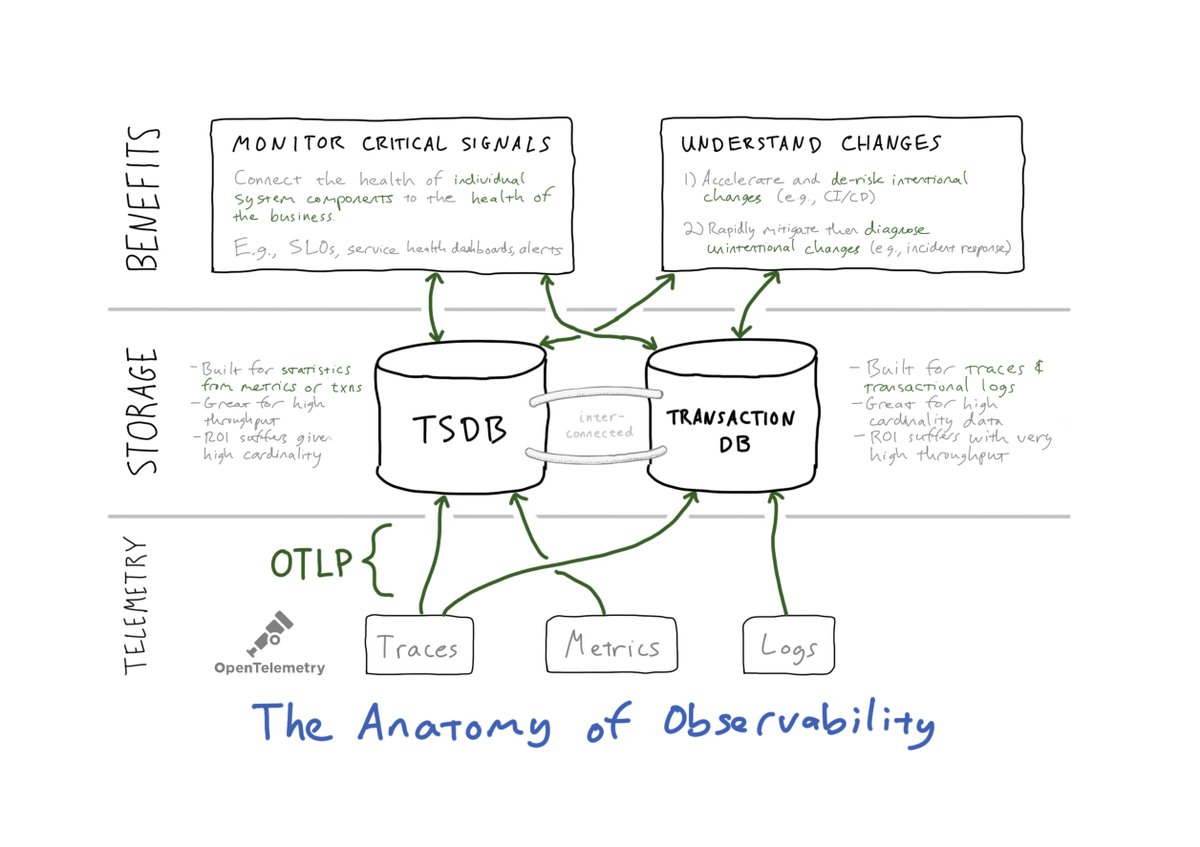
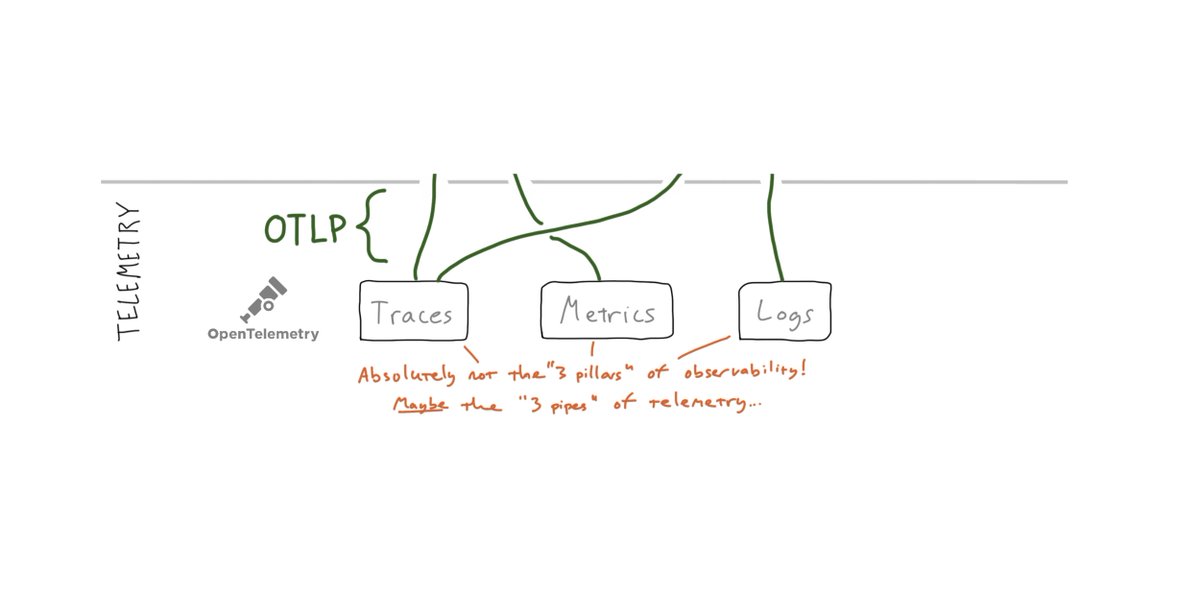
0/ If you or someone you love uses Kafka in production, I’m sure there’s been some emotional toil when a single producer floods a topic and creates a cascading failure.
This is a 🧵 about how monitoring and observability can make that far less painful.
👇
This is a 🧵 about how monitoring and observability can make that far less painful.
👇

