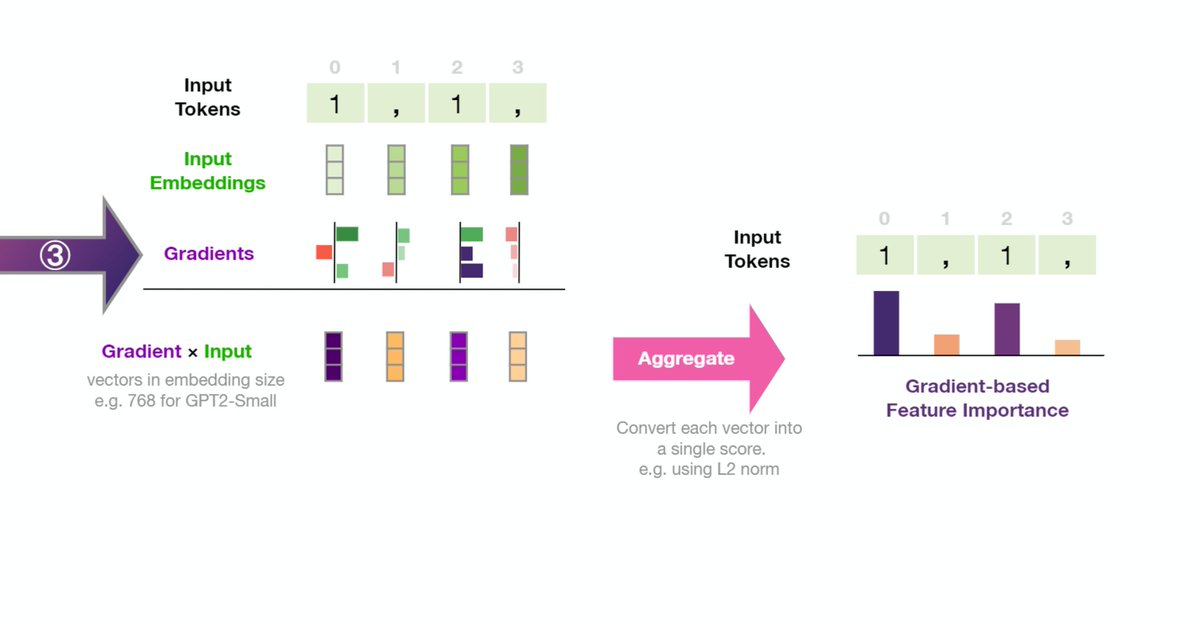
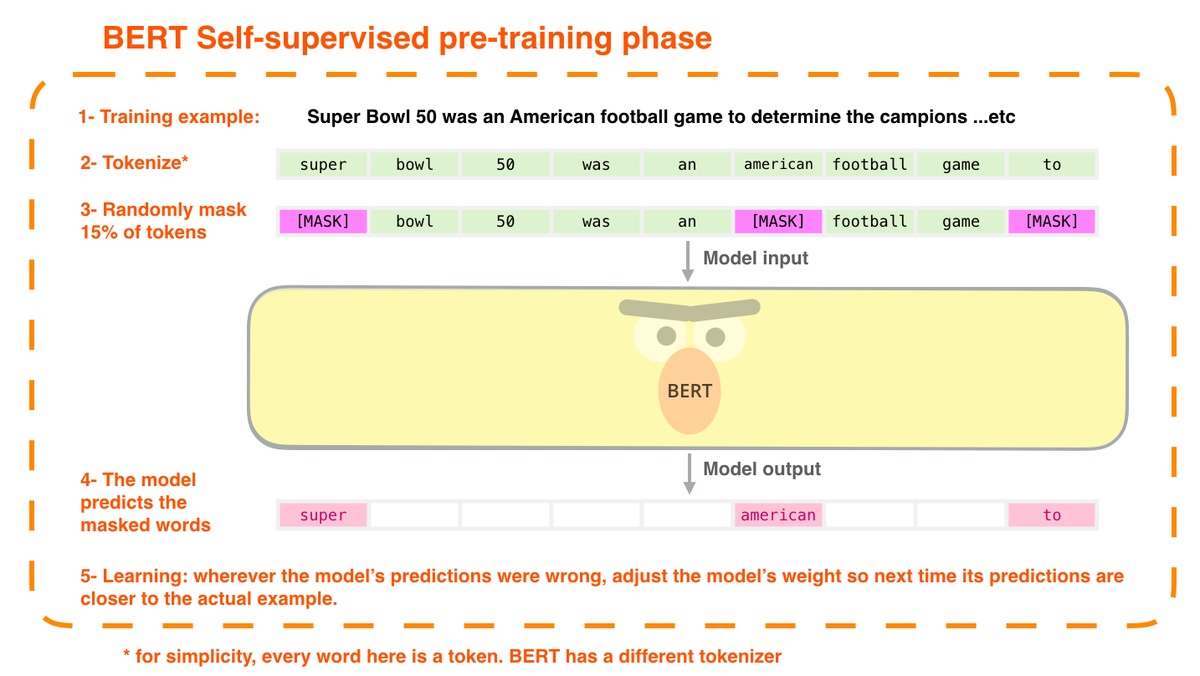
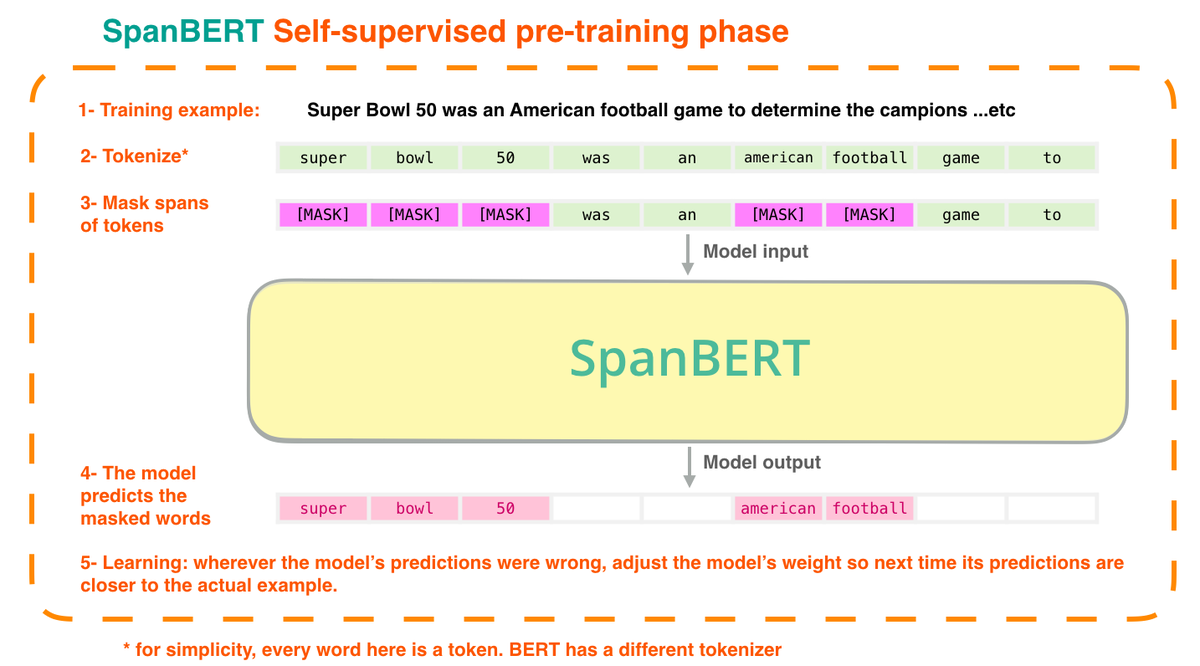
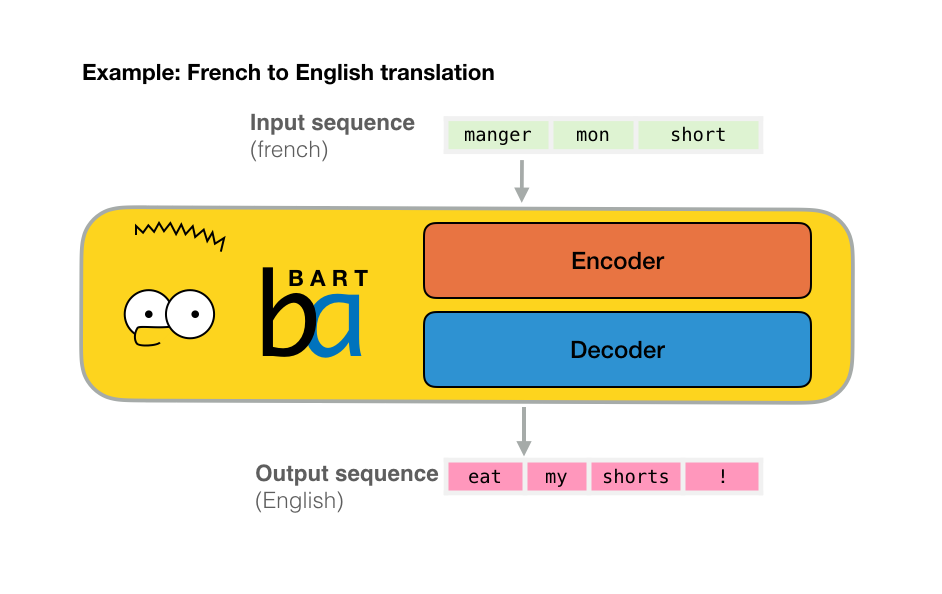
Ecstatic to see "Machine learning research communication via illustrated and interactive web articles" published at @rethinkmlpapers workshop at #ICLR2021
In it, I describe my workflow for communicating ML to millions of readers.
Paper: openreview.net/pdf?id=WUrcJoy…
1/5
In it, I describe my workflow for communicating ML to millions of readers.
Paper: openreview.net/pdf?id=WUrcJoy…
1/5

