StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery 🔥
Use CLIP model in order to navigate image editing in StyleGAN by text queries.
📝Paper arxiv.org/abs/2103.17249
⚙️ code github.com/orpatashnik/St…
Thread 👇
Use CLIP model in order to navigate image editing in StyleGAN by text queries.
📝Paper arxiv.org/abs/2103.17249
⚙️ code github.com/orpatashnik/St…
Thread 👇


1/
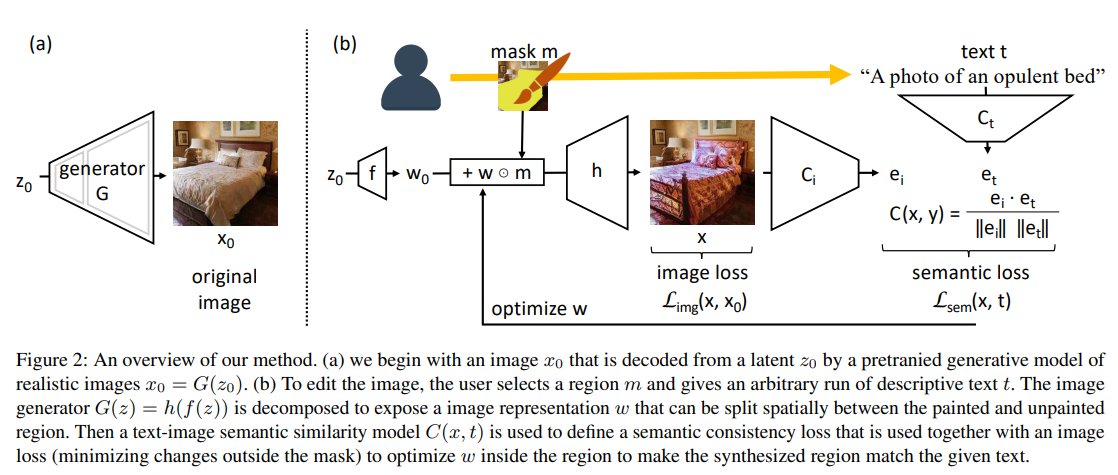
🛠️How?
1. Take pretrained CLIP, pretrained StyleGAN, and pretrained ArcFace network for face recognition.
2. Project an input image in StyleGAN latent vector w_s.
...
🛠️How?
1. Take pretrained CLIP, pretrained StyleGAN, and pretrained ArcFace network for face recognition.
2. Project an input image in StyleGAN latent vector w_s.
...

2/
3. Now, given a source latent code w_s∈ W+, and a directive in natural language, or a text prompt t, we iteratively minimize the sum of three losses by changing the latent code w:
a) Distance between generated by StyleGAN image and the text query;
...
3. Now, given a source latent code w_s∈ W+, and a directive in natural language, or a text prompt t, we iteratively minimize the sum of three losses by changing the latent code w:
a) Distance between generated by StyleGAN image and the text query;
...

3/
b) Regularization loss penalizing large deviation of the source vector w_s
c) Identity loss which makes sure that the identity of the generated face is the same as the original one. This is done by minimizing the distance between images in the ArcFace model embedding space
b) Regularization loss penalizing large deviation of the source vector w_s
c) Identity loss which makes sure that the identity of the generated face is the same as the original one. This is done by minimizing the distance between images in the ArcFace model embedding space

4/
Such an image editing process requires iterative optimization of the latent code w (usually 200-300 iterations) for several minutes. To make it faster authors propose a feed-forward method, where instead of optimization, another neural network predicts the residuals ...
Such an image editing process requires iterative optimization of the latent code w (usually 200-300 iterations) for several minutes. To make it faster authors propose a feed-forward method, where instead of optimization, another neural network predicts the residuals ...
5/
... which are added to the latent code w to produce the desired image alterations.
☑️The overall idea of the paper is not super novel and has been around for some time already (e.g., twitt below)
... which are added to the latent code w to produce the desired image alterations.
☑️The overall idea of the paper is not super novel and has been around for some time already (e.g., twitt below)
https://twitter.com/metasemantic/status/1368713208429764616
6/ But this is the first formal paper on such an image editing approach using CLIP and StyleGAN.
Other related papers, recently discussed by me:
Other related papers, recently discussed by me:
https://twitter.com/artsiom_s/status/1374248622183829504?s=20
https://twitter.com/artsiom_s/status/1372766693341065222?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh