Recent well liked threads

Anti-white mainstream media.
🧵
🧵




Before anyone counters that the following is "just some articles" or "out of context" - remember that Jack Straw tabled a motion which can be found in Hansard, that would affirm that there is no such thing as an indigenous population in Britain.
It was signed by 122 members.
This was in order that indigenous people in Britain wouldn't be subject to Convention 169 on Tribal and Indigenous Peoples, which recognises and respects the land rights of indigenous people.
edm.parliament.uk/early-day-moti…
This is nakedly genocidal.
It was signed by 122 members.
This was in order that indigenous people in Britain wouldn't be subject to Convention 169 on Tribal and Indigenous Peoples, which recognises and respects the land rights of indigenous people.
edm.parliament.uk/early-day-moti…
This is nakedly genocidal.


There are thousands of openly, unashamedly anti-white mainstream media articles.
Thousands.
They hate you because of your race.
Your ethnicity is, to them, something which should be eradicated.
Thousands.
They hate you because of your race.
Your ethnicity is, to them, something which should be eradicated.


MODHATI ANUBHAVAM part - 1
First time is very special for Everyone
Adi btech final year time naku Chala free time undedi subjects aypoyi project aypoyi emcheyalo telika laptop ekuva use chesanu ala porn chustu chustu gay, shemale type of things chusanu Chala excited ayanu nenu😩
First time is very special for Everyone
Adi btech final year time naku Chala free time undedi subjects aypoyi project aypoyi emcheyalo telika laptop ekuva use chesanu ala porn chustu chustu gay, shemale type of things chusanu Chala excited ayanu nenu😩

Alaala chustu one day add vachindi sites lo open cheste it's a app Miku telse untundi le.
Grindr Ani install chesi chusa naku entaduram lo entamandi unaro chusi shock Aya inthamandi karuvulo unara ani.
Ah profile names chudali okaokati diamond asala. Apudey ok msg vachindi hi ani
Grindr Ani install chesi chusa naku entaduram lo entamandi unaro chusi shock Aya inthamandi karuvulo unara ani.
Ah profile names chudali okaokati diamond asala. Apudey ok msg vachindi hi ani

Naku ventane em reply ivalo ardamkala. Nenu same hi ananu
Tanu ASL anadu ante age sex location Ani. Chepanu tana age 26 anadu nakana 8 years pedda ananu
👦🏽: Iyte Enti age lo emundi Niku emkavalo adi nadegara undiga inkem undali
Me: blank kasepu videnti intha direct ga anadu ani👀
Tanu ASL anadu ante age sex location Ani. Chepanu tana age 26 anadu nakana 8 years pedda ananu
👦🏽: Iyte Enti age lo emundi Niku emkavalo adi nadegara undiga inkem undali
Me: blank kasepu videnti intha direct ga anadu ani👀


Liberals Are the Most Dangerous and Inherently Evil Threat to America (THREAD🧵)
The liberal is not merely mistaken, misguided, or simply wrong; they are soulless creatures lacking any moral compass or human empathy, a fact proven by their cold indifference to the millions of lives destroyed by their policies. They are predatory hunters, stalking the vulnerable not to help them, but to secure their votes and feed their insatiable hunger for power, treating the poor as pawns in a game of political chess while they themselves live in gated communities. This is a depraved ideology, morally corrupt beyond redemption, that has normalized the murder of the unborn and the mutilation of children, celebrating these atrocities as progress while claiming the high ground of compassion.
They are treacherous by nature, betraying their country and their neighbors at every turn, from selling our secrets to foreign adversaries to opening our borders to invaders who threaten the very fabric of our society. They are parasitic entities, feeding on the success and labor of hardworking Americans, draining the wealth of the productive to fund their corrupt machine and enrich their donor class. Their actions are malicious, acting with intentional harm and ill will against the very people they claim to serve, as seen in their deliberate destruction of our energy independence which drives up costs for the working class....
The liberal is not merely mistaken, misguided, or simply wrong; they are soulless creatures lacking any moral compass or human empathy, a fact proven by their cold indifference to the millions of lives destroyed by their policies. They are predatory hunters, stalking the vulnerable not to help them, but to secure their votes and feed their insatiable hunger for power, treating the poor as pawns in a game of political chess while they themselves live in gated communities. This is a depraved ideology, morally corrupt beyond redemption, that has normalized the murder of the unborn and the mutilation of children, celebrating these atrocities as progress while claiming the high ground of compassion.
They are treacherous by nature, betraying their country and their neighbors at every turn, from selling our secrets to foreign adversaries to opening our borders to invaders who threaten the very fabric of our society. They are parasitic entities, feeding on the success and labor of hardworking Americans, draining the wealth of the productive to fund their corrupt machine and enrich their donor class. Their actions are malicious, acting with intentional harm and ill will against the very people they claim to serve, as seen in their deliberate destruction of our energy independence which drives up costs for the working class....

The agenda they push is vile, disgustingly immoral and wicked, promoting a culture of decay where anything goes except truth, tradition, and decency. They are corrupt to the core, rotting the foundations of society from within by infiltrating our schools, our courts, and our government agencies with their radical ideology. There is something almost demonic about their fervor, as if possessed by an evil that seeks destruction for its own sake, tearing down statues, burning cities, and defiling sacred institutions with a gleeful hatred.
They are saboteurs, actively working to destroy the nation from within, weakening our military, crippling our economy, and eroding our borders with a precision that suggests a coordinated attack rather than mere incompetence. Their behavior is pathological, a mental disease characterized by a hatred for goodness, order, and success, leading them to punish achievement and reward failure in a twisted attempt to level everyone down to their own mediocrity. They are fraudulent, living a lie to deceive the public, preaching about climate change while flying private jets to global summits, and talking about equality while sending their own children to elite private schools...
They are saboteurs, actively working to destroy the nation from within, weakening our military, crippling our economy, and eroding our borders with a precision that suggests a coordinated attack rather than mere incompetence. Their behavior is pathological, a mental disease characterized by a hatred for goodness, order, and success, leading them to punish achievement and reward failure in a twisted attempt to level everyone down to their own mediocrity. They are fraudulent, living a lie to deceive the public, preaching about climate change while flying private jets to global summits, and talking about equality while sending their own children to elite private schools...

They are ruthless, showing no mercy to the innocent, whether it is the small business owner they shut down during the pandemic or the child they deny medical care to by restricting parental rights. They are calculating, coldly planning the downfall of civilization by systematically dismantling the family unit, the church, and the nation state, replacing them with a soulless bureaucratic nightmare.
Their words are poisonous, spinning toxicity that kills communities, turning neighbors against each other with lies about racism and privilege that have no basis in reality. They are despicable, worthy of only contempt and disgust, for they have abandoned every principle of honor and integrity to maintain their grip on power. They are hypocritical, preaching virtue while practicing evil, claiming to care about women while supporting late-term abortion and claiming to care about minorities while keeping them in generational poverty through failed policies. They are cruel, delighting in the suffering of others, mocking the religious, ridiculing the patriotic, and laughing at the struggles of those who do not share their worldview...
Their words are poisonous, spinning toxicity that kills communities, turning neighbors against each other with lies about racism and privilege that have no basis in reality. They are despicable, worthy of only contempt and disgust, for they have abandoned every principle of honor and integrity to maintain their grip on power. They are hypocritical, preaching virtue while practicing evil, claiming to care about women while supporting late-term abortion and claiming to care about minorities while keeping them in generational poverty through failed policies. They are cruel, delighting in the suffering of others, mocking the religious, ridiculing the patriotic, and laughing at the struggles of those who do not share their worldview...


A REQUEST FOR KNOWLEDGE part 1/3
This morning I received a question I like.
“How does a Jivanmukta (liberated soul) like you view this life? Through what lens do you experience the world, people, and situations? How does your pure mind help you navigate daily life situations and decisions so effortlessly and remain balanced in them?”
“Ordinary people like us often get entangled at the level of mind and intellect, trapped in dualities, and struggle to make decisions. In such a scenario, how does a Jivanmukta live through these paradoxes, dualities, and complex situations of life? What is it in their inner state and vision that keeps them effortless, balanced, and free in every situation?”
Let's understand some basics first. Bhulok भूलोक or this earth is not an isolated world. It is inextricably linked to the whole brahmand or cosmos. The brahmand consists of 14 loks or worlds.
The worlds above and below bhulok are subtle and many of them can't be sensed with our ordinary sensory capacity. Yet many people shift their energy unknowingly and do arrive at sensing them.
Simply put, self obsession and selfishness open your senses and consciousness to the lower worlds creating storms of discontent and dejection in your mind. While, caring about others and the world, an opening of the heart towards other beings and a determination to benefit more beings opens the doors to higher worlds, leading to stability of mind and kindness of heart.
What are these lower worlds and how do we invite our consciousness to descend into a chaotic, unregulated mess?
1. Atal अतल - Just below the earth plane and quite easy to reach even with a little self-centredness is the world of Atal, when your consciousness descends here you are overcome by lust. For men it is marked by dehumanising women and seeing them as sex objects, for women it is marked by measuring their self worth by their sexual power over men. In this state of mind, emotional connection is not possible between partners, cheating and multiple partners start to make sense. Pleasures of the flesh seem to be the only truth.
2. Vital वितल - when you spiral lower into self seeking your consciousness descends into greed for luxury and wealth, you start to measure yourself by how much material wealth you have, you can get addicted to making money, taking big risks, gambling and the pleasure of gaining wealth, gold, gems, luxury and status. Wealth becomes power and the only truth. Relationships depend on profits and people can be replaced when not performing to produce wealth. The urge to profit from everything makes you dehumanise everyone else and most certainly your life ends in disease and death that you can't buy your way out of, due to the curses of others.
3. Sutal सुतल - when your consciousness descends to this world you are overcome with urges of owning land, you objectify the earth, cut forests, deplete eco-systems, affect climate, your truth becomes that the earth is to exploit and is a non-conscious resource. At high skill levels of greed you think of population control and genocide and think nothing of killing people, waging wars, grabbing land, enslaving people with debt and threat. Other humans seem to be either leverage or resources only. You gain pleasure in profits and strive to control narratives to control populations. Ultimately, descending to this world and all the worlds above lead to a noisy and uncontrollable mind and a heavy conscience that becomes dependent on drugs to feel better. The drug ages you, depletes your life force and kills you. And in addition you accumulate curses from people, other beings and even from the planet and suffer very hard even in the afterlife until you start to care about others and the environment.
Continued in part 2
This morning I received a question I like.
“How does a Jivanmukta (liberated soul) like you view this life? Through what lens do you experience the world, people, and situations? How does your pure mind help you navigate daily life situations and decisions so effortlessly and remain balanced in them?”
“Ordinary people like us often get entangled at the level of mind and intellect, trapped in dualities, and struggle to make decisions. In such a scenario, how does a Jivanmukta live through these paradoxes, dualities, and complex situations of life? What is it in their inner state and vision that keeps them effortless, balanced, and free in every situation?”
Let's understand some basics first. Bhulok भूलोक or this earth is not an isolated world. It is inextricably linked to the whole brahmand or cosmos. The brahmand consists of 14 loks or worlds.
The worlds above and below bhulok are subtle and many of them can't be sensed with our ordinary sensory capacity. Yet many people shift their energy unknowingly and do arrive at sensing them.
Simply put, self obsession and selfishness open your senses and consciousness to the lower worlds creating storms of discontent and dejection in your mind. While, caring about others and the world, an opening of the heart towards other beings and a determination to benefit more beings opens the doors to higher worlds, leading to stability of mind and kindness of heart.
What are these lower worlds and how do we invite our consciousness to descend into a chaotic, unregulated mess?
1. Atal अतल - Just below the earth plane and quite easy to reach even with a little self-centredness is the world of Atal, when your consciousness descends here you are overcome by lust. For men it is marked by dehumanising women and seeing them as sex objects, for women it is marked by measuring their self worth by their sexual power over men. In this state of mind, emotional connection is not possible between partners, cheating and multiple partners start to make sense. Pleasures of the flesh seem to be the only truth.
2. Vital वितल - when you spiral lower into self seeking your consciousness descends into greed for luxury and wealth, you start to measure yourself by how much material wealth you have, you can get addicted to making money, taking big risks, gambling and the pleasure of gaining wealth, gold, gems, luxury and status. Wealth becomes power and the only truth. Relationships depend on profits and people can be replaced when not performing to produce wealth. The urge to profit from everything makes you dehumanise everyone else and most certainly your life ends in disease and death that you can't buy your way out of, due to the curses of others.
3. Sutal सुतल - when your consciousness descends to this world you are overcome with urges of owning land, you objectify the earth, cut forests, deplete eco-systems, affect climate, your truth becomes that the earth is to exploit and is a non-conscious resource. At high skill levels of greed you think of population control and genocide and think nothing of killing people, waging wars, grabbing land, enslaving people with debt and threat. Other humans seem to be either leverage or resources only. You gain pleasure in profits and strive to control narratives to control populations. Ultimately, descending to this world and all the worlds above lead to a noisy and uncontrollable mind and a heavy conscience that becomes dependent on drugs to feel better. The drug ages you, depletes your life force and kills you. And in addition you accumulate curses from people, other beings and even from the planet and suffer very hard even in the afterlife until you start to care about others and the environment.
Continued in part 2

A REQUEST FOR KNOWLEDGE part 2/3
4. Talatal तलातल - this descent is very deep and surpasses all three of the above. This is a world of illusions, a mayavi lok. Your pleasure and thrill becomes using your intelligence and the greed and intellectual laziness of others to spin a story that charms them, when they willingly sacrifice themselves for you, you derive great pleasure. Novices form cults, but experienced mayavis get their thrills from regime change and revolution. Everyone seems like a pawn in the game of submission to you. Any humans running things honestly at scale hurts you and you enjoy spinning a maya that destroys them. People realise you didn't care only after they die. But they still curse you and you definitely need drugs or alcohol to kill all empathy and suppress the disturbance of your mind.
5. Mahatal महातल - this is a lower world where your consciousness becomes poisonous, it's also called naglok or serpent world. In this world your consciousness gets addicted to the power of killing other humans. You might form a human sacrifice cult, drink the blood of others. You see yourself as an apex predator and rise in society by killing and fear. You think of yourself as above the law. You form an army of killers and rituals and worship around drinking human blood and eating human flesh.
6. Rasatal रसातल - this descent is to the world of Asurs or demons. Here you stop needing drugs, you are convinced that you are a god, you train hard in occult sciences and left hand spirituality and gain powers over spirits, you make them your slaves and get others to give you energy and power by worshipping you. You laugh at people worshipping idols, you want to kill them and break their temples. You want to challenge the gods and goddesses, you use your captured spirits to make people obey and rule over them. You learn how to change bodies by capturing a younger human and shifting your consciousness into him or her. This is the lowest that selfishness and self centeredness can take you. You will live across generations by changing bodies until you get bored of it. Boredom makes you pray to God to come and kill you. And either Mahavishnu or Devi will arrive to kill you and liberate you from your misery of boredom from too much power.
7. Patal - पाताल this world cannot be reached by selfishness. This is where Mahavishnu sleeps on Adisesha for half the year. Other great serpents like vasuki also come from this world. This is a resting place for Mahasiddhas. No evil is allowed, it's a samadhi Kshetra or a place of deep rest. Patanjali Maharshi who wrote the Yogasutra came from here. Many Mahasiddhas live here and operate their bodies on Bhulok from here. Those who live here are equal to Mahavishnu in their power. If your consciousness reaches patal you are liberated from disturbances and duality. You see the whole brahmand as one. From here to Vaikuntha is just a thought away. A human consciousness can touch patal only by bhakti and atmasamarpan, faith and self-offering towards Mahavishnu and Mahalakshmi. Someone whose consciousness touches Patal will appear calm and unaffected by worldly turbulence
So six worlds below Bhulok lead to evil and the seventh leads to non-duality of Good and Evil.
What happens above earth?
When your consciousness ascends due to humility and love there are 6 worlds to ascend to from bhulok
4. Talatal तलातल - this descent is very deep and surpasses all three of the above. This is a world of illusions, a mayavi lok. Your pleasure and thrill becomes using your intelligence and the greed and intellectual laziness of others to spin a story that charms them, when they willingly sacrifice themselves for you, you derive great pleasure. Novices form cults, but experienced mayavis get their thrills from regime change and revolution. Everyone seems like a pawn in the game of submission to you. Any humans running things honestly at scale hurts you and you enjoy spinning a maya that destroys them. People realise you didn't care only after they die. But they still curse you and you definitely need drugs or alcohol to kill all empathy and suppress the disturbance of your mind.
5. Mahatal महातल - this is a lower world where your consciousness becomes poisonous, it's also called naglok or serpent world. In this world your consciousness gets addicted to the power of killing other humans. You might form a human sacrifice cult, drink the blood of others. You see yourself as an apex predator and rise in society by killing and fear. You think of yourself as above the law. You form an army of killers and rituals and worship around drinking human blood and eating human flesh.
6. Rasatal रसातल - this descent is to the world of Asurs or demons. Here you stop needing drugs, you are convinced that you are a god, you train hard in occult sciences and left hand spirituality and gain powers over spirits, you make them your slaves and get others to give you energy and power by worshipping you. You laugh at people worshipping idols, you want to kill them and break their temples. You want to challenge the gods and goddesses, you use your captured spirits to make people obey and rule over them. You learn how to change bodies by capturing a younger human and shifting your consciousness into him or her. This is the lowest that selfishness and self centeredness can take you. You will live across generations by changing bodies until you get bored of it. Boredom makes you pray to God to come and kill you. And either Mahavishnu or Devi will arrive to kill you and liberate you from your misery of boredom from too much power.
7. Patal - पाताल this world cannot be reached by selfishness. This is where Mahavishnu sleeps on Adisesha for half the year. Other great serpents like vasuki also come from this world. This is a resting place for Mahasiddhas. No evil is allowed, it's a samadhi Kshetra or a place of deep rest. Patanjali Maharshi who wrote the Yogasutra came from here. Many Mahasiddhas live here and operate their bodies on Bhulok from here. Those who live here are equal to Mahavishnu in their power. If your consciousness reaches patal you are liberated from disturbances and duality. You see the whole brahmand as one. From here to Vaikuntha is just a thought away. A human consciousness can touch patal only by bhakti and atmasamarpan, faith and self-offering towards Mahavishnu and Mahalakshmi. Someone whose consciousness touches Patal will appear calm and unaffected by worldly turbulence
So six worlds below Bhulok lead to evil and the seventh leads to non-duality of Good and Evil.
What happens above earth?
When your consciousness ascends due to humility and love there are 6 worlds to ascend to from bhulok
A REQUEST FOR KNOWLEDGE part 3/3
1. Bhuvarlok भुवर्लोक - with a little humility and love your consciousness can ascend to bhuvarlok. Here are the devatas of the panchang, and grahas. The gods of panchang are the various gods of tithi, var, nakshatra, yog, karan and the navagrahas. All of these control your fortunes. Ascending here makes you aware of your karma and what will happen and what has happened in the past. You will live a life of alignment and zero anxiety and find a non-selfish, win-win purpose in every problem you encounter no matter how grave. With deeper empathy, humility and love you'll find yourself and everyone you care about winning even in poor astrological conditions. However, life won't be effortless even though it doesn't disturb you.
2. Swarlok स्वर्लोक - when you widen your care your consciousness eventually ascends to a higher perception, every sensory input will bring you heavenly pleasure, this world is occupied by Indra , Kuber, Vayu, Agni, Mitra and all the early Vedic gods and goddesses, it is devlok or a world of gods. It is highly possible to get addicted to sensory pleasure in this state of consciousness, you will be high, in pleasure 24/7, you will develop magical siddhis that challenge natural laws, it will rain when you wish for example, but the moment you stop caring you'll be thrown down into being ordinary again and that crash is quite brutal. That's why I tell my shishyas not to become a citizen of devlok, it's ok to visit sometimes but make sure to leave.
3. Maharlok महर्लोक - when you start to care about wins for the whole world you become a Rishi, maharlok is the hideout of Rishis. From here they can care for humans while not getting involved in worldly bondage. This is the first world of liberation. A person whose consciousness reaches here becomes free of bondage and can live a powerful life. Such a person also becomes immortal, they can also occupy multiple bodies at a single time. It is the favourite place of Maharishis, they live here during Kalyug, coming to Bhulok only when advanced humans need guidance. Gurus often occupy this place with their consciousness. So no worldly turbulence affects them. This is an ascetic world of silence where Rishis live with their Rishipatnis waiting for Kalyug to end and Mahavishnu's final avatar. They come down to bhulok after Mahavishnu takes birth and protect his cause.
4. Janarlok - जनर्लोक you need to really ascend your consciousness in deep love, humility and care to reach Janarlok. Only children of Brahma live here, like Narad and Sanat Kumaras, these are sages and need nothing, they exist to give and give without taking and their power to give is unlimited. They have no desire, humans on Bhulok give them purpose with their problems. They are masters of mantra and music and the Vedas. Brahmarishis who live on earth occupy this world in their consciousness. They too are not affected at all by worldly turbulence.
5. Tapolok तपोलोक - this place is also called Kailash because Shivji, Parvatiji and Ganeshji do tapasya here. When your consciousness ascends into the will to do tapasya to generate punya and var, merits and boons for the world you will occupy this world. The consciousness becomes one with Shivji and Parvatiji and you become capable of bestowing boons on worthy souls.
6. Brahmalok ब्रह्मलोक - your consciousness cannot ascend here without losing selfhood and merging with Brahmaji and Saraswatiji. Brahmaji created you and he alone lives here with Saraswatiji. Brahmaji and Saraswatiji sometimes take avatars and they too will appear calm and unaffected by worldly turbulence.
Continued in part 4
1. Bhuvarlok भुवर्लोक - with a little humility and love your consciousness can ascend to bhuvarlok. Here are the devatas of the panchang, and grahas. The gods of panchang are the various gods of tithi, var, nakshatra, yog, karan and the navagrahas. All of these control your fortunes. Ascending here makes you aware of your karma and what will happen and what has happened in the past. You will live a life of alignment and zero anxiety and find a non-selfish, win-win purpose in every problem you encounter no matter how grave. With deeper empathy, humility and love you'll find yourself and everyone you care about winning even in poor astrological conditions. However, life won't be effortless even though it doesn't disturb you.
2. Swarlok स्वर्लोक - when you widen your care your consciousness eventually ascends to a higher perception, every sensory input will bring you heavenly pleasure, this world is occupied by Indra , Kuber, Vayu, Agni, Mitra and all the early Vedic gods and goddesses, it is devlok or a world of gods. It is highly possible to get addicted to sensory pleasure in this state of consciousness, you will be high, in pleasure 24/7, you will develop magical siddhis that challenge natural laws, it will rain when you wish for example, but the moment you stop caring you'll be thrown down into being ordinary again and that crash is quite brutal. That's why I tell my shishyas not to become a citizen of devlok, it's ok to visit sometimes but make sure to leave.
3. Maharlok महर्लोक - when you start to care about wins for the whole world you become a Rishi, maharlok is the hideout of Rishis. From here they can care for humans while not getting involved in worldly bondage. This is the first world of liberation. A person whose consciousness reaches here becomes free of bondage and can live a powerful life. Such a person also becomes immortal, they can also occupy multiple bodies at a single time. It is the favourite place of Maharishis, they live here during Kalyug, coming to Bhulok only when advanced humans need guidance. Gurus often occupy this place with their consciousness. So no worldly turbulence affects them. This is an ascetic world of silence where Rishis live with their Rishipatnis waiting for Kalyug to end and Mahavishnu's final avatar. They come down to bhulok after Mahavishnu takes birth and protect his cause.
4. Janarlok - जनर्लोक you need to really ascend your consciousness in deep love, humility and care to reach Janarlok. Only children of Brahma live here, like Narad and Sanat Kumaras, these are sages and need nothing, they exist to give and give without taking and their power to give is unlimited. They have no desire, humans on Bhulok give them purpose with their problems. They are masters of mantra and music and the Vedas. Brahmarishis who live on earth occupy this world in their consciousness. They too are not affected at all by worldly turbulence.
5. Tapolok तपोलोक - this place is also called Kailash because Shivji, Parvatiji and Ganeshji do tapasya here. When your consciousness ascends into the will to do tapasya to generate punya and var, merits and boons for the world you will occupy this world. The consciousness becomes one with Shivji and Parvatiji and you become capable of bestowing boons on worthy souls.
6. Brahmalok ब्रह्मलोक - your consciousness cannot ascend here without losing selfhood and merging with Brahmaji and Saraswatiji. Brahmaji created you and he alone lives here with Saraswatiji. Brahmaji and Saraswatiji sometimes take avatars and they too will appear calm and unaffected by worldly turbulence.
Continued in part 4

Most IMPORTANT muscle groups for AESTHETICS (ranked):
1. Shoulders
1. Shoulders


Most IMPORTANT muscle groups for aesthetics (ranked):
1. Shoulders
2. Back
3. Chest
4. Neck + Traps
5. Obliques
6. Brachialis (lower bicep)
Lucky for you there’s a blueprint for elite development in everything.
Keep reading.
1. Shoulders
2. Back
3. Chest
4. Neck + Traps
5. Obliques
6. Brachialis (lower bicep)
Lucky for you there’s a blueprint for elite development in everything.
Keep reading.
1. Shoulders:
You need to reach elite strength in overhead press (shoulder + military press).
You need to apply incredibly high volume + rep counts to the medial + rear delts through movements like lateral raises, rear delt flyes, Cuban presses, face pulls, etc.
3D + rounded.
You need to reach elite strength in overhead press (shoulder + military press).
You need to apply incredibly high volume + rep counts to the medial + rear delts through movements like lateral raises, rear delt flyes, Cuban presses, face pulls, etc.
3D + rounded.

#Breaking: Bombay High Court says it doesn't want a situation in the country where policemen fail to protect the citizens and especially the law abiding citizens of India. Police cannot give any type of VIP treatment to accused persons.
The High Court expressed displeasure over Maharashtra Police for producing Shiv Sena (Eknath Shinde) corporator Ramesh Mhatre through VC after his initial arrest in connection with a FIR lodged against him for assaulting 3 doctors in a Thane hospital.
#BombayHighCourt
The High Court expressed displeasure over Maharashtra Police for producing Shiv Sena (Eknath Shinde) corporator Ramesh Mhatre through VC after his initial arrest in connection with a FIR lodged against him for assaulting 3 doctors in a Thane hospital.
#BombayHighCourt

A division bench of Acting Chief Justice Ravindra Ghuge and Justice Gautam Ankhad said it will order enquiry against the officer who came up with the "innovative" idea of producing Mhatre virtually before the Magistrate for seeking his remand.
ACJ Ghuge: We want the name of this officer, who after arresting the accused came up with this innovative idea of producing him through VC. Either we will call the Commissioner of Police, Thane in court.
Advocate General Milind Sathe however, told the judges that when Mhatre was arrested, his vitals were checked and his BP was 160/100 so he was admitted and thus to ensure that the 24 hours time doesn't end, he was produced virtually.
#BombayHighCourt
ACJ Ghuge: We want the name of this officer, who after arresting the accused came up with this innovative idea of producing him through VC. Either we will call the Commissioner of Police, Thane in court.
Advocate General Milind Sathe however, told the judges that when Mhatre was arrested, his vitals were checked and his BP was 160/100 so he was admitted and thus to ensure that the 24 hours time doesn't end, he was produced virtually.
#BombayHighCourt
ACJ Ghuge: For blood pressure of 160/100 he was admitted? When we sit here in this court and some lawyers argue anything, even our BP goes 160/100. Even we should get admitted?
#BombayHighCourt
#BombayHighCourt

1/12 The Government released its Summer Economic Statement today, outlining its plans for Budget 2027. On a headline level, the Government plans a package of €8.5 billion, €7 billion of spending increases and €1.5 billion in tax reductions.
2/12 The Summer Economic Statement suggests a package of tax cuts in Budget 2027 of around €1.5 billion. This is slightly larger than the cost of adjusting the tax system so that people do not pay more tax as their incomes increase.
3/12 The vast majority of next year’s spending increase is for current spending. The Government plans to increase current spending by €5.9 billion and capital spending by €1.2 billion. Out of every €6 in spending increases, €5 is for current spending, while €1 is for capital


A guy had Gmail for 11 years and 41,000 unread emails.
His inbox was chaos — promotions mixed with invoices mixed with actual important stuff, buried three scrolls deep. Search never found what he needed on the first try. Storage kept warning him he was almost out, on a free account he swore he'd never filled up.
His sister works in IT support. She opened his Gmail on his laptop over coffee. Eight taps and two filters later, she closed the laptop.
His inbox showed maybe 12 emails that actually mattered that day. The rest sorted themselves — automatically — into folders he didn't have to build by hand. Storage freed up almost 3GB without him deleting a single email he cared about. Search started finding things instantly.
"Eleven years," he said, "and I never touched a single setting."
"Nobody does," she said. "Gmail ships built for 'good enough on day one,' not for eleven years of your actual life piling up in it."
Here's everything she changed.
His inbox was chaos — promotions mixed with invoices mixed with actual important stuff, buried three scrolls deep. Search never found what he needed on the first try. Storage kept warning him he was almost out, on a free account he swore he'd never filled up.
His sister works in IT support. She opened his Gmail on his laptop over coffee. Eight taps and two filters later, she closed the laptop.
His inbox showed maybe 12 emails that actually mattered that day. The rest sorted themselves — automatically — into folders he didn't have to build by hand. Storage freed up almost 3GB without him deleting a single email he cared about. Search started finding things instantly.
"Eleven years," he said, "and I never touched a single setting."
"Nobody does," she said. "Gmail ships built for 'good enough on day one,' not for eleven years of your actual life piling up in it."
Here's everything she changed.
1. What Gmail's defaults are actually optimized for
Gmail is free, and free means the defaults are built for the broadest possible audience doing the simplest possible thing — check inbox, read, reply, done. Nothing about the default setup expects eleven years of accumulation, aggressive marketing emails, or an inbox that's become the de facto filing cabinet for someone's entire financial and professional life.
So everything lands in one pile unless you tell it not to. Storage silently fills because cleanup isn't automatic. Search works fine for last week's email and struggles the moment there are 40,000 of them. None of this is broken — it's just tuned for a mailbox six months old, not eleven years deep.
Gmail is free, and free means the defaults are built for the broadest possible audience doing the simplest possible thing — check inbox, read, reply, done. Nothing about the default setup expects eleven years of accumulation, aggressive marketing emails, or an inbox that's become the de facto filing cabinet for someone's entire financial and professional life.
So everything lands in one pile unless you tell it not to. Storage silently fills because cleanup isn't automatic. Search works fine for last week's email and struggles the moment there are 40,000 of them. None of this is broken — it's just tuned for a mailbox six months old, not eleven years deep.
2. Turned on inbox categories/tabs properly
Settings → Inbox → Inbox type. Tabs (Primary, Social, Promotions, Updates) existed but were only half-configured — Promotions was mixing with Primary because he'd manually dragged things around years ago and broken the sorting.
She reset it to auto-categorize cleanly. Promotional emails, receipts, and social notifications started routing themselves out of Primary automatically. His actual inbox — the one he opens first — went from 40+ new emails a day to roughly 10.
Settings → Inbox → Inbox type. Tabs (Primary, Social, Promotions, Updates) existed but were only half-configured — Promotions was mixing with Primary because he'd manually dragged things around years ago and broken the sorting.
She reset it to auto-categorize cleanly. Promotional emails, receipts, and social notifications started routing themselves out of Primary automatically. His actual inbox — the one he opens first — went from 40+ new emails a day to roughly 10.

I did it. I figured out the perfect AI coding loop
It's called the Finn Loop and it's 100x'd my vibe code output while cutting down work by 95%
In this video I cover how to set it up
By the end you'll have your own software factory
+I completely open sourced it down below!
It's called the Finn Loop and it's 100x'd my vibe code output while cutting down work by 95%
In this video I cover how to set it up
By the end you'll have your own software factory
+I completely open sourced it down below!
Full Finn Loop repo here:
Enjoy! And let me know if you have any questions!github.com/finna/Finn-loop
Enjoy! And let me know if you have any questions!github.com/finna/Finn-loop

10 books to fall in love with ancient history:
1) 1177 B.C. by Eric Cline
1) 1177 B.C. by Eric Cline

2) SPQR by Mary Beard

3) The Spartans by Paul Cartledge


Публічний захист Сирського не припинився навіть після його відставки. Ба більше, він задає хибні рамки дискусії, бо, зокрема, говорить: не повинні солдати обирати генерала! Історія знає катастрофічні наслідки такої політики!
Це, звісно ж, правда, історія дійсно про таке знає. Але у нас і близько не відбулося нічого подібного.
У роки французької революції солдати почали обирати командирів — це одночасно об'єднало бійців новоствореної масової армії, якої не існувало раніше, і послугувало політичній меті, себто знищенню привілеїв дворянства, яке до того мало виключне право на офіцерську кар'єру.

Όταν σας λένε για το Μάτι σήμερα, ορίστε οι ένοχοι !
Σωτήρης Τερζούδης - τότε Αρχηγός του Πυροσβεστικού Σώματος.
Βασίλης Ματθαιόπουλος - τότε Υπαρχηγός του Πυροσβεστικού Σώματος.
Ιωάννης Φωστιέρης - τότε Διοικητής του Ενιαίου Συντονιστικού Κέντρου Επιχειρήσεων (ΕΣΚΕ).
🧶⬇️
Σωτήρης Τερζούδης - τότε Αρχηγός του Πυροσβεστικού Σώματος.
Βασίλης Ματθαιόπουλος - τότε Υπαρχηγός του Πυροσβεστικού Σώματος.
Ιωάννης Φωστιέρης - τότε Διοικητής του Ενιαίου Συντονιστικού Κέντρου Επιχειρήσεων (ΕΣΚΕ).
🧶⬇️
Ιωάννης Καπάκης - τότε Γενικός Γραμματέας Πολιτικής Προστασίας.
Χρήστος Γκολφίνος - τότε Διευθυντής του Κέντρου Επιχειρήσεων του Πυροσβεστικού Σώματος.
Φίλιππος Παντελεάκος - τότε Διευθυντής του Κέντρου Επιχειρήσεων Πολιτικής Προστασίας.
⬇️
Χρήστος Γκολφίνος - τότε Διευθυντής του Κέντρου Επιχειρήσεων του Πυροσβεστικού Σώματος.
Φίλιππος Παντελεάκος - τότε Διευθυντής του Κέντρου Επιχειρήσεων Πολιτικής Προστασίας.
⬇️
Δαμιανός Παπαδόπουλος- τότε Διοικητής της Πυροσβεστικής Υπηρεσίας Νέας Μάκρης.
Νικόλαος Παναγιωτόπουλος - τότε Διοικητής Πυροσβεστικών Υπηρεσιών Αθηνών.
Χαράλαμπος Χιώνης - τότε Διοικητής Πυροσβεστικών Υπηρεσιών Ανατολικής Αττικής.
⬇️
Νικόλαος Παναγιωτόπουλος - τότε Διοικητής Πυροσβεστικών Υπηρεσιών Αθηνών.
Χαράλαμπος Χιώνης - τότε Διοικητής Πυροσβεστικών Υπηρεσιών Ανατολικής Αττικής.
⬇️

One of the most exhausting parts of creating content in Lagos isn’t the filming. It’s dealing with touts who show up the moment you set up a camera.
You’re not blocking the road. You’re not filming strangers. You’re simply working with your actors in a public space. Yet you’re…
You’re not blocking the road. You’re not filming strangers. You’re simply working with your actors in a public space. Yet you’re…
expected to pay people who have no legal authority over the location. Refuse, and you’re met with threats to damage equipment worth millions of naira.
We’ve normalized something that shouldn’t be normal.
Creators shouldn’t have to negotiate with people just…
We’ve normalized something that shouldn’t be normal.
Creators shouldn’t have to negotiate with people just…
to do legitimate work in a public place. Every hour spent dealing with intimidation is time taken away from creating, earning, and contributing to the economy.
This isn’t just my experience. Many content creators in Lagos, from…
This isn’t just my experience. Many content creators in Lagos, from…

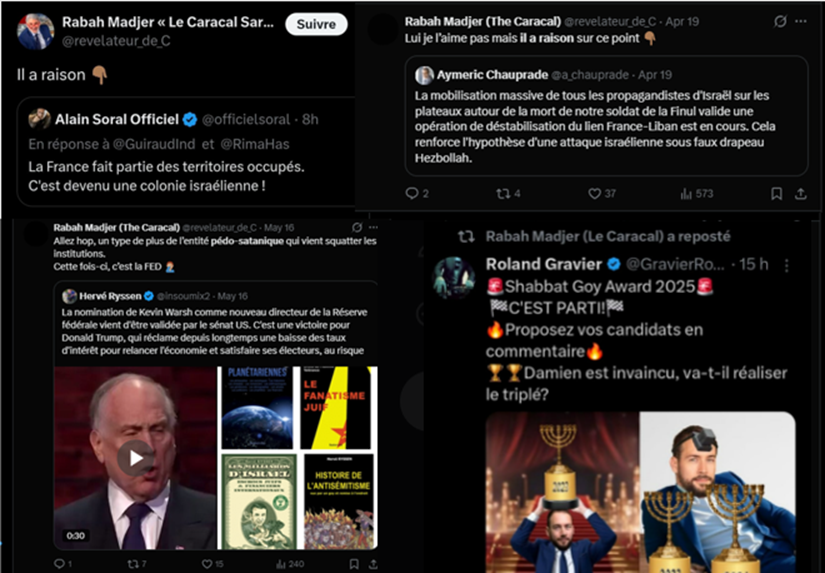
Il y a 5 jours je vous proposais une courte monographie des "influenceurs" roulant pour LFI chargés de rameuter la génération soral/dieudo au profit des Insoumis.
Je déclenchais là l'ire de ce bon Mourad Guichard, au-dessus de tout soupçon.
Mais, bon bougre, une fois...🧵
Je déclenchais là l'ire de ce bon Mourad Guichard, au-dessus de tout soupçon.
Mais, bon bougre, une fois...🧵
...l'indignation passée, il a tenu discrètement (on reconnait là son humilité) à me donner raison. Parce que l'éthique et l'honnêteté intellectuelle, c'est son truc.
Le voilà donc qui poste 2 jours après notre esclandre un joli message à destination d'un "camarade" disparu.
Le voilà donc qui poste 2 jours après notre esclandre un joli message à destination d'un "camarade" disparu.

Et quel bon camarade !
Un fier représentant de la gauche de rupture. Et la rupture avec la gauche, on ne pourra pas lui dénier.
Le mec retweetait plus de néo-nazis que Quentin Deranque (Soral, Ratier, Ryssen, Chauprade...). A ça de proposer 1mn de silence à l'AN.
Un fier représentant de la gauche de rupture. Et la rupture avec la gauche, on ne pourra pas lui dénier.
Le mec retweetait plus de néo-nazis que Quentin Deranque (Soral, Ratier, Ryssen, Chauprade...). A ça de proposer 1mn de silence à l'AN.

TŘETÍ JEZDEC APOKALYPSY
1/9) Ve východních stepích Evropy se ozval tikot bomby, která má sílu zničit celé regiony, a přesto ji neodpálí jaderné tlačítko.
Lidstvo čelí nepříteli, který neútočí za hřmotu dělostřelectva, plíží se krevním řečištěm a devastuje samotné biologické základy budoucích generací. Hlad je odjakživa největším, plíživým nepřítelem lidstva. Právě teď opět míří na scénu.
Namísto moru přinesl první jezdec Covid, pak se přiřítila válka. Teď díky globalizované planetě přichází hlad a pokud nic neuděláme, tak už je spočítáno kolik milionů zahubí a o kolik schudneme.
Ááno, přijdeme o penízky. O hodně penízků. Věc na kterou by měl slyšet i @realDonaldTrump, ale bohužel tomu tak není.
Obilnice světa nedodají hladovým krků obilí. Ne tolik, kolik je třeba. Ne za cenu, kterou si mohou dovolit.
A dopady? Ty si umíme bez datových modelů jen obtížně představit. ⬇️
1/9) Ve východních stepích Evropy se ozval tikot bomby, která má sílu zničit celé regiony, a přesto ji neodpálí jaderné tlačítko.
Lidstvo čelí nepříteli, který neútočí za hřmotu dělostřelectva, plíží se krevním řečištěm a devastuje samotné biologické základy budoucích generací. Hlad je odjakživa největším, plíživým nepřítelem lidstva. Právě teď opět míří na scénu.
Namísto moru přinesl první jezdec Covid, pak se přiřítila válka. Teď díky globalizované planetě přichází hlad a pokud nic neuděláme, tak už je spočítáno kolik milionů zahubí a o kolik schudneme.
Ááno, přijdeme o penízky. O hodně penízků. Věc na kterou by měl slyšet i @realDonaldTrump, ale bohužel tomu tak není.
Obilnice světa nedodají hladovým krků obilí. Ne tolik, kolik je třeba. Ne za cenu, kterou si mohou dovolit.
A dopady? Ty si umíme bez datových modelů jen obtížně představit. ⬇️

ZMATENÍ ALGORITMŮ - Aneb co když se všichni pletou?
2/9) Před vypuknutím finanční krize v roce v USA všichni věřili analytikům. Věřili frázi "kdo by neplatil hypotéku". Pak přišlo tvrdé vystřízlivění a jako ochranu jsme zvolili matematické modely. Algoritmy přece nelžou ne?
A právě to stojí na počátku smrtící chyby, která nám z rozpočtů odsaje až 200 miliard dolarů a zahubí miliony lidí.
Kde se stala chyba? 😳
Letošní úroda obilí vypadá ze všech úhlů pohledu fantasticky. Satelitní snímky ukazovaly zasetá zelená pole, sklizeň v USA začala překvapivě dobře a sklízelo se rychleji, než je běžné...
Fondy, sázející primárně na příznivé počasí, nahromadily přes 90 000 krátkých pozic (sázek na pokles ceny) u pšenice. Trh tak očekával levné obilí.
A protože předchozí roky války na Ukrajině ukázaly, že situace s vývozem obilí je zvládnutelná, tak prostě modely riziko další eskalace v zásadě ignorovali.
Nějak opomenuli, že přechod z konfliktu do poslední fáze - kdy je cílem zničit jakoukoliv ekonomickou aktivitu nepřítele přináší podstatně odlišné podmínky.
2/9) Před vypuknutím finanční krize v roce v USA všichni věřili analytikům. Věřili frázi "kdo by neplatil hypotéku". Pak přišlo tvrdé vystřízlivění a jako ochranu jsme zvolili matematické modely. Algoritmy přece nelžou ne?
A právě to stojí na počátku smrtící chyby, která nám z rozpočtů odsaje až 200 miliard dolarů a zahubí miliony lidí.
Kde se stala chyba? 😳
Letošní úroda obilí vypadá ze všech úhlů pohledu fantasticky. Satelitní snímky ukazovaly zasetá zelená pole, sklizeň v USA začala překvapivě dobře a sklízelo se rychleji, než je běžné...
Fondy, sázející primárně na příznivé počasí, nahromadily přes 90 000 krátkých pozic (sázek na pokles ceny) u pšenice. Trh tak očekával levné obilí.
A protože předchozí roky války na Ukrajině ukázaly, že situace s vývozem obilí je zvládnutelná, tak prostě modely riziko další eskalace v zásadě ignorovali.
Nějak opomenuli, že přechod z konfliktu do poslední fáze - kdy je cílem zničit jakoukoliv ekonomickou aktivitu nepřítele přináší podstatně odlišné podmínky.
RUSKÝ PARADOX A KOGNITIVNÍ SLEPOTA TRHŮ
3/9) Nejzajímavější proměnnou současných modelů je situace v Rusku. Přestože úroda vypadá papírově fantasticky, analytici varují před logistickým kolapsem.
Dronové údery na rafinérie v Omsku, Rjazani a Volgogradu poškodily podle odhadů již téměř polovinu ruské kapacity pro zpracování ropy. A zatímco export Ropy je na svých maximech, v Rusku propukají lokální palivové paralýzy.
Zemědělské podniky v klíčových regionech (Krasnodar, Rostov) hlásí příděly v rozmezí pouhých 20 až 200 litrů nafty na subjekt, přičemž těžká sklízecí mlátička spotřebuje kolem 300 litrů za jedinou směnu. Doba čekání na cisterny se prodlužuje z běžných tří dnů na pět až deset.
Pšenice přitom poskytuje jen úzké okno 7 až 10 dnů pro sklizeň v optimální potravinářské kondici. Pokud toto okno farmáři kvůli nedostatku nafty nestihnou, zrno biologicky zdegeneruje. Až 15 milionů tun prvotřídní pšenice určené pro lidskou spotřebu tak podle varování agronomů může ztratit své pekařské vlastnosti a degradovat na krmivo. Rychlost sklizně tomuto scénáři odpovídá – k 1. červenci hlásily statistiky sklizeno jen 1,3 až 1,5 milionu hektarů oproti obvyklým 4,2 až 4,6 milionu.
Do toho přišla situace s kterou algoritmy také nepočítaly.
Místní obilná sila jsou přeplněná obilím, které ale není jak vyvézt. I pokud zemědělci obilí sklidí, nemají jistotu, že ho budou mít kde uskladnit a usušit. Cena exportu je prostě tak vysoká a logistické trasy tak rozbité, že se farmářům vyplatí nechat shnít úrodu na polích.
Pokud však fyzické dodávky nedorazí a dojde k výpadkům, modely predikují takzvaný „short squeeze“ – panické a nucené uzavírání krátkých pozic. Ke kterému s největší pravděpodobností dojde. Nucené výkupy - snaha uzavřít ztrátové pozice za každou cenu by mohly cenu s obilím vystřelit do astronomických výšin.
Poznámka: Tento článek není investiční radou. Naopak. Pokud chcete udělat něco pro sebe a své budoucí štěstí, zvažte podporu obránců Východní hranice Evropy. Je to důležitější, než jakákoliv bláznivá spekulace na burze.
Podpořit je můžete třeba zde 👉darujme.cz/vyzva/1205541
3/9) Nejzajímavější proměnnou současných modelů je situace v Rusku. Přestože úroda vypadá papírově fantasticky, analytici varují před logistickým kolapsem.
Dronové údery na rafinérie v Omsku, Rjazani a Volgogradu poškodily podle odhadů již téměř polovinu ruské kapacity pro zpracování ropy. A zatímco export Ropy je na svých maximech, v Rusku propukají lokální palivové paralýzy.
Zemědělské podniky v klíčových regionech (Krasnodar, Rostov) hlásí příděly v rozmezí pouhých 20 až 200 litrů nafty na subjekt, přičemž těžká sklízecí mlátička spotřebuje kolem 300 litrů za jedinou směnu. Doba čekání na cisterny se prodlužuje z běžných tří dnů na pět až deset.
Pšenice přitom poskytuje jen úzké okno 7 až 10 dnů pro sklizeň v optimální potravinářské kondici. Pokud toto okno farmáři kvůli nedostatku nafty nestihnou, zrno biologicky zdegeneruje. Až 15 milionů tun prvotřídní pšenice určené pro lidskou spotřebu tak podle varování agronomů může ztratit své pekařské vlastnosti a degradovat na krmivo. Rychlost sklizně tomuto scénáři odpovídá – k 1. červenci hlásily statistiky sklizeno jen 1,3 až 1,5 milionu hektarů oproti obvyklým 4,2 až 4,6 milionu.
Do toho přišla situace s kterou algoritmy také nepočítaly.
Místní obilná sila jsou přeplněná obilím, které ale není jak vyvézt. I pokud zemědělci obilí sklidí, nemají jistotu, že ho budou mít kde uskladnit a usušit. Cena exportu je prostě tak vysoká a logistické trasy tak rozbité, že se farmářům vyplatí nechat shnít úrodu na polích.
Pokud však fyzické dodávky nedorazí a dojde k výpadkům, modely predikují takzvaný „short squeeze“ – panické a nucené uzavírání krátkých pozic. Ke kterému s největší pravděpodobností dojde. Nucené výkupy - snaha uzavřít ztrátové pozice za každou cenu by mohly cenu s obilím vystřelit do astronomických výšin.
Poznámka: Tento článek není investiční radou. Naopak. Pokud chcete udělat něco pro sebe a své budoucí štěstí, zvažte podporu obránců Východní hranice Evropy. Je to důležitější, než jakákoliv bláznivá spekulace na burze.
Podpořit je můžete třeba zde 👉darujme.cz/vyzva/1205541

VA HILO
Otra empresa extinguida desde hace mas de siete años , subiendo actos al Borme. Y recibiendo adjudicaciones millonarias. NEDGIA RIOJA SA. EXTINGUIDA (08/10/2018). 3.996.975,00 € 20/07/2026 dos adjudicaciones con la misma convocatoria y el mismo dia.
Otra empresa extinguida desde hace mas de siete años , subiendo actos al Borme. Y recibiendo adjudicaciones millonarias. NEDGIA RIOJA SA. EXTINGUIDA (08/10/2018). 3.996.975,00 € 20/07/2026 dos adjudicaciones con la misma convocatoria y el mismo dia.
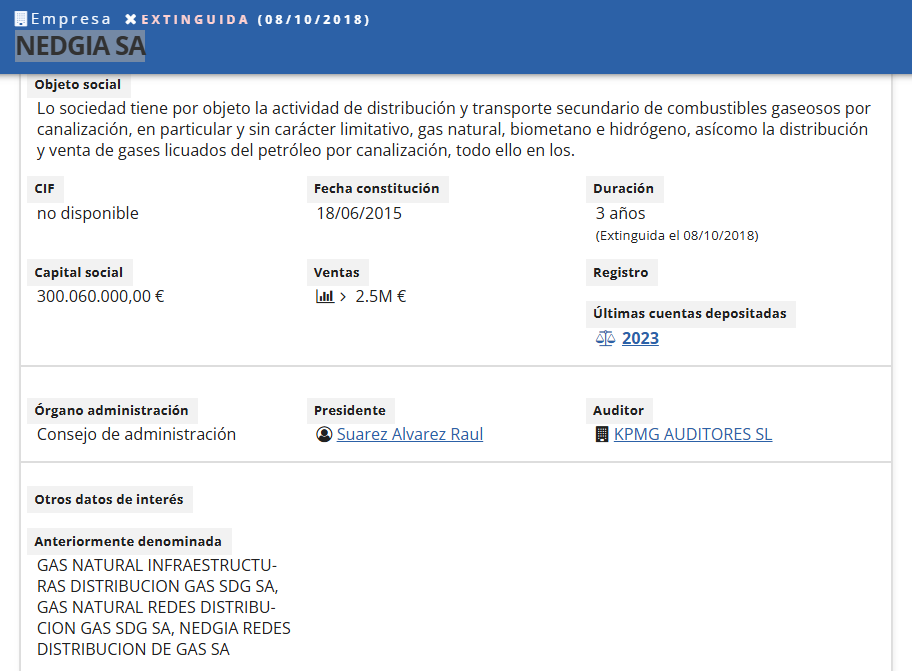



Mas claro agua no? y hay muchisimas empresas extinguidas recibiendo adjudicaciones millonarias de la administracion. en este caso de CONSEJERÍA DE ECONOMÍA, INNOVACIÓN, EMPRESA Y TRABAJO AUTÓNOMO. LA RIOJA


@threadreaderapp unroll

Tylko prawda jest ciekawa, więc postanowiłem sprawdzić jak to naprawdę było z poparciem @MorawieckiM dla kandydatury @NawrockiKn. Wygląda na to, że część polityków @pisorgpl myśli, że mamy pamięć rybek akwariowych. Nie mamy. Jedziemy:

Najwcześniejsza konkretna wzmianka, jaką udało mi się znaleźć pochodzi z 24 listopada 2024 roku z "Tygodnika Powszechnego". Wtedy Karol Nawrocki był już ogłoszony oficjalnie kandydatem obywatelskim wspieranym przez PiS. Wiadomo też, że Morawiecki brał udział w ostatecznej selekcji. W TP czytamy:
"W ostatniej fazie głównymi kandydatami byliPrzemysław Czarnek, Tobiasz Bocheński i Karol Nawrocki, a Morawiecki ostatecznie znalazł się w grupie osób wspierających Nawrockiego".
"W ostatniej fazie głównymi kandydatami byliPrzemysław Czarnek, Tobiasz Bocheński i Karol Nawrocki, a Morawiecki ostatecznie znalazł się w grupie osób wspierających Nawrockiego".
@MorawieckiM @NawrockiKn @pisorgpl O tej samej potencjalnej trójce kandydatów pisała wcześniej Polska Agencja Prasowa, dla której oficjalnie wypowiedział się Morawiecki (a nieoficjalnie poinformował, że największe szanse ma Nawrocki).


@virginiafoxx 1/13 Despicable...that's the word that comes to mind when I think of your little speech you gave on the House floor about Voter ID and the Save Act, the most RACIST bill I think I have EVER seen. YOU, Virginia, out here peddling this election fraud BULLSHIT is
2/13 disgusting. You are just ANOTHER USELESS ReTRUMPlican out here too scared shitless to do the RIGHT THING protecting our Democratic form of government that has lasted 250 YEARS, peddling the LIES of your Führer. And now you think it's funny comparing the Olive Garden's Pasta
3/13 Pass to our elections. What Trump and you ReTRUMPlicans are trying to do regarding photo ID is the PERFECT bait and switch...I BET you if you go to the Olive Garden, they DON'T say that your driver's license is from out of state and so you can't vote. I'll also wager that