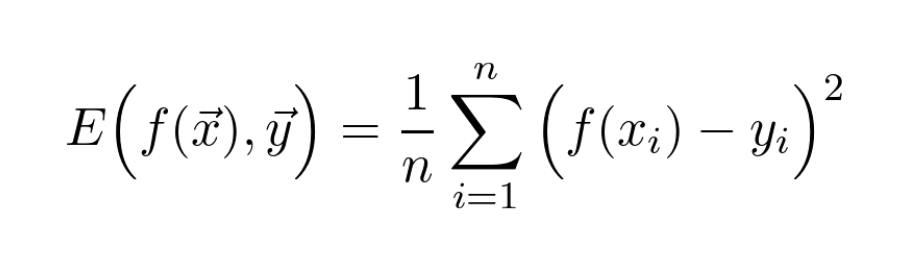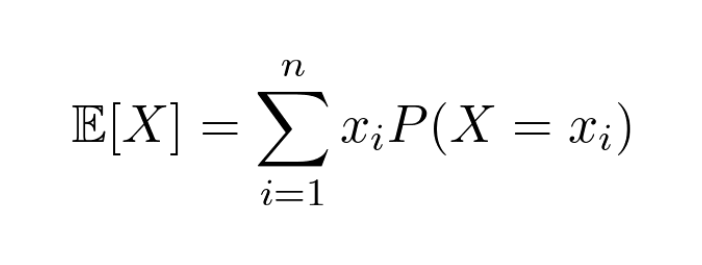What makes it possible to train neural networks with gradient descent?
The fact that the loss function of a network is a differentiable function!
Differentiation can be hard to understand. However, it is an intuitive concept from physics.
💡 Let's see what it really is! 💡
The fact that the loss function of a network is a differentiable function!
Differentiation can be hard to understand. However, it is an intuitive concept from physics.
💡 Let's see what it really is! 💡

Differentiation essentially describes a function's rate of change.
Let's see how!
Suppose that we have a tiny object moving along a straight line back and forth.
Its movement is fully described by its distance from the starting point, plotted against the time.
Let's see how!
Suppose that we have a tiny object moving along a straight line back and forth.
Its movement is fully described by its distance from the starting point, plotted against the time.

What is its average speed in its 10 seconds of travel time?
The average speed is simply defined as the ratio of distance and time.
However, it doesn't really describe the entire movement. As you can see, the speed is sometimes negative, sometimes positive.
The average speed is simply defined as the ratio of distance and time.
However, it doesn't really describe the entire movement. As you can see, the speed is sometimes negative, sometimes positive.

Fortunately, we don't need to restrict ourselves to the global average.
Speed can be calculated locally as well!
Let's say we want to calculate the speed at the time 𝑥 = 2.5.
So, we pick an 𝑦 and work our way from there!
Speed can be calculated locally as well!
Let's say we want to calculate the speed at the time 𝑥 = 2.5.
So, we pick an 𝑦 and work our way from there!

We can calculate the average speed in the time interval [𝑥, 𝑦] as before, this time using the following formula.
(𝑓 denotes the time-distance function.)
If you think about it, the average speed is just the slope of the line between (𝑥, 𝑓(𝑥)) and (𝑦, 𝑓(𝑦))).
(𝑓 denotes the time-distance function.)
If you think about it, the average speed is just the slope of the line between (𝑥, 𝑓(𝑥)) and (𝑦, 𝑓(𝑦))).

As we move 𝑦 closer and closer to 𝑥, the average speed will also be getting closer to the actual speed during time 𝑥.
If the limit of the average speeds exists, we call it the derivative.
Taking the derivative of a function is called differentiation.
It is that simple.
If the limit of the average speeds exists, we call it the derivative.
Taking the derivative of a function is called differentiation.
It is that simple.

Essentially, this quantity gives the exact speed at a specific time instant.
If we keep the geometric interpretation in mind, the derivative is essentially the tangent line's slope.
If we keep the geometric interpretation in mind, the derivative is essentially the tangent line's slope.

The derivatives do not always exist necessarily.
The simplest example would be the absolute value function defined by 𝑓(𝑥) = |𝑥|, at 𝑥 = 0.
However, when it does exist, it gives us a ton of advantages. For instance, we can use it for optimization.
The simplest example would be the absolute value function defined by 𝑓(𝑥) = |𝑥|, at 𝑥 = 0.
However, when it does exist, it gives us a ton of advantages. For instance, we can use it for optimization.
For local minima and maxima, the derivative must be zero. This is used to find the optima of the function.
For multivariate functions (like the loss function of a neural network), the derivatives show the direction of the largest decrease.
This is how gradient descent works!
For multivariate functions (like the loss function of a neural network), the derivatives show the direction of the largest decrease.
This is how gradient descent works!
Without any doubt, the invention of differentiation by Newton is on par with the invention of the wheel or electricity.
This concept lies at the core of modern mathematics, enabling various things like aviation, epidemiology, or machine learning.
This concept lies at the core of modern mathematics, enabling various things like aviation, epidemiology, or machine learning.
So, derivatives are not complicated at all. By looking at it from this viewpoint, the definition suddenly makes a lot more sense!
What do you think?
If you have any questions, feel free to let me know in the replies!
What do you think?
If you have any questions, feel free to let me know in the replies!
• • •
Missing some Tweet in this thread? You can try to
force a refresh