
#超算数 【「1セットあたりの量」と「○セット」という概念の定着を目的にあえて縛りを設けていると考えれば納得.】とか言うお馬鹿さん達が継続して出て来ることが昔からよく知られています。
かけ算順序固定強制指導が実際に有害であることの間接的な証拠とみなせると思う。続く
かけ算順序固定強制指導が実際に有害であることの間接的な証拠とみなせると思う。続く
https://twitter.com/ryuyengineer/status/1372177005353955334
#超算数 現実の子供に関しては、同じ数を含む集まりが何セットあるかの状況把握と掛け算順序マスターであることは、現場の教師の調査で関係ないことが分かっています。
そして、その教師は、関係ないことを認めた上で、掛け算順序強制指導を強化しなければいけないと主張しています。
これが現実。
そして、その教師は、関係ないことを認めた上で、掛け算順序強制指導を強化しなければいけないと主張しています。
これが現実。
https://twitter.com/genkuroki/status/1299940520265830400
#超算数 掛け算順序が逆なら誤りとみなしたり、掛け算順序が逆なら理解していないとみなす行為は、算数教育の世界では100年以上の伝統を持っています。
これだけの伝統があると、掛け算順序指導が社会的に否定されると困る人達が沢山いることもよく分かる。
しかし、被害者は次世代を担う子供達。
これだけの伝統があると、掛け算順序指導が社会的に否定されると困る人達が沢山いることもよく分かる。
しかし、被害者は次世代を担う子供達。
https://twitter.com/genkuroki/status/1267851912566599681
#超算数 算数について非常識な考え方をマスターしているおかげで、算数教育関係の要職に就けた人達が沢山います。
教育委員会や算数・数学教育の学会や教科書執筆者の中にそういう人達がいる。
そういう人達にとって子供の害になる算数の教え方が有名になって否定されるのは都合が悪いことなのです。
教育委員会や算数・数学教育の学会や教科書執筆者の中にそういう人達がいる。
そういう人達にとって子供の害になる算数の教え方が有名になって否定されるのは都合が悪いことなのです。
これを言うと、「なんだ、こいつ。頭が狂っているんじゃないか?」と思われてしまうリスクがあります。
しかし、出版済みの多くの文献の中に、大変なことになっていることを示す証拠が見つかっている。
私も納得するまで10年以上かけているので、私を狂った人扱いしたくなる人の気持ちもよくわかる。
しかし、出版済みの多くの文献の中に、大変なことになっていることを示す証拠が見つかっている。
私も納得するまで10年以上かけているので、私を狂った人扱いしたくなる人の気持ちもよくわかる。
逆に言えば、算数教育の世界がこれだけ悲惨なことになっているのに、我々はうまくやって来ているとも言えるわけです。これが我々の社会の地力。(私は日本では伝統的に塾が盛んであることが関係していると予想している。)
算数教育がまともになればもっとうまくやって行けるようになると思います。
算数教育がまともになればもっとうまくやって行けるようになると思います。
#超算数 「交換法則の証明が問題になっている」という事実はありません。「思う」だけでなく、「調べる」が大事。
教科書を見ても小2でかけ算の交換法則について教えることに困難が生じてなさそうなことがわかる(添付画像)。
実際には交換法則を教えた後に掛け算順序固定強制指導が強化されます。
教科書を見ても小2でかけ算の交換法則について教えることに困難が生じてなさそうなことがわかる(添付画像)。
実際には交換法則を教えた後に掛け算順序固定強制指導が強化されます。
https://twitter.com/ryuyengineer/status/1372482333094281216


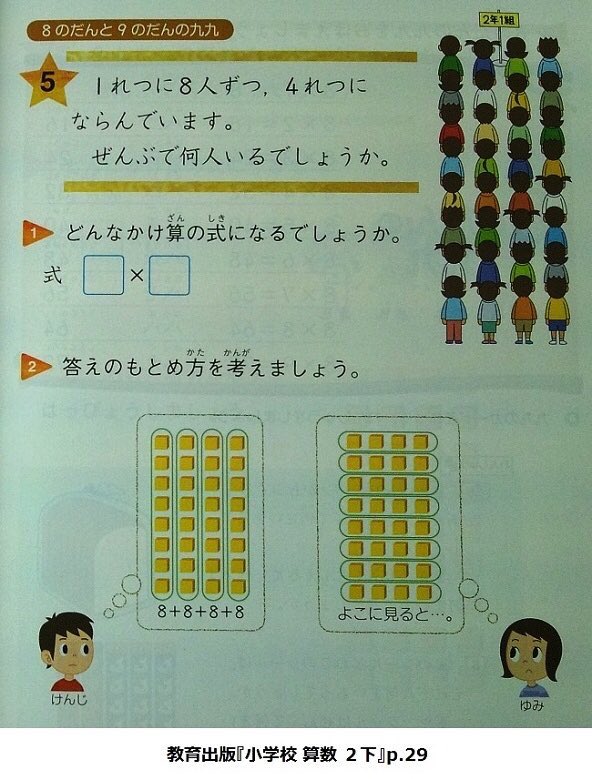

#超算数 添付画像は2011年頃の小2算数教科書より。
邪悪な点:「かけられる数とかける数の立場を常にひっくり返せる」と正しい考え方を言い切らずに、「答えは同じ」という言い方になっている。
「式と答え」で考えるチョー算数の非常識なスタイルがここでも見られる。
邪悪な点:「かけられる数とかける数の立場を常にひっくり返せる」と正しい考え方を言い切らずに、「答えは同じ」という言い方になっている。
「式と答え」で考えるチョー算数の非常識なスタイルがここでも見られる。




#超算数 小2でかけ算の交換法則が一般的に成立する仕組みを教えた直後に、掛け算順序固定強制指導が本格化している場合については添付画像を参照。
掛け算順序固定強制指導を実行して子供を害している教師は交換法則もしっかり教えた上でそうしているのです。
ほんと最悪。
掛け算順序固定強制指導を実行して子供を害している教師は交換法則もしっかり教えた上でそうしているのです。
ほんと最悪。
https://twitter.com/genkuroki/status/1203537173695344643



• • •
Missing some Tweet in this thread? You can try to
force a refresh









