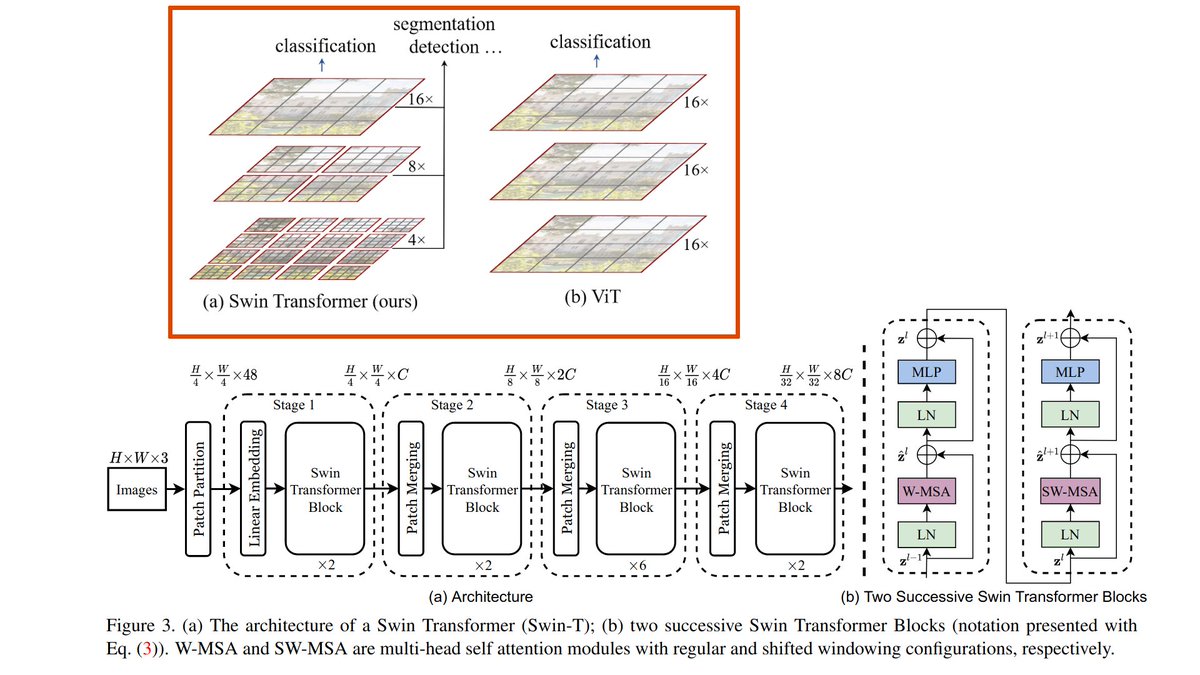
Self-supervised Learning for Medical images
Due to fixed imaging procedures, medical images like X-ray or CT scans are usually well aligned.
This gives an opportunity to utilize such an alignment to automatically mine similar pairs of images for training
arxiv.org/abs/2102.10680
Due to fixed imaging procedures, medical images like X-ray or CT scans are usually well aligned.
This gives an opportunity to utilize such an alignment to automatically mine similar pairs of images for training
arxiv.org/abs/2102.10680

1/
The basic idea is to fix K random locations in the unlabeled medical images (K locations are the same for every image) and crop image patches across different images (which correspond to scans of different patients).
...
The basic idea is to fix K random locations in the unlabeled medical images (K locations are the same for every image) and crop image patches across different images (which correspond to scans of different patients).
...
2/
Now we create a surrogate classification task by assigning a unique pseudo-label to every location 1...K.
Authors combine the surrogate classification task with image restoration using a denoising autoencoder: they randomly perturb the cropped patches (color jittering, ...
Now we create a surrogate classification task by assigning a unique pseudo-label to every location 1...K.
Authors combine the surrogate classification task with image restoration using a denoising autoencoder: they randomly perturb the cropped patches (color jittering, ...
3/
... random noise, random cut-outs) and train a decoder to restore the original view.
However, sometimes the alignment between medical images is not perfect by default and images may depict different body parts.
To make sure that the images which we use to crop patches ...
... random noise, random cut-outs) and train a decoder to restore the original view.
However, sometimes the alignment between medical images is not perfect by default and images may depict different body parts.
To make sure that the images which we use to crop patches ...
4/
... are aligned, we train an autoencoder on full images (before cropping) and select only similar images by comparing the distances between them in the learned autoencoder latent space.
Authors show that their method is significantly better than ...
... are aligned, we train an autoencoder on full images (before cropping) and select only similar images by comparing the distances between them in the learned autoencoder latent space.
Authors show that their method is significantly better than ...
5/
... other self-supervised learning approaches on medical data and can even be combined with existing self-supervised methods like RotNet (predicting random rotations of the image).
... other self-supervised learning approaches on medical data and can even be combined with existing self-supervised methods like RotNet (predicting random rotations of the image).
6/
But unfortunately, the comparison is rather limited, and they didn't compare to Jigsaw Puzzle, SwaV, or recent contrastive self-supervised methods like MoCO, BYOL, and SimCLR.
🛠️Code& Models github.com/fhaghighi/Tran…
But unfortunately, the comparison is rather limited, and they didn't compare to Jigsaw Puzzle, SwaV, or recent contrastive self-supervised methods like MoCO, BYOL, and SimCLR.
🛠️Code& Models github.com/fhaghighi/Tran…

👉 Join my Telegram channel for more reviews like this
t.me/gradientdude
t.me/gradientdude
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh