
Limitations of High-Level Analyses Part 2 : Some out there are taking Dr Shiva's analysis and replicating it for Democratic votes to compare and see if the pattern is different. From a couple I've seen, there is a similar downward linear pattern that's less steep.
2. This has led some to conclude that this is in fact a natural pattern that has naturally occurred as the result of the local the electorate, and therefore, there's nothing untoward about the pattern. If it's happening for both Ds and Rs, it can't be a problem. Right? No!
3. When you see the same downward linear slope, it doesn't mean the local electorate is uniquely voting in those areas. It means that manipulation is occurring on both sides. The different in the steepness of the pattern allows to understand the severity of the manipulation.
4. Or said another way, the difference in steepness for Rs and Ds tells us the net / overall effect and direction of the manipulation. It doesn't mean that manipulation is not occurring. As I said in my last thread, these are the tabulated results of the ballots.
5. Well, how do we know for sure manipulation is occurring in both directions. Let's compare two different districts. Last time it was VA-1 and VA-2. Let's look at VA-5 and VA-6 this time. The shifting in VA-5 is slightly in favor of Trump. VA-6 is heavily in favor of Biden. Why? 
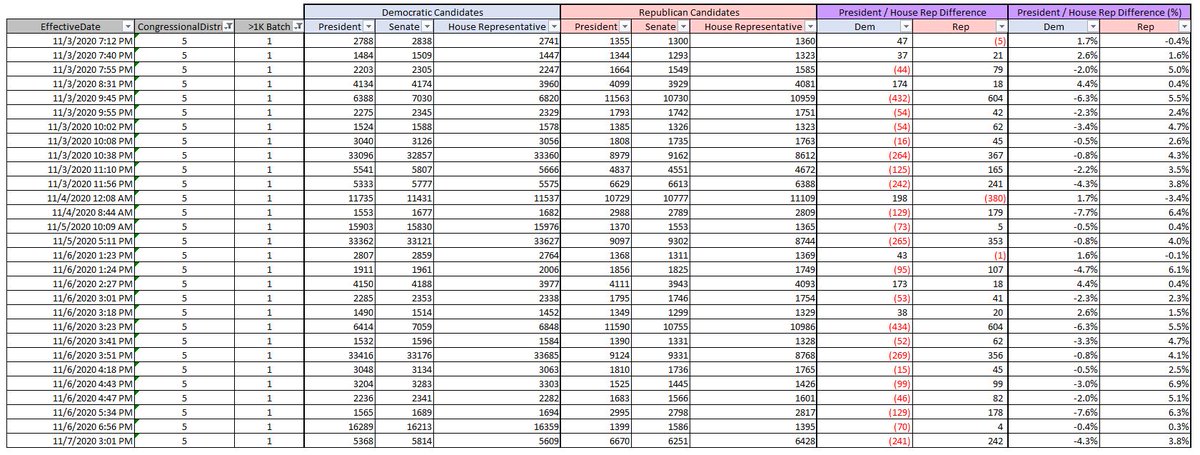

6. I believe it's to create similar patterns in both directions that will undermine a high-level analysis that compares the two. The is effective when analysts do not have access to batch level detail. Because overall, we see a mixture of results from various tabulation machines.
7. It is not reasonable to assume that all machines would incorrectly tabulate in the exact same way across a state. Even within a district, it's unreasonable to assume that to be the case. Same for a precinct. In my local precinct, there were 3 on election day.
8. This is why high level analysis is only good at showing that manipulation occurs, but it's very limited in its ability to measure the impact. This is why Dr. Shiva says a minimum of X votes were shifted. He doesn't have the granular data (machine / batch) details to make a
9. a more accurate assessment / determination. He receives criticism for this, but it's the only alternative when the data is an amalgamation of manipulated and non-manipulated batches of ballots. His estimate is imperfect to be sure, but it's the only method widely applicable!
10. We need to make something clear about the high-level voting results. It's limited in determining the impact of the manipulation, and it is also limited in it's usefulness as a representation of how the electorate votes. The manipulation belies the critics of Dr. Shiva.
11. What is ultimately needed is public data for each tabulator and the results for each batch it produced. This will tell us where manipulation occurs, when batch after batch produces the same skewed pattern. We will know which machines are affected.
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh




