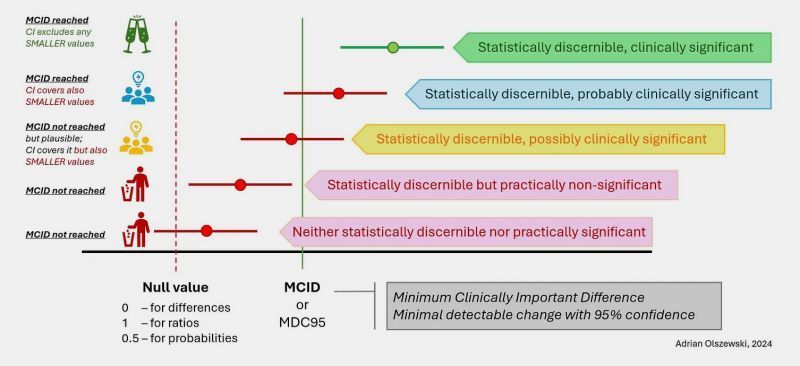
🤖📚 Descubre las mejores herramientas impulsadas por #AI para la investigación académica y ahorra tiempo para hacer lo que más te gusta
📚 Accede a más información en menos tiempo!
🚀 Dale un impulso a tu investigación académica!
#GPT #DataScience #science #chatGPT #research #ML
📚 Accede a más información en menos tiempo!
🚀 Dale un impulso a tu investigación académica!
#GPT #DataScience #science #chatGPT #research #ML

✅Scispace
Espacio de trabajo para automatizar tareas
Obtén una explicación simple de texto, matemáticas y tablas confusas
Haz preguntas de seguimiento y obtén respuestas instantáneas
Busca papers relevantes
Mejora la colaboración
buff.ly/3gz7LhQ
#Researchtools #science
Espacio de trabajo para automatizar tareas
Obtén una explicación simple de texto, matemáticas y tablas confusas
Haz preguntas de seguimiento y obtén respuestas instantáneas
Busca papers relevantes
Mejora la colaboración
buff.ly/3gz7LhQ
#Researchtools #science

✅Elicit
Automatiza flujos de trabajo
Encuentra papers relevantes sin palabras clave exactas
Resume conclusiones del documento específicas para tu pregunta
Extrae información clave de los documentos
Lluvia de ideas, resumen y clasificación de textos
buff.ly/30DwBok
#GPT4
Automatiza flujos de trabajo
Encuentra papers relevantes sin palabras clave exactas
Resume conclusiones del documento específicas para tu pregunta
Extrae información clave de los documentos
Lluvia de ideas, resumen y clasificación de textos
buff.ly/30DwBok
#GPT4
✅ Consensus
Motor de búsqueda que utiliza IA para extraer y resumir hallazgos directamente de trabajos de investigación científica
Incluye una lista con links a los papers revisados por pares
buff.ly/3Mpyglr
#ArtificialIntelligence #sciencetwitter #ScienceEditorial
Motor de búsqueda que utiliza IA para extraer y resumir hallazgos directamente de trabajos de investigación científica
Incluye una lista con links a los papers revisados por pares
buff.ly/3Mpyglr
#ArtificialIntelligence #sciencetwitter #ScienceEditorial
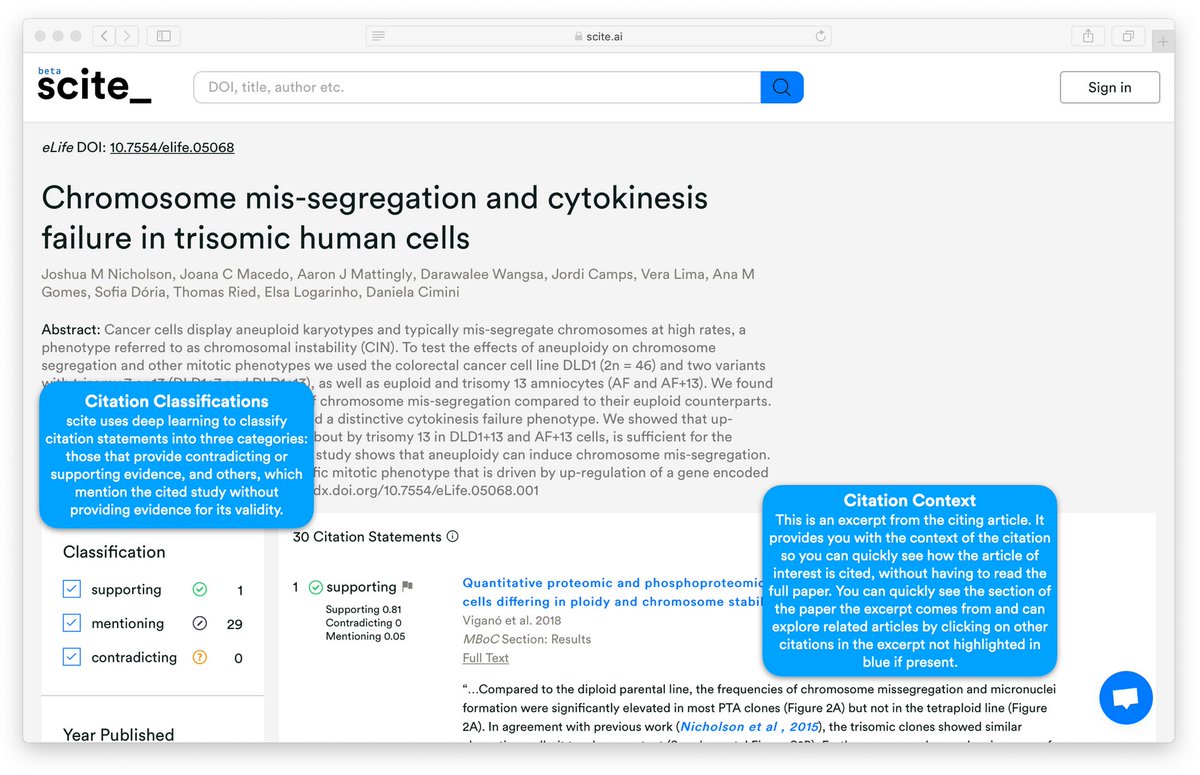
✅Scite
Analiza artículos científicos y extrae info relevante
Identifica los papers +relevantes en tu dominio
Conoce los últimos desarrollos y tendencias
Accede a "citas inteligentes" para explorar el contexto en el que se cita un artículo.
