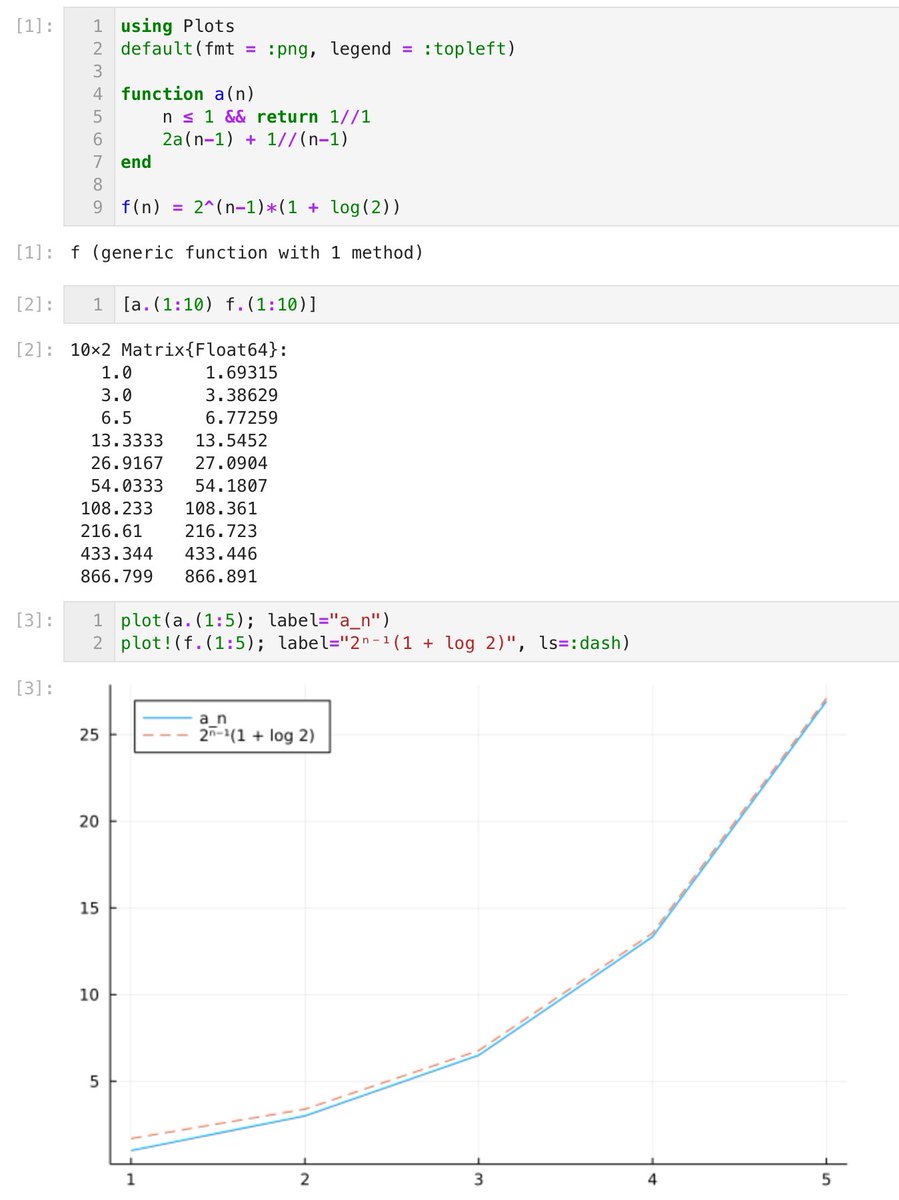
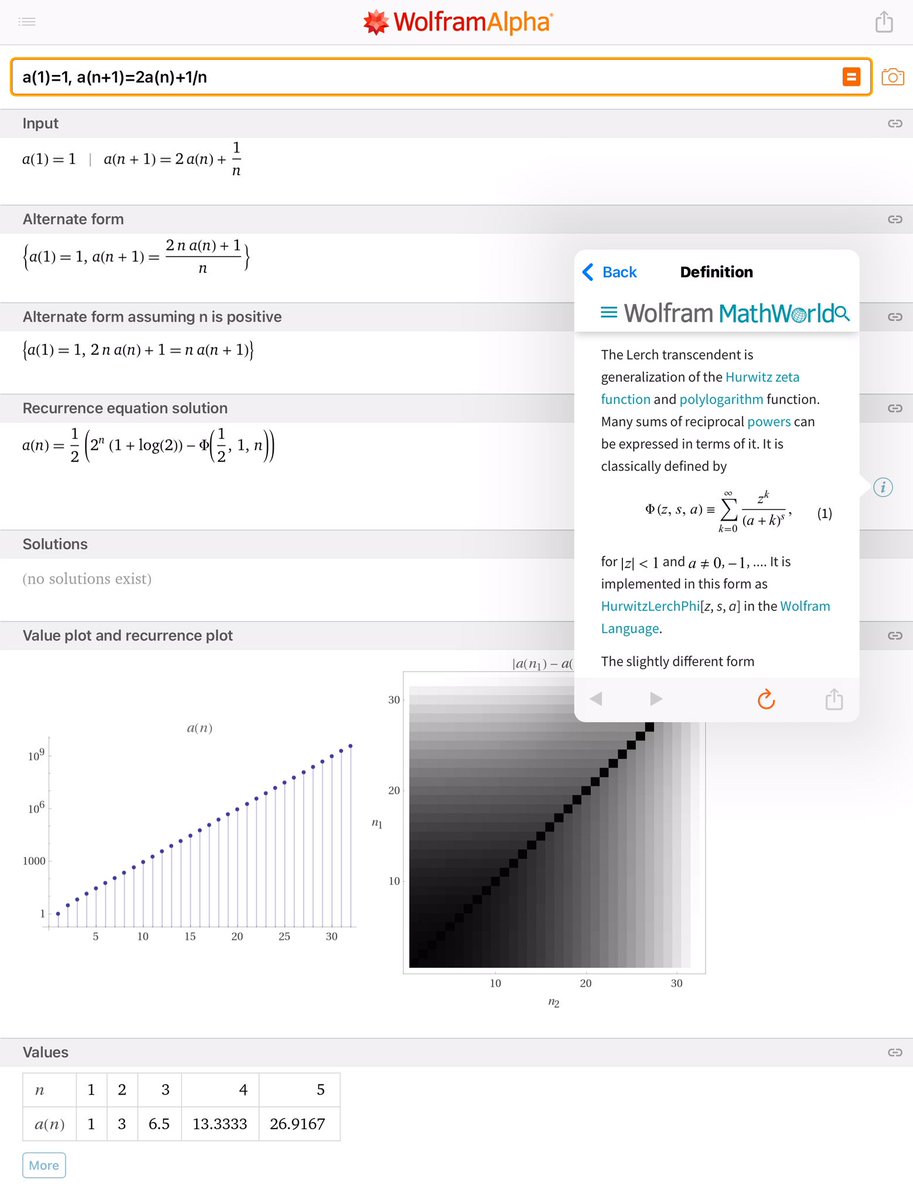
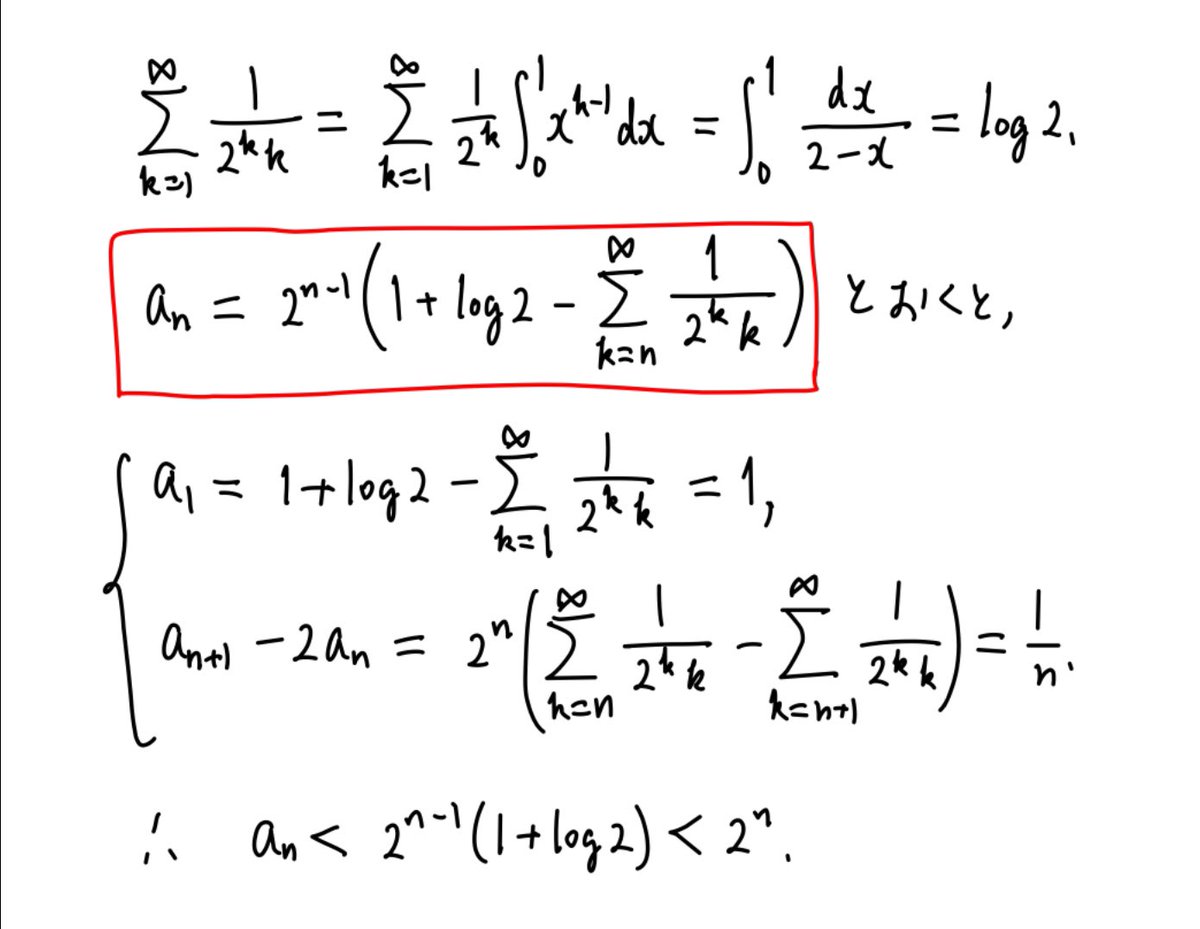#統計 繰り返し述べていることですが、95%信頼区間の誤解する可能性の低い定義の仕方は「データから有意水準5%の検定で棄却されない(統計モデルの)パラメータの範囲」です。
例えば、パラメータは「ワクチンの効果」の指標を意味していたりする。
例えば、パラメータは「ワクチンの効果」の指標を意味していたりする。
#統計 「検定で棄却されないこと」は「データからはそういう可能性があることに配慮し続ける必要があるという程度のことしか言えない」ということに過ぎず、棄却されないから正しいかのように考えてはいけない。
これは検定論のイロハのイにあたること。
これは検定論のイロハのイにあたること。
#統計 例えば、ワクチンの効果の大きさと解釈されるパラメータを持つ統計モデルを適切に設定したとき、データから計算したそのパラメータの95%信頼区間が0をまたいでいたとする。
#統計 実際には、統計モデルが実際のデータの取得の仕方と整合していないせいでそういう結果が得られた可能性やその他諸々の失敗の可能性も疑う必要がある。単に得られたデータが運悪くひどく偏っていた可能性さえある。
そういう諸々の事柄を無視してもその程度のことしか言えない。
そういう諸々の事柄を無視してもその程度のことしか言えない。
#統計 そういう弱い結論しか出せない信頼区間であっても、あるとないでは大違いです。
ワクチンの効果がどのくらいの期間有効であるかに関する目安は現実の意思決定に必要な情報です。
統計学は、「お墨付き」を得るためには使えないが、複雑な現実世界に立ち向かうためには必須の道具だと思います。
ワクチンの効果がどのくらいの期間有効であるかに関する目安は現実の意思決定に必要な情報です。
