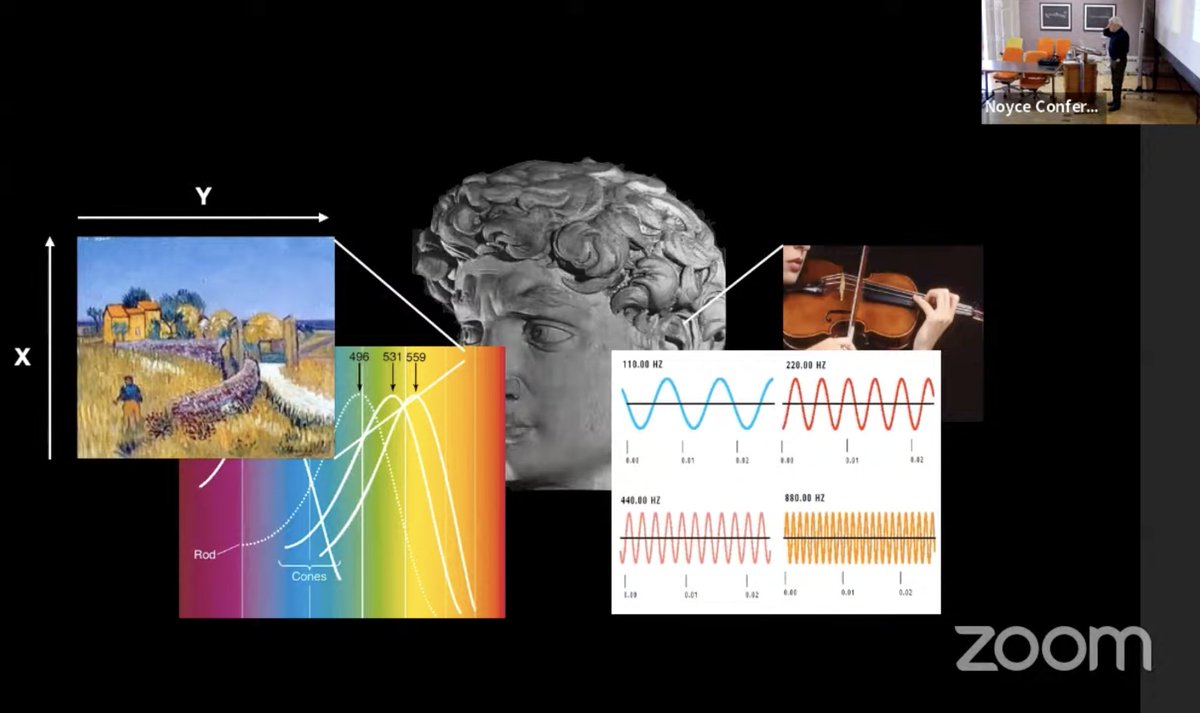
🧵 "#Possibility Architectures: Exploring Human #Communication with Generative #AI"
Today's SFI Seminar with ExFac Simon DeDeo @LaboratoryMinds (@CarnegieMellon), streaming now:

Today's SFI Seminar with ExFac Simon DeDeo @LaboratoryMinds (@CarnegieMellon), streaming now:

"A key feature of this is talk is that we make sense of what each other are saying IN PART by what they say, but ALSO by what we expect of them."

"Language transmits info against a background of expectations – syntactic, semantic, and this larger cultural spectrum. It's not just the choices of make but [how] we set ourselves up to make later choices."
@LaboratoryMinds re: work led by @clairebergey:
@LaboratoryMinds re: work led by @clairebergey:


"If you're talking with somebody who's in a really bad headspace, everything they're saying makes sense [in isolation], but they're [thinking] themselves into corners...can we see the signature of people whose possibility space is [too small or] too large?"

"Given what has come before AND what has come after, what's the #probability of this thing in the middle? It's a bidirectional system."
@LaboratoryMinds on shifting distributions of probability space as explored through interaction with #GPT:
#LLMs #ChatGPT #DigitalHumanities
@LaboratoryMinds on shifting distributions of probability space as explored through interaction with #GPT:
#LLMs #ChatGPT #DigitalHumanities



"The higher you go up, the more surprising—the more unlikely—that word is, given the context. Up here [at the top], this is where the #information is being carried."
"The architecture of the sentence tells me when I can tune out..."
@LaboratoryMinds on #ChatGPT and the @nytimes
"The architecture of the sentence tells me when I can tune out..."
@LaboratoryMinds on #ChatGPT and the @nytimes


"Where we get to 'regarded,' it's a really unusual word choice. It's one of these strange cases, [an] unknown unknown. But at the same time, we have all this junk that's really predictable. [Cormac McCarthy] is capturing this really strange voice AND really stereotyped [speech]."

"I can now tell you why it's so irritating to listen to somebody else's #dreams. Essentially what is happening is that...you get these weird moments where we're not expecting to be surprised and you get something REALLY surprising. ... You don't quite know when to tune out."

Examining information flow in works by Phil Dick, Cormac McCarthy, Lewis Carroll, and Robert Service with #ChatGPT as a #DigitalHumanities instrument:
"In Cormac, at some places in the text it's nine bits per word. In other places, it's six. There's quite a bit of variation."
"In Cormac, at some places in the text it's nine bits per word. In other places, it's six. There's quite a bit of variation."


"There's no cross-validation, [no] beginner's mind with #ChatGPT. It's seen everything before. As a literary critic, you want to examine texts in context...that, you can't do."
Pictured:
"If you have a big surprise at one point, the NEXT word tends to be a much lower surprise."
Pictured:
"If you have a big surprise at one point, the NEXT word tends to be a much lower surprise."

1 - "#ChatGPT really likes filler words."
2 - "Let's follow the surprise curve. Sitting [to the left], you get clichés. Then you get this very long tail of surprise events [to the right]."
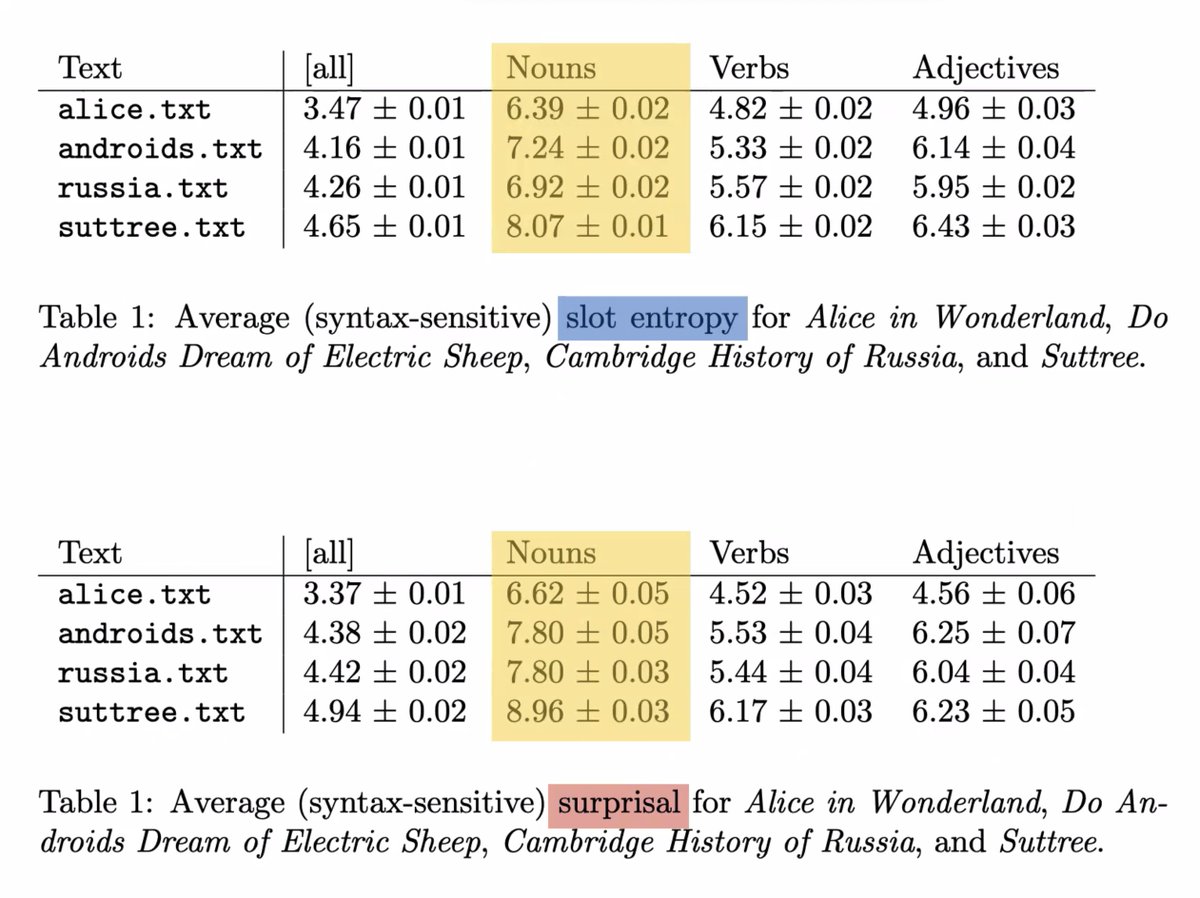
3, 4 - The expected vs. the actual. Slot #entropy and #surprise in textual analysis.
2 - "Let's follow the surprise curve. Sitting [to the left], you get clichés. Then you get this very long tail of surprise events [to the right]."
3, 4 - The expected vs. the actual. Slot #entropy and #surprise in textual analysis.




"#Nouns are doing most of the work. Nouns are carrying most of the information in ALL of these texts."
"We're always more surprised by what happens in these books than #GPT is."
"One of the gaps between slot #entropy and surprisal is in adjectives..."
"We're always more surprised by what happens in these books than #GPT is."
"One of the gaps between slot #entropy and surprisal is in adjectives..."
"Just off the top of my head, [#ChatGPT essay output] looks okay. That's why my colleagues in the humanities are terrified. But the fiction is TERRIBLE. Fake Cormac is what a St John's student would write if they were to parody themselves."



On (NOT) faking classic fiction w/ GPT:
"The system is driven WELL below the regular distribution you've given by the texts. These [#LLMs] are free energy minimizers. #ChatGPT is UNABLE to create those slots where surprise can happen."
@LaboratoryMinds:
"The system is driven WELL below the regular distribution you've given by the texts. These [#LLMs] are free energy minimizers. #ChatGPT is UNABLE to create those slots where surprise can happen."
@LaboratoryMinds:




(Editorial Correction: All of the probability and entropy values measured in this research were from #GPT2. Essays later in the talk were generated with #ChatGPT, but then @clairebergey and @LaboratoryMinds went back and looked at probabilities again using GPT2.)
• • •
Missing some Tweet in this thread? You can try to
force a refresh