De pago
buff.ly/2IUks4a
#AI
Analiza artículos científicos y extrae info relevante
Identifica los papers +relevantes en tu dominio
Conoce los últimos desarrollos y tendencias
Accede a "citas inteligentes" para explorar el contexto en el que se cita un artículo.
De pago
buff.ly/2IUks4a
#AI
✅ResearchRabbit
Busca papers, crea alertas
Mantente actualizado, visualiza papers, descubre redes de artículos y autores, accede a recomendaciones según tus gustos, resúmenes personalizados, crea y comparte tus colecciones
El Spotify de la investigación!
buff.ly/3KjWL1d
Busca papers, crea alertas
Mantente actualizado, visualiza papers, descubre redes de artículos y autores, accede a recomendaciones según tus gustos, resúmenes personalizados, crea y comparte tus colecciones
El Spotify de la investigación!
buff.ly/3KjWL1d
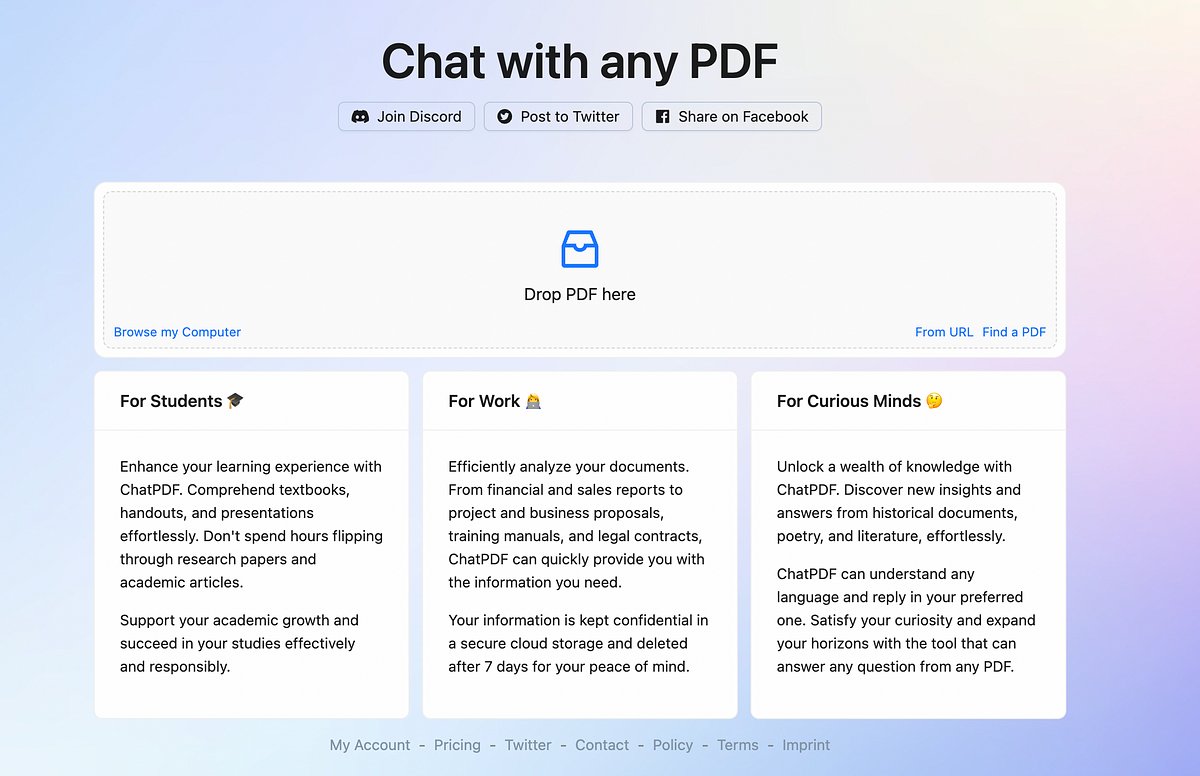
✅ChatPDF
Sube el PDF del paper y comienza a hacerle preguntas
Resume el documento y da ejemplos de preguntas que podría responder basándose en el artículo completo
Facilita la lectura y el análisis de artículos de revistas científica
buff.ly/3zvriFJ
#GPT4 #Researchtools
Sube el PDF del paper y comienza a hacerle preguntas
Resume el documento y da ejemplos de preguntas que podría responder basándose en el artículo completo
Facilita la lectura y el análisis de artículos de revistas científica
buff.ly/3zvriFJ
#GPT4 #Researchtools
• • •
Missing some Tweet in this thread? You can try to
force a refresh