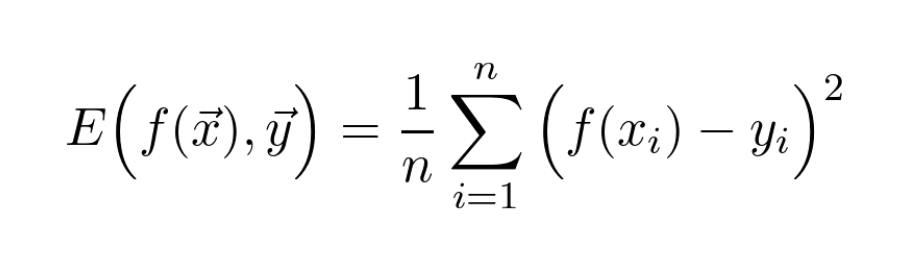Have you ever thought about why neural networks are so powerful?
Why is it that no matter the task, you can find an architecture that knocks the problem out of the park?
One answer is that they can approximate any function with arbitrary precision!
Let's see how!
🧵 👇🏽
Why is it that no matter the task, you can find an architecture that knocks the problem out of the park?
One answer is that they can approximate any function with arbitrary precision!
Let's see how!
🧵 👇🏽

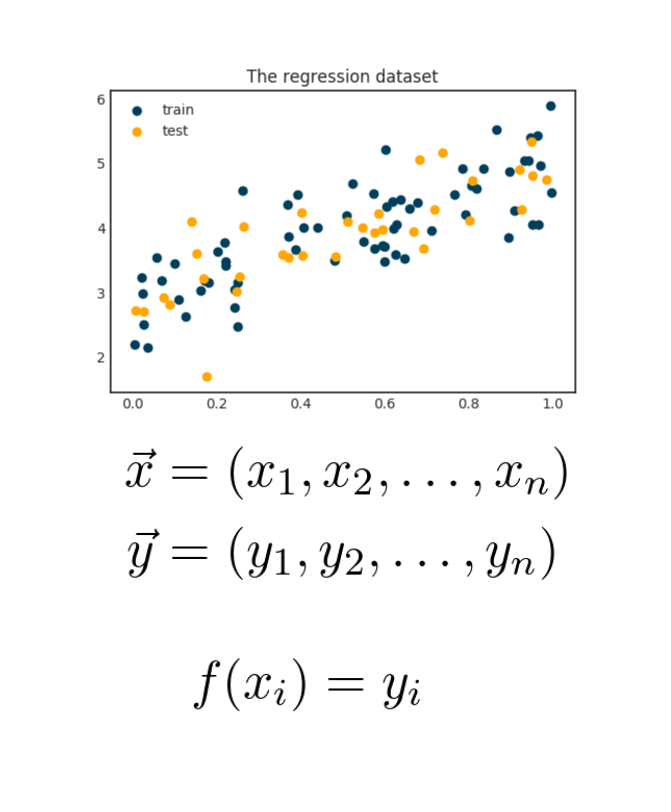
From a mathematical viewpoint, machine learning is function approximation.
If you are given data points 𝑥 with observations 𝑦, learning essentially means finding a function 𝑓 such that 𝑓(𝑥) approximates the given 𝑦-s as accurately as possible.
If you are given data points 𝑥 with observations 𝑦, learning essentially means finding a function 𝑓 such that 𝑓(𝑥) approximates the given 𝑦-s as accurately as possible.
Approximation is a very natural idea in mathematics.
Let's see a simple example!
You probably know the exponential function well. Do you also know how to calculate it?
The definition itself doesn't really help you. Calculating the powers where 𝑥 is not an integer is tough.
Let's see a simple example!
You probably know the exponential function well. Do you also know how to calculate it?
The definition itself doesn't really help you. Calculating the powers where 𝑥 is not an integer is tough.

The solution is to approximate the exponential function with one that we can calculate easier.
Here, we use a polynomial for this purpose.
The larger 𝑛 is, the closer the approximation is to the true value.
Here, we use a polynomial for this purpose.
The larger 𝑛 is, the closer the approximation is to the true value.

The central problem of approximation theory is to provide a mathematical framework for these problems.
So, let's formulate this in terms of neural networks!
Suppose that there is an underlying function 𝑔(𝑥) that describes the true relation between data and observations.
So, let's formulate this in terms of neural networks!
Suppose that there is an underlying function 𝑔(𝑥) that describes the true relation between data and observations.
Our job is to find an approximating function f(x) that
• generalizes the knowledge from the data,
• and is computationally feasible.
If we assume that all of our data points are in the set 𝑋, we would like a function where the quantity 𝑠𝑢𝑝𝑟𝑒𝑚𝑢𝑚 𝑛𝑜𝑟𝑚.
• generalizes the knowledge from the data,
• and is computationally feasible.
If we assume that all of our data points are in the set 𝑋, we would like a function where the quantity 𝑠𝑢𝑝𝑟𝑒𝑚𝑢𝑚 𝑛𝑜𝑟𝑚.

You can imagine this quantity by plotting the functions, coloring the area enclosed by the graph and calculating the maximum spread of said area along the 𝑦 axis.

Mathematically speaking, a neural network with a single hidden layer is defined by the formula below, where φ can be any activation function, like the famous sigmoid.
It checks our second criteria: it is easy to compute.
It checks our second criteria: it is easy to compute.

What about the other one? Is this function family enough to approximate any reasonable function?
This question is answered by the 𝑢𝑛𝑖𝑣𝑒𝑟𝑠𝑎𝑙 𝑎𝑝𝑝𝑟𝑜𝑥𝑖𝑚𝑎𝑡𝑖𝑜𝑛 𝑡ℎ𝑒𝑜𝑟𝑒𝑚, straight from 1989.
Let's see what it says!
This question is answered by the 𝑢𝑛𝑖𝑣𝑒𝑟𝑠𝑎𝑙 𝑎𝑝𝑝𝑟𝑜𝑥𝑖𝑚𝑎𝑡𝑖𝑜𝑛 𝑡ℎ𝑒𝑜𝑟𝑒𝑚, straight from 1989.
Let's see what it says!

(The result appeared in the paper
Cybenko, G. (1989) “Approximations by superpositions of sigmoidal functions”, Mathematics of Control, Signals, and Systems, 2(4), 303–314.
You can find it here: citeseerx.ist.psu.edu/viewdoc/downlo…)
Cybenko, G. (1989) “Approximations by superpositions of sigmoidal functions”, Mathematics of Control, Signals, and Systems, 2(4), 303–314.
You can find it here: citeseerx.ist.psu.edu/viewdoc/downlo…)
Essentially, this means that as long as the activation function is sigmoid-like and the function to be approximated is continuous, a neural network with a single hidden layer can approximate it as precisely as you want.
(Or 𝑙𝑒𝑎𝑟𝑛 it in machine learning terminology.)
(Or 𝑙𝑒𝑎𝑟𝑛 it in machine learning terminology.)

Notice that the theorem is about neural networks with a single hidden layer.
This is actually not a restriction. The general case with multiple hidden layers case follows easily from this.
However, proving the theorem is easier in this simple situation.
This is actually not a restriction. The general case with multiple hidden layers case follows easily from this.
However, proving the theorem is easier in this simple situation.
There are certain caveats.
The main issue is that the theorem doesn't say anything about 𝑁, that is, the number of hidden neurons.
If you want a close approximation, 𝑁 can be really large.
From a computational perspective, this is highly suboptimal.
The main issue is that the theorem doesn't say anything about 𝑁, that is, the number of hidden neurons.
If you want a close approximation, 𝑁 can be really large.
From a computational perspective, this is highly suboptimal.
But this is not the only problem.
In practice, we have incomplete information about the function to be approximated. (This information is represented by our dataset.)
If we make our approximation too precise, we are overfitting on our dataset.
In practice, we have incomplete information about the function to be approximated. (This information is represented by our dataset.)
If we make our approximation too precise, we are overfitting on our dataset.
This is the same problem you might have when trying to fit a polynomial curve to the dataset.

Overall, the universal approximation theorem is a theoretical result, providing a solid foundation for neural networks.
Without this, they wouldn't be as powerful as they are.
Without this, they wouldn't be as powerful as they are.
• • •
Missing some Tweet in this thread? You can try to
force a refresh