統計学は、「お墨付き」を得るためには使えないが、複雑な現実世界に立ち向かうためには必須の道具だと思います。
#統計 非常に不幸なことに、経歴的に高等教育を受けているはずなのに、社会的な意思決定に関わる重大な事柄について、真っ当な意見を述べている人たちを馬鹿にするために統計学を使って得られた結果についてめちゃくちゃな解釈を堂々と述べて利用する人がいる。単なる間違いとは違った邪悪さがある。
#統計 そういう邪悪な人に騙されずに済むように、さまざまな教養を身につけておくことは大事なことだと思いました。
みんなで勉強して社会的に共通の了解にしておかないと、邪悪な人たちが力を持ち易くなる。
そして、以上の話と「人間なら誰でも犯す馬鹿な失敗の話」を区別して行く必要がある。
みんなで勉強して社会的に共通の了解にしておかないと、邪悪な人たちが力を持ち易くなる。
そして、以上の話と「人間なら誰でも犯す馬鹿な失敗の話」を区別して行く必要がある。
#統計 信頼区間は「データから棄却されないモデルのパラメータの範囲」だとみなせるという話は、売れ線の教科書では、
竹内啓『数理統計学』
竹村彰通『現代数理統計学』
久保川達也『現代数理統計学の基礎』
に書いてあります。
↓
竹内啓『数理統計学』
竹村彰通『現代数理統計学』
久保川達也『現代数理統計学の基礎』
に書いてあります。
↓
https://twitter.com/genkuroki/status/1487703677821685760
#統計 インターネット上には、信頼区間についておかしな解説が溢れています。日本語圏だけの問題ではなさそうですが、日本語圏では困った人が「95%信頼区間の95%は確率ではなく割合だ」という間違っていてかつピントの外れた意見を広めているので注意が必要です。
これが高等教育の現実で結構厳しい。
これが高等教育の現実で結構厳しい。
#統計 95%信頼区間の95%は統計モデル内で測った確率(の近似値)になっています。
