Sharing ideas on how to disseminate your research.
"I am THRILLED to share that our paper is accepted to ..."
Congrats! So what's next? No one is going to browse through the list of thousands of accepted papers. Ain't nobody got time for that.
Check out 🧵below for examples.
"I am THRILLED to share that our paper is accepted to ..."
Congrats! So what's next? No one is going to browse through the list of thousands of accepted papers. Ain't nobody got time for that.
Check out 🧵below for examples.
*Website*
Use memorable domain names for your project website so that people can easily find/share the link. No university account? That's okay. Register a new name for GitHub pages.
Examples:
• oops.cs.columbia.edu
• crowdsampling.io
• robust-cvd.github.io
Use memorable domain names for your project website so that people can easily find/share the link. No university account? That's okay. Register a new name for GitHub pages.
Examples:
• oops.cs.columbia.edu
• crowdsampling.io
• robust-cvd.github.io
*Acronym*
Make it easy for people to remember and refer to your work. As David Patterson said, the vowel is important.
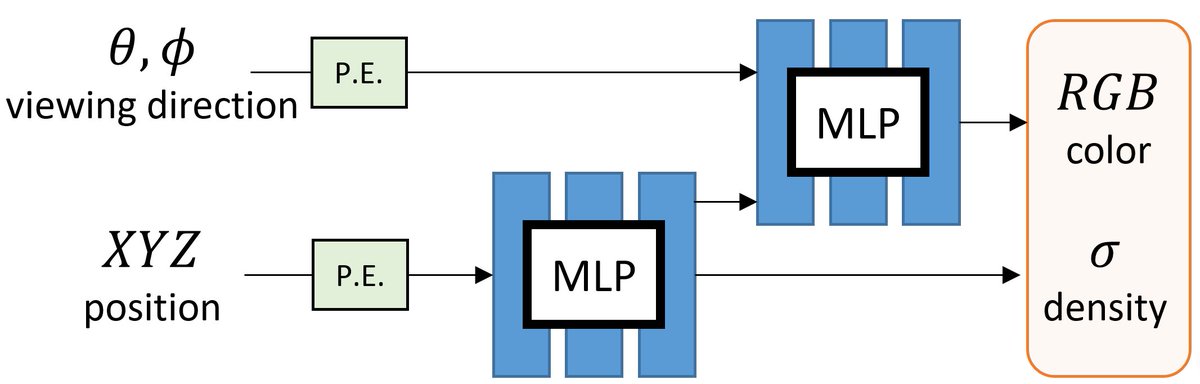
For example, NeRF sounds waaaaaay cooler than NRF..
Make it easy for people to remember and refer to your work. As David Patterson said, the vowel is important.
For example, NeRF sounds waaaaaay cooler than NRF..
*Result video*
Make a simple video showing the killer results from your work! Based on my back-of-the-envelope calculation, I would have to present this ECCV paper in the zoom poster session for 18 years straight to reach the same level of visibility.
Make a simple video showing the killer results from your work! Based on my back-of-the-envelope calculation, I would have to present this ECCV paper in the zoom poster session for 18 years straight to reach the same level of visibility.
https://twitter.com/jbhuang0604/status/1301899594838704128?s=20
*Paper video*
Having a short video introducing the essence of the paper is arguably THE BEST.
Examples I like
•
(@jon_barron)
• (@AbeDavis)
• (@JPKopf)
Having a short video introducing the essence of the paper is arguably THE BEST.
Examples I like
•
(@jon_barron)
• (@AbeDavis)
• (@JPKopf)
*Downloadable results*
Do not put your result videos on YouTube and then embed them on your website. Make it super easy for people to download (and share) your results. Help people help share your work.
No image/video size limits so share the highest quality possible.
Do not put your result videos on YouTube and then embed them on your website. Make it super easy for people to download (and share) your results. Help people help share your work.
No image/video size limits so share the highest quality possible.
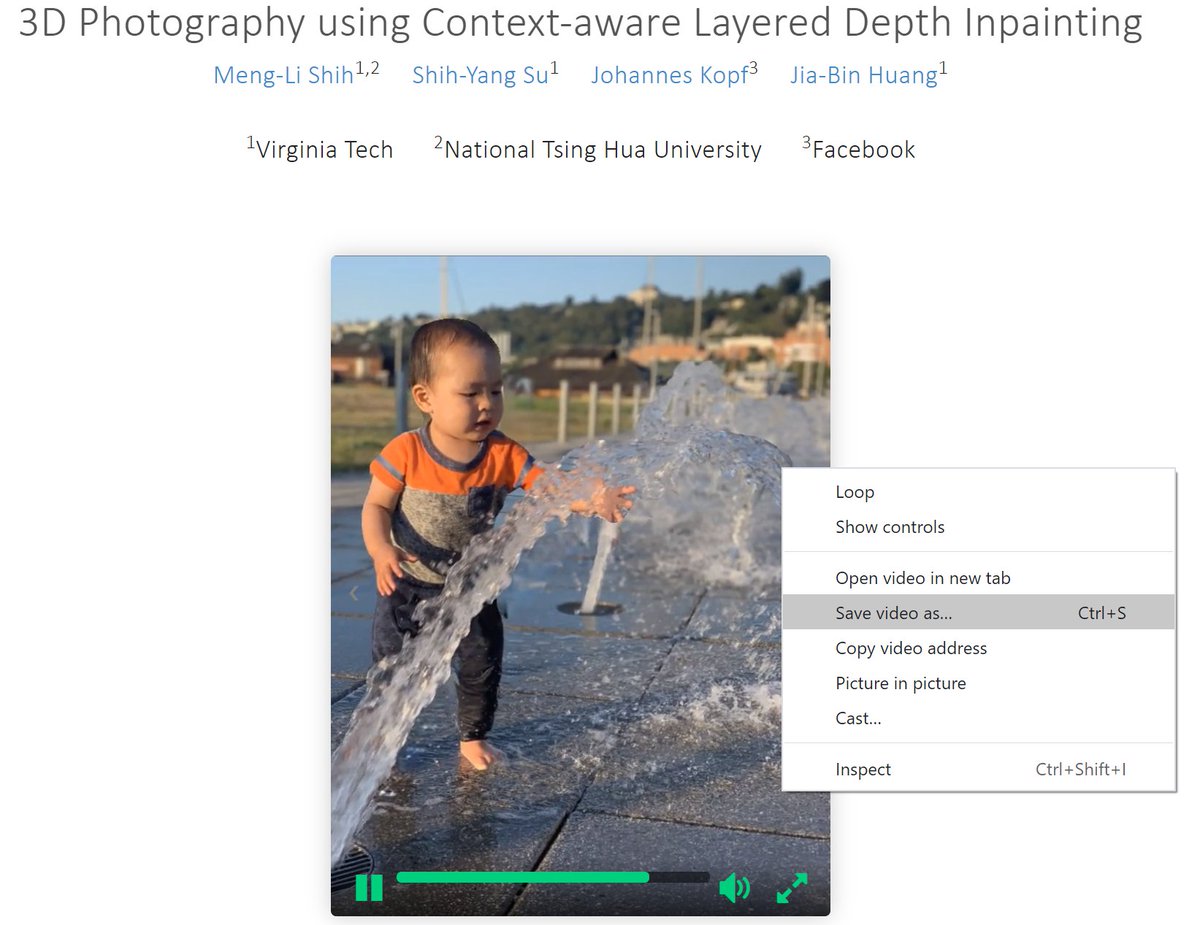