1/ At a certain level, Kafka is just like any other resource in your system: e.g., your database’s CPUs, your NICs, or your RAM reservations.
All resources are finite, and when they participate in transactions, there is a little bit less of them than when they don’t.
All resources are finite, and when they participate in transactions, there is a little bit less of them than when they don’t.
2/ The reason that Kafka failures are so spectacular isn’t all Kafka’s fault: it’s just that it takes on a role nearly as essential as the network itself, and so when it breaks it can take your app with it. New failure modes get discovered the hard way, and everybody loses. 📉
3/ (Side note: I remember networking failures being much more of “a thing” in the early 2000s than they are today – in terms of reliability scar tissue, maybe Kafka really *is* the new network?)
4/ In any case, when Kafka gets overloaded, the immediate question on everyone’s mind is actually the central question of observability: “what caused that change?”
(Side note: More on that subject here →
(Side note: More on that subject here →
https://twitter.com/el_bhs/status/1349406414138003457)
5/ This is hard, though, as “the change” we’re investigating here is in these rather opaque Kafka lag metrics, but “the cause “ (or at least the main contributing factor) has to do with *the workload*: i.e., some actual shift in the *usage* of Kafka.
6/ What I’m going to show next is part of @LightstepHQ’s product, but this isn’t meant as a pitch as much as it’s meant as a way to make all of this more concrete.
Along those lines, let’s start with a *real* Kafka issue from our own SaaS as an example:
Along those lines, let’s start with a *real* Kafka issue from our own SaaS as an example:
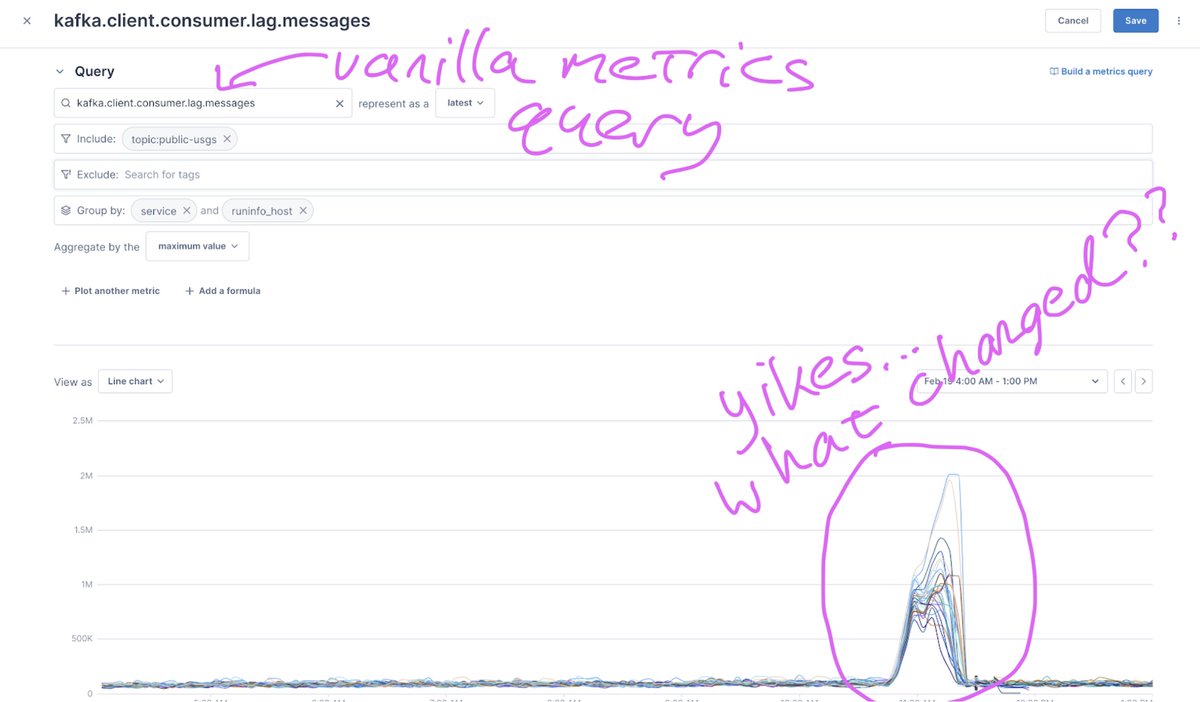
7/ To set context, this chart is from a completely “boring” metrics query in Lightstep’s own self-hosted meta-monitoring. We’re taking Kafka consumer lag, filtering by a specific Kafka topic of interest, doing a group-by, and visualizing the results.
8/ These results are also mostly “boring” – except for the one period of about 45 minutes where they were unfortunately extremely not-boring!
Yikes – and again, “what changed?”
Yikes – and again, “what changed?”
9/ IMO this is the point at which normal/conventional monitoring tools fail us.
The by-far most important question (about change) is, in fact, *basically un-answerable* within any siloed metrics product.
But what if you could just click on the anomaly?
The by-far most important question (about change) is, in fact, *basically un-answerable* within any siloed metrics product.
But what if you could just click on the anomaly?

10/ So, here we *can* just click on the anomaly, even in a plain-old metrics chart like this one. I.e., the Kafka anomaly itself becomes *actionable*, and we can bridge directly to a guided analysis of the Kafka *workload*.
11/ Having clicked on that “what changed?” button, we’re taken to a dedicated “change intelligence” UX. Above the fold we see the metric in question – the Kafka consumer lag – with both the deviation (where we clicked) and an automated baseline pre-selected for us:

12/ And then with literally no other typing or user input – nor any special configuration in the system itself – true change-oriented observability can *show us how the Kafka workload shifted during the deviation*, like this:

13/ What we’re seeing here is *a single customer* within suddenly jumping from 0.86% of the workload to 15.95% of the workload.
And that’s why the message lag increased. We have *just* started investigating and already have our smoking gun – and a high-cardinality one to boot!
And that’s why the message lag increased. We have *just* started investigating and already have our smoking gun – and a high-cardinality one to boot!

14/ With conventional tooling, diagnosing Kafka resource contention is extremely challenging, particularly when it’s due to a workload change like in this real-world example.
But here it’s not so daunting, even days after the fact.
But here it’s not so daunting, even days after the fact.
15/ And if we want to know *what* those single-customer transactions were doing, we can just look:

16/ So that’s it. Kafka is useful and valuable, but it’s invariably a shared dependency and can fail in spectacular ways – with modern observability, at least we have a clean shot at understanding why, and quickly.
• • •
Missing some Tweet in this thread? You can try to
force a refresh