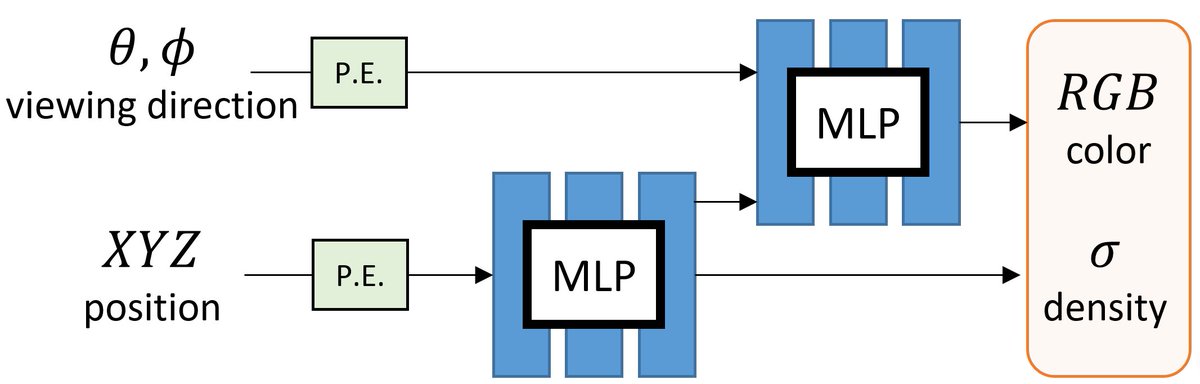
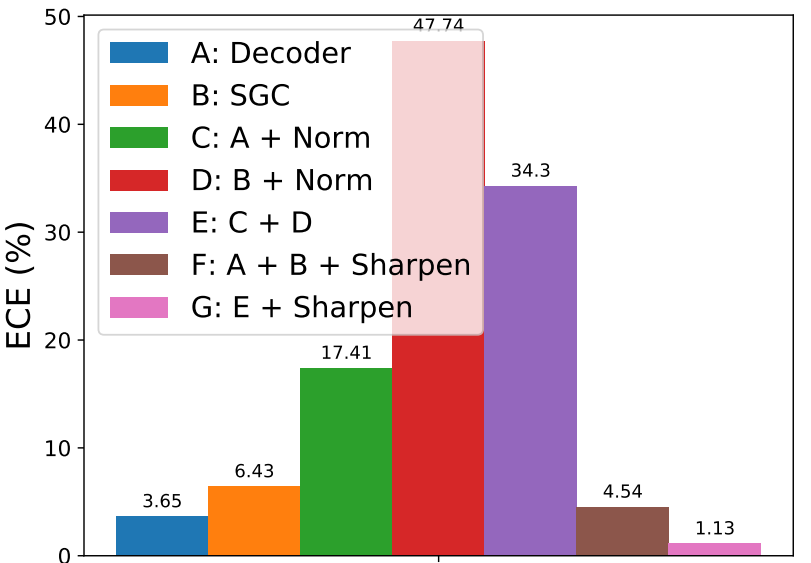
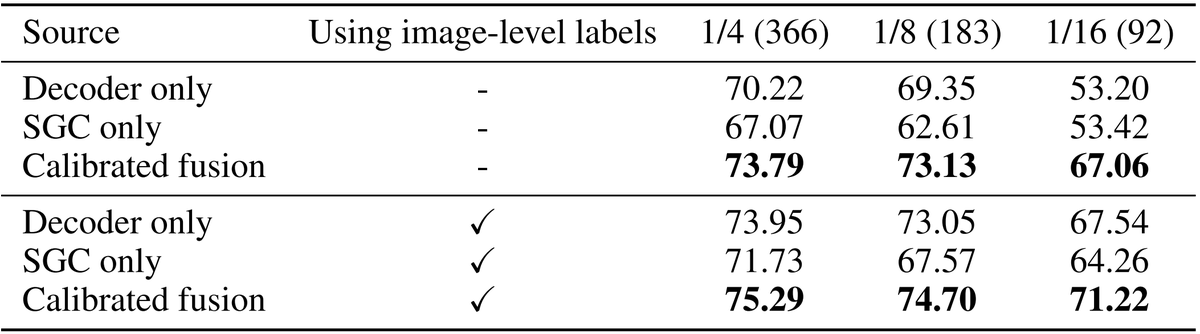
Understanding ML/CV papers 📰
• Ground truth label:
Some guy says so.
• Learning from unlabeled data:
Learning from carefully curated ImageNet and pretend that we don't know the labels.
• Parameter empirically determined:
Tried many paras and this has the best number.
• Ground truth label:
Some guy says so.
• Learning from unlabeled data:
Learning from carefully curated ImageNet and pretend that we don't know the labels.
• Parameter empirically determined:
Tried many paras and this has the best number.
• Interpretable classification:
Showing some cherry-picked blurry heat maps.
• Code and data available upon acceptance:
Accept this paper first, then we will consider releasing them when we finish the follow-up paper.
Showing some cherry-picked blurry heat maps.
• Code and data available upon acceptance:
Accept this paper first, then we will consider releasing them when we finish the follow-up paper.
• User study:
My labmates think our results look better.
• Analysis-by-synthesis:
Tuning the model until it looks good.
• To the best of our knowledge, we are the first...:
Did not see this on Twitter
My labmates think our results look better.
• Analysis-by-synthesis:
Tuning the model until it looks good.
• To the best of our knowledge, we are the first...:
Did not see this on Twitter
• Code will be available at github.com...
Maybe after a couple of years
• Sample visual results
These are the only three images where we can find improvement.
• Classical approaches ...
Papers last year
Maybe after a couple of years
• Sample visual results
These are the only three images where we can find improvement.
• Classical approaches ...
Papers last year
• • •
Missing some Tweet in this thread? You can try to
force a refresh