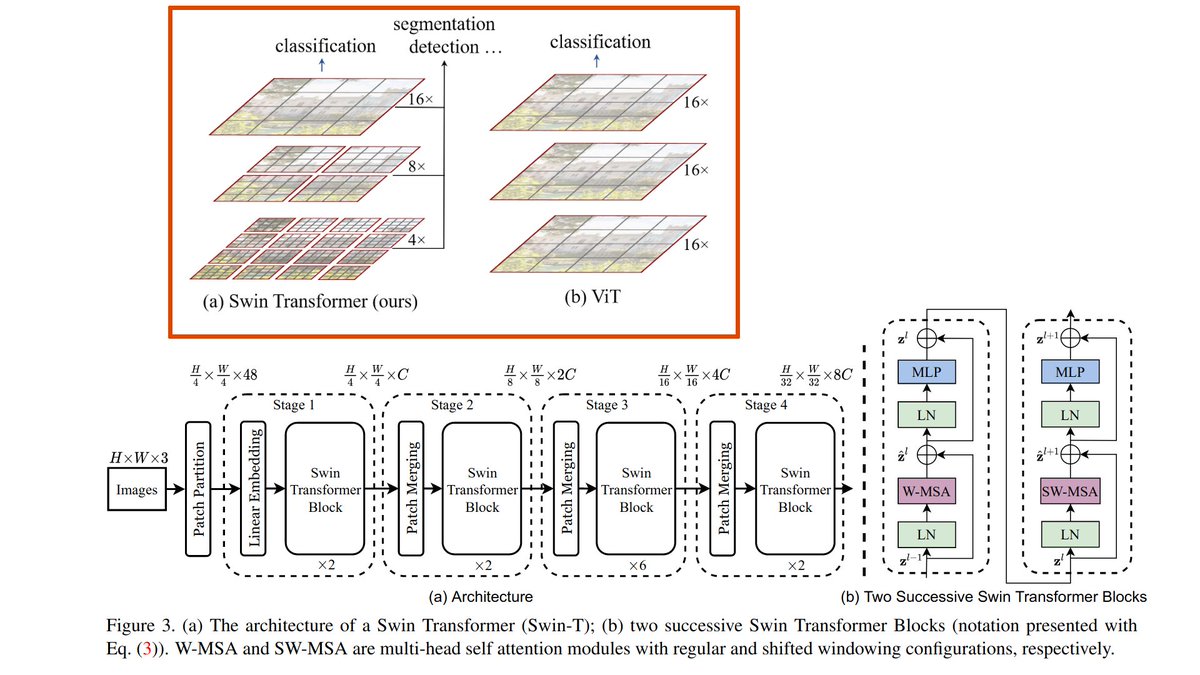
Spectacular Image Stylization using CLIP and DALL-E
As a Style Transfer Dude, I can say that this is super cool. A statue of David by Michelangelo was used as an input image. Then it was morphed towards different styles of famous artists by steering the latent code towards...
👇
As a Style Transfer Dude, I can say that this is super cool. A statue of David by Michelangelo was used as an input image. Then it was morphed towards different styles of famous artists by steering the latent code towards...
👇
1/..towards the embeddings of a textual description in CLIP space
I especially like Picasso's Cubism where it created a half-bull half-human portrait which is one of the typical sujets of Picasso. Rene Magritte stylization is my second favorite.
🤙Colab colab.research.google.com/drive/1oA1fZP7…
I especially like Picasso's Cubism where it created a half-bull half-human portrait which is one of the typical sujets of Picasso. Rene Magritte stylization is my second favorite.
🤙Colab colab.research.google.com/drive/1oA1fZP7…
2/ Original youtube video with more results
3/ I discussed similar techniques for image editing here t.me/gradientdude/2… and here t.me/gradientdude/1…
👇Join my Telegram channel to read about them.
👇Join my Telegram channel to read about them.
• • •
Missing some Tweet in this thread? You can try to
force a refresh