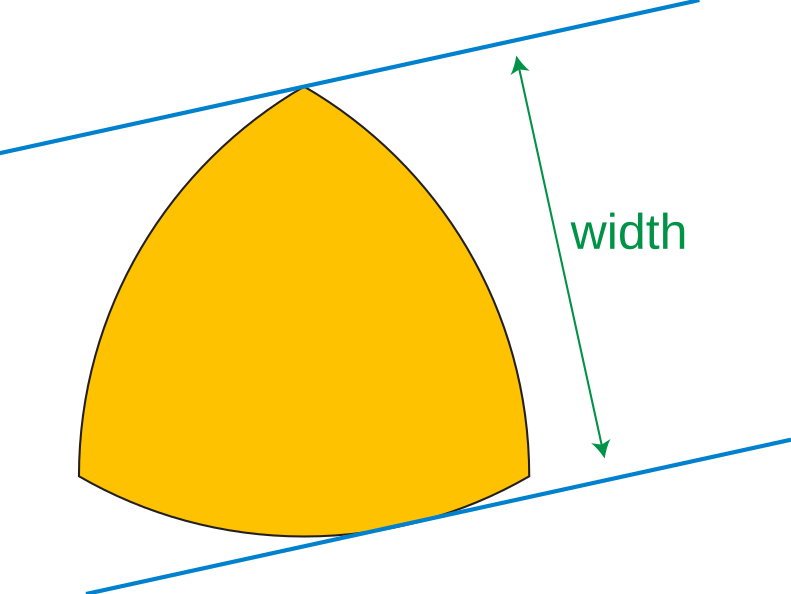
Notice how the constant width enables the rotating motion to perform all steps of the cycle in the chamber simultaneously.
Each revolution yields three power pulses.
Why do I find this particular idea so beautiful and elegant?
Each revolution yields three power pulses.
Why do I find this particular idea so beautiful and elegant?
Essentially, the Wankel engine takes a one-dimensional motion of the piston engine and lays it out on the plane, translating it into rotation.
It doesn't parallelize the cycle by adding more pistons, but cleverly creates a symmetry where the steps are simultaneously present.
It doesn't parallelize the cycle by adding more pistons, but cleverly creates a symmetry where the steps are simultaneously present.
Unfortunately, it turned out that in practice, the Wankel engine is not effective and has several disadvantages.
Nonetheless, it doesn't diminish its brilliance at all.
What is the idea that makes you amazed the most?
Nonetheless, it doesn't diminish its brilliance at all.
What is the idea that makes you amazed the most?
• • •
Missing some Tweet in this thread? You can try to
force a refresh