*Additional results*
Very often you need to work hard constructing the baseline results across multiple datasets. Make them available so that people can easily follow up. For example, many citations of this work are not for specific technical contributions.
Very often you need to work hard constructing the baseline results across multiple datasets. Make them available so that people can easily follow up. For example, many citations of this work are not for specific technical contributions.

*Supplementary website*
Organize all the results across multiple datasets, methods, and ablation on a webpage. This allows EVERYONE (including myself) to interactively explore the results.
Example:
alex04072000.github.io/ObstructionRem…
Organize all the results across multiple datasets, methods, and ablation on a webpage. This allows EVERYONE (including myself) to interactively explore the results.
Example:
alex04072000.github.io/ObstructionRem…

*GitHub*
Don't simply dump unorganized research code to GitHub. Write clear instructions and simplify the steps required to get the code running.
Examples I like:
- github.com/junyanz/pytorc… (@junyanz89)
- github.com/NVlabs/stylega…
Don't simply dump unorganized research code to GitHub. Write clear instructions and simplify the steps required to get the code running.
Examples I like:
- github.com/junyanz/pytorc… (@junyanz89)
- github.com/NVlabs/stylega…
*Colab*
Not everyone has the knowledge/resources to set up the environment required for your code on GitHub. Preparing a colab notebook demo (or other platforms) allows everyone to play around with your method.
Not everyone has the knowledge/resources to set up the environment required for your code on GitHub. Preparing a colab notebook demo (or other platforms) allows everyone to play around with your method.

*arXiv*
Host all your papers on arXiv. It's very frustrating to papers behind the paywall. Posting your paper at a specific time further increases the visibility/readership/impact of your work.
Host all your papers on arXiv. It's very frustrating to papers behind the paywall. Posting your paper at a specific time further increases the visibility/readership/impact of your work.
https://twitter.com/jbhuang0604/status/1337985347733622788?s=20
*Teaser image/video*
On your publication page, show teaser images/videos so that people can quickly browse through all your work. Work hard to optimize the quality of your teaser! Trust me, it's definitely worth your time.
filebox.ece.vt.edu/~jbhuang/#pubs
On your publication page, show teaser images/videos so that people can quickly browse through all your work. Work hard to optimize the quality of your teaser! Trust me, it's definitely worth your time.
filebox.ece.vt.edu/~jbhuang/#pubs
*Engagement*
When sharing on social media or other sites (e.g., Twitter, YouTube, HackerNews, Reddit...), engage with people who comment on your work even tho sometimes you may encounter comments with bad intentions. Over time, they will be your best allies.
When sharing on social media or other sites (e.g., Twitter, YouTube, HackerNews, Reddit...), engage with people who comment on your work even tho sometimes you may encounter comments with bad intentions. Over time, they will be your best allies.
* Hyperlinks*
Make sure every page has hyperlinks to every other pages. For examples, add links to authors’ pages, related projects, GitHub/Colab, datasets, YouTube videos additional results. Make it easy to navigate the contents via multiple paths.
Make sure every page has hyperlinks to every other pages. For examples, add links to authors’ pages, related projects, GitHub/Colab, datasets, YouTube videos additional results. Make it easy to navigate the contents via multiple paths.
*BibTeX*
Everyone knows that bibtex from google scholar is erroneous. Do your readers a favor and help people cite your paper correctly.
Everyone knows that bibtex from google scholar is erroneous. Do your readers a favor and help people cite your paper correctly.

*Paper title*
A title should capture what is SPECIAL about the paper. Check out the talk by Jitendra Malik about the paper title.
BTW, the entire workshop is awesome. Check them out!
cc.gatech.edu/~parikh/citize…
A title should capture what is SPECIAL about the paper. Check out the talk by Jitendra Malik about the paper title.
BTW, the entire workshop is awesome. Check them out!
cc.gatech.edu/~parikh/citize…
*Music*
Whaaaaat?! How is music related to my research? YES, it helps make your video more engaging and fun to watch. If possible, match the transitions with music beats.
Examples I like:
(@holynski_)
Whaaaaat?! How is music related to my research? YES, it helps make your video more engaging and fun to watch. If possible, match the transitions with music beats.
Examples I like:
(@holynski_)
*Website template*
Don't know how to write HTML responsive web design? A good template is your friend!
Examples I like:
• nerfies.github.io
• richzhang.github.io/colorization/
• alex04072000.github.io/ObstructionRem…
Don't know how to write HTML responsive web design? A good template is your friend!
Examples I like:
• nerfies.github.io
• richzhang.github.io/colorization/
• alex04072000.github.io/ObstructionRem…
*Links to concurrent work*
Provide readers a complete landscape of concurrent work.
"Credits are not like money. Giving credit to others does not diminish the credit you get from your paper." - Simon Peyton Jones
Examples:
• phog.github.io/snerg/
• alexyu.net/plenoctrees/
Provide readers a complete landscape of concurrent work.
"Credits are not like money. Giving credit to others does not diminish the credit you get from your paper." - Simon Peyton Jones
Examples:
• phog.github.io/snerg/
• alexyu.net/plenoctrees/


• • •
Missing some Tweet in this thread? You can try to
force a refresh