I discuss five key ML communication artifacts:
1- The hero image
2- The Twitter thread
3- The illustrated article
4- The interactive article
5- Interpretability software
Here are excellent examples of 1 and 2 from @ch402, @karpathy , and @maithra_raghu.
2/5
1- The hero image
2- The Twitter thread
3- The illustrated article
4- The interactive article
5- Interpretability software
Here are excellent examples of 1 and 2 from @ch402, @karpathy , and @maithra_raghu.
2/5

For illustrated/animated articles, I discuss the importance of empathy towards the reader, putting intuition first, the importance of iteratively creating visual language to describe concepts, and reflect on pedagogical considerations.
3/5
3/5

The paper points to some of my favorite examples of ML/systems/interpretability communication from @adamrpearce @betty_v_a @jesse_vig @lilianweng @OriolVinyalsML @srush_nlp @seb_ruder @hen_str @iftenney @worrydream @ylecun & others.
4/5
4/5
Join us May 9 at Beyond static papers: Rethinking how we share scientific understanding in ML - ICLR 2021 workshop
rethinkingmlpapers.github.io
I'll be doing a presentation on the paper. Exciting!
5/5
rethinkingmlpapers.github.io
I'll be doing a presentation on the paper. Exciting!
5/5
• • •
Missing some Tweet in this thread? You can try to
force a refresh