
Deep Dive Explanation of Approach / Analysis : I want to provide the context of the work I am doing, and the reasoning behind it. I started this with a question : Why did R's do so well down ballot, and not at the top? In order to answer this question, I needed a suitable dataset
2. The ideal dataset would allow us to see, for each batch of ballots, the landscape of the votes (e.g. which candidates received the votes, and by what proportions). And not just any batch would suffice to perform this analysis.
3. Batches of ballots needed to be large (e.g. many ballots), and must include votes for Prez, Senate, and House Rep for both Dems and Reps (3 races x 2 parties). The batch is a self contained example of voting behavior, that would be random within a district.
4. By having all these attributes, we would have clean examples to understand how that batch of the electorate cast their votes. This would give us a glimpse of the overall picture for the rest of the batches in that district. Now, what is the purpose of this analysis?
5. This analysis will reveal how ballots were cast. The data is after the tabulation process has been run, and the votes determined for the candidates in the race. The tabulation machines are an automated process that should produce consistent results (calculate the same way).
6. When you have the same automated process deployed in multiple locations, it is important to compare the trends and patters across these locations in order to identify anomalies and issues. This is a necessary validation and QC step to be confident all processes operate thesame
7. Differences in the patterns across these processes indicate not all the processes are operating the same way. My analyses are to show the patterns across the districts and see how patterns variety. Think of it as a process audit, not a ballot audit.
8. Processes can be manipulated, and when that occurs this type of analysis leads us to the affected process(es). Let's look at a comparison between VA-1 vote patterns and VA-2 vote patters from the batches that meet the criteria specified earlier. To help, here is a district map 
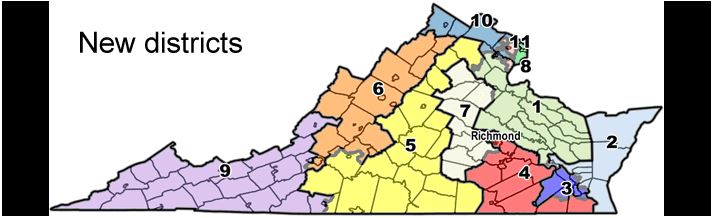
9. From the map, VA-1 and VA-2 neighbor each other. So let's see how voting patterns are different across these two districts. Here are their voting behaviors in the batches. VA-1 show's that votes are consistently going one way (to Dems). Why?
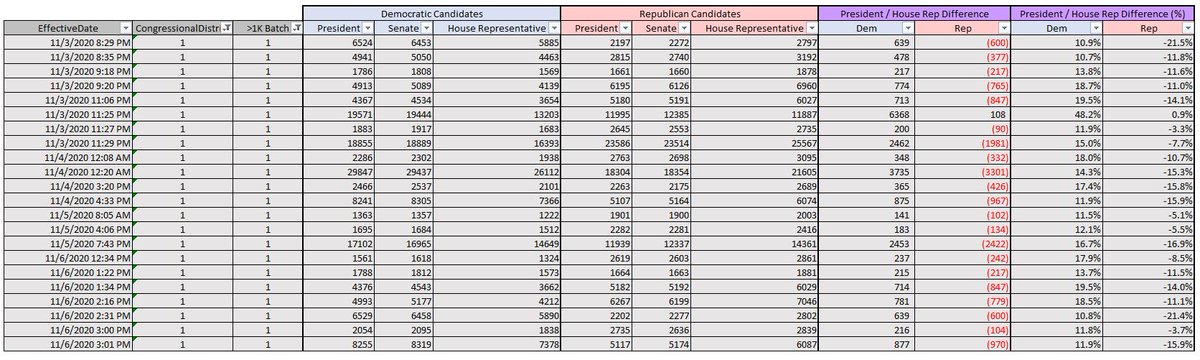

10. Is it possible that split ticket voters only exist in the Republican party? I don't believe so. The symmetry of these differences between Dem and Rep is startling. How is it that batch after batch in VA-1, there is the same proportion of R votes going to Dem candidates?
11. This would require these batches of random ballots to be perfect mixes each and every time. That is not naturally possible. It is only possible when viewed as the result of a manipulated process. It's something I am familiar w/ from working in corporate fraud investigations.
12. We don't see this patter in VA-2. Why? Because the process hasn't been manipulated. We see some differences, but there isn't the same consistent patter in batch after batch after batch. This is natural result. So what does this mean? How could this have happened?
13. Two possibilities for why the process is different in VA-1. First, the machine is configured differently than VA-2. This means the machine is doing as it was instructed, and improperly counting R votes as D votes. Second, when results are sent they are altered in between.
14. I believe it is more likely that the machines are configured incorrectly, and therefore generating incorrect totals, which are then sent to central office. Either way, a manual recount will confirm the issue. More importantly, this analysis could be done for every state.
15. This would be far more efficient that a full manual recount. It should be a test to see if a manual recount is necessary. The districts with these patterns should be manually recounted, and a team should investigate the configuration of the machines.
15. On the politics of this issue : people are stressing "voter fraud" in the election. While undoubtedly some did occur, like with most elections. Ultimately, it is a distraction from the core issue. This is election interference on a scale I couldnt imagine prior tothe analysis
16. I have collected the same files for 2016 and 2012 in order to perform the same analysis. As a US citizen, I must know if this has occurred before. I'll be dedicating all of my time next week to answering this question. I welcome anyone who has time and talent to assist.
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh




