🤯Tercer y última parte de ERRORES QUE DAN MIEDO en #DataScience 🎃
☠️ERRORES mortales que incluso los expertos cometen⚰️
rosanaferrero.blogspot.com/2016/09/los-7-…
Continúa leyendo, si te atreves...👻
#HorrorStats #HappyHalloween #DataAnalytics #Halloween #FelizLunes #dataviz #RStats #Python #ML
☠️ERRORES mortales que incluso los expertos cometen⚰️
rosanaferrero.blogspot.com/2016/09/los-7-…
Continúa leyendo, si te atreves...👻
#HorrorStats #HappyHalloween #DataAnalytics #Halloween #FelizLunes #dataviz #RStats #Python #ML
🚫No realizar una investigación reproducible💀
“Every analysis you do on a dataset will have to be redone 10-15 times before publication. Plan accordingly” Trevor A.Branch
No crear un informe replicable, reproducible y reutilizable sí que DA MIEDO
#HorrorStats #HappyHalloween
“Every analysis you do on a dataset will have to be redone 10-15 times before publication. Plan accordingly” Trevor A.Branch
No crear un informe replicable, reproducible y reutilizable sí que DA MIEDO
#HorrorStats #HappyHalloween
🚫No seleccionar la prueba de hipótesis o el modelo de regresión correcto para tu objetivo🎃
¿Cuáles son las hipótesis? ¿Cómo son las muestras? ¿Qué tipo de prueba/modelo elegir? ¿Una cola o dos colas? ¿Qué hacer si mis datos no cumplen los supuestos? BOOO!! 👻
#HorrorStats #ML
¿Cuáles son las hipótesis? ¿Cómo son las muestras? ¿Qué tipo de prueba/modelo elegir? ¿Una cola o dos colas? ¿Qué hacer si mis datos no cumplen los supuestos? BOOO!! 👻
#HorrorStats #ML
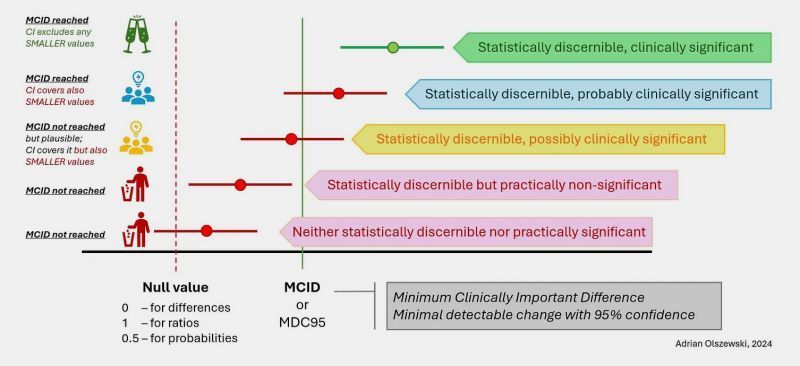
🚫No distinguir la significación estadística de la significación práctica🤦🏻♀️p-valor nos dice la dirección y tamaño del efecto la magnitud
Que exista una diferencia no significa que sea grande
Muestras muy grandes detectan diferencias muy pequeñas. Big Data da MIEDO!
#HorrorStats
Que exista una diferencia no significa que sea grande
Muestras muy grandes detectan diferencias muy pequeñas. Big Data da MIEDO!
#HorrorStats
🚫Decir "se comprueba la hipótesis nula H0" o "H0 es cierta"
👉Así como la falta de evidencia no demuestra que el acusado es inocente, un resultado no estadísticamente significativo (e.g. p>.05) no demuestra que H0 sea verdadera. Solo “no hay suficiente evidencia"💀
#HorrorStats
👉Así como la falta de evidencia no demuestra que el acusado es inocente, un resultado no estadísticamente significativo (e.g. p>.05) no demuestra que H0 sea verdadera. Solo “no hay suficiente evidencia"💀
#HorrorStats

🚫Decir "el p-valor es la probabilidad de que H0 sea cierta"
😱Las hipótesis son o no son. p-valor mide la fuerza de la evidencia contra H0. A menor p-valor, mayor evidencia contra H0 a largo plazo🧙
Sientes ESCALOFRÍOS?
#HorrorStats #DataScience #Halloween2022 #RStats #Python
😱Las hipótesis son o no son. p-valor mide la fuerza de la evidencia contra H0. A menor p-valor, mayor evidencia contra H0 a largo plazo🧙
Sientes ESCALOFRÍOS?
#HorrorStats #DataScience #Halloween2022 #RStats #Python

🚫Considerar que el nivel de significación alfa=5% es un mandamiento⛪️
😉El valor 5% es simplemente una convención conveniente, podría ser el 10% o el 1%, no existe un umbral real.
🎃#HorrorStats #DataScience #RStats #Python #Analytics #dataviz #analisisdedatos 👻
Lee más👇
😉El valor 5% es simplemente una convención conveniente, podría ser el 10% o el 1%, no existe un umbral real.
🎃#HorrorStats #DataScience #RStats #Python #Analytics #dataviz #analisisdedatos 👻
Lee más👇

🚫No informar el p-valor exacto ni los resultados completos de la prueba de hipótesis.
😱p-valor depende de:
📌tamaño de efecto (ES), ES grandes son más fáciles de detectar.
📌tamaño de muestra (N). muestras grandes dan pruebas más sensibles
📌Diseño de estudio...
#HorrorStats
😱p-valor depende de:
📌tamaño de efecto (ES), ES grandes son más fáciles de detectar.
📌tamaño de muestra (N). muestras grandes dan pruebas más sensibles
📌Diseño de estudio...
#HorrorStats
🚫No considerar el Error tipo III: resolver el problema incorrecto.
☠️¿Las hipótesis son las correctas? ¿Cuán plausible es H0? ¿Cuáles son las consecuencias de rechazar H0? El contexto es crucial
👻#HorrorStats #Halloween #Halloween2022 #DataScience #dataviz #RStats #Python 🎃
☠️¿Las hipótesis son las correctas? ¿Cuán plausible es H0? ¿Cuáles son las consecuencias de rechazar H0? El contexto es crucial
👻#HorrorStats #Halloween #Halloween2022 #DataScience #dataviz #RStats #Python 🎃

🚫Desconocer la potencia estadística
¿Alguna vez te lo has preguntado?
👉¿Puedo confiar en el resultado?
👉¿Cuántas muestras necesito?
Conocer la potencia estadística nos permite ahorrar tiempo y dinero en nuestras investigaciones, ¡¿cómo no te lo contaron antes?!
#HorrorStats
¿Alguna vez te lo has preguntado?
👉¿Puedo confiar en el resultado?
👉¿Cuántas muestras necesito?
Conocer la potencia estadística nos permite ahorrar tiempo y dinero en nuestras investigaciones, ¡¿cómo no te lo contaron antes?!
#HorrorStats
Interpretar correctamente los resultados de un análisis puede ser muy difícil😱
😎Para volverte un PRO en #DataScience no cometas los errores que te he mostrado en este hilo y usa esta guía para planificar y diseñar investigaciones rigurosas👇
#Halloween
maximaformacion.es/recursos/disen…
😎Para volverte un PRO en #DataScience no cometas los errores que te he mostrado en este hilo y usa esta guía para planificar y diseñar investigaciones rigurosas👇
#Halloween
maximaformacion.es/recursos/disen…
Recuerda👇
• • •
Missing some Tweet in this thread? You can try to
force a refresh