統計モデル抜きではP値について理解できなくなることは、ASA声明でも強調されています。
↓
P値に関するASA声明翻訳版
biometrics.gr.jp/news/all/ASA.p…
P値もモデル内確率です。P値の理解抜きに信頼区間も理解できない。
統計モデル抜きではP値について理解できなくなることは、ASA声明でも強調されています。
↓
P値に関するASA声明翻訳版
biometrics.gr.jp/news/all/ASA.p…
P値もモデル内確率です。P値の理解抜きに信頼区間も理解できない。
#統計 P値については、ASA声明の翻訳者でもある佐藤俊哉さんの講義動画を視聴しておけば誤用を防げると思います。
↓
さらに
jstage.jst.go.jp/article/jjb/38…
ASA 声明と疫学研究におけるP値
佐藤俊哉
も参照。添付画像はその最後の段落。信頼区間もP値から得られる。
↓
さらに
jstage.jst.go.jp/article/jjb/38…
ASA 声明と疫学研究におけるP値
佐藤俊哉
も参照。添付画像はその最後の段落。信頼区間もP値から得られる。
https://twitter.com/genkuroki/status/1500549192766619648

#統計 1つ前のツイートの添付画像中に登場するRothmanさん達の有名な疫学の教科書でも、
95%信頼区間
=データから得られたP値が5%以上のモデルのパラメータの範囲
という定義が採用されています。実際にはさらにすすめて、パラメータ値にP値を対応させるP値函数の系統的利用をすすめている。
95%信頼区間
=データから得られたP値が5%以上のモデルのパラメータの範囲
という定義が採用されています。実際にはさらにすすめて、パラメータ値にP値を対応させるP値函数の系統的利用をすすめている。
https://twitter.com/genkuroki/status/1488110608696623104
#統計
jamanetwork.com/journals/jama/…
Use of Confidence Intervals in Interpreting Nonstatistically Significant Results
Hawkins and Samuels
2021
でも、データから有意水準5%で棄却されないモデルのパラメータ(例えば治療効果を意味するパラメータ)の範囲として、95%信頼区間を定義しています。
jamanetwork.com/journals/jama/…
Use of Confidence Intervals in Interpreting Nonstatistically Significant Results
Hawkins and Samuels
2021
でも、データから有意水準5%で棄却されないモデルのパラメータ(例えば治療効果を意味するパラメータ)の範囲として、95%信頼区間を定義しています。
https://twitter.com/genkuroki/status/1463766769059840004

#統計 P値から信頼区間は
95%信頼区間=P値が5%以上になるパラメータの範囲
で作れます。逆に、信頼係数1-αの信頼区間の実装のコードを見て、そこから逆にP値函数を作ることの実演を以下のリンク先で行いました(数学的には自明な構成)。
信頼区間とP値は表裏一体です。
95%信頼区間=P値が5%以上になるパラメータの範囲
で作れます。逆に、信頼係数1-αの信頼区間の実装のコードを見て、そこから逆にP値函数を作ることの実演を以下のリンク先で行いました(数学的には自明な構成)。
信頼区間とP値は表裏一体です。
https://twitter.com/genkuroki/status/1502560933553766406
#統計 P値と信頼区間の概念は表裏一体で、それらは
95%信頼区間=P値が5%以上になるモデルのパラメータの範囲
という関係になっている。
ゆえに、有意水準5%で「パラメータ値が0である」というモデル内仮説が棄却されることと、95%信頼区間に0が含まれないことは同値。
95%信頼区間=P値が5%以上になるモデルのパラメータの範囲
という関係になっている。
ゆえに、有意水準5%で「パラメータ値が0である」というモデル内仮説が棄却されることと、95%信頼区間に0が含まれないことは同値。
#統計 有意水準5%で「パラメータ値が0である」という仮説が棄却されることを「有意差がある」と言う場合には、95%信頼区間が0を含まないことと有意差があることは同値。
#統計 注意・警告:統計ソフトの多くはP値と信頼区間の表裏一体性に無頓着で、P値と信頼区間を別の考え方で実装しており、「パラメータ値は0である」という帰無仮説のP値が5%を切っていても、95%信頼区間に0が含まれている場合が生じる。P値と信頼区間の黒歴史が統計ソフトに詰まっている感じ。
#統計 再注意:統計学用語としての「有意差がない」は、差がないことの証拠が得られたことを意味しない。単に
そのデータだけからはよーわからん
ということでしかない。
検定論のイロハのイなので、この辺の判断で間違うと相当にまずい。
そのデータだけからはよーわからん
ということでしかない。
検定論のイロハのイなので、この辺の判断で間違うと相当にまずい。
#統計 しかもその「よーわからん」という判断は、必然性がない5%の有意水準(閾値)の設定をしていたり、現実への適用に注意を要する統計モデルを前提にしていたりと、そう単純な話にならない。
現実の意思決定ではその統計分析外の知識を総合的に用いる必要がある。
現実の意思決定ではその統計分析外の知識を総合的に用いる必要がある。
#統計 ついでに述べておくと、○○も効果を意味するモデルのパラメータ値の点推定の結果が負の値になっていても、「○○の効果は負である」と判断してはいけない。
推定の誤差が単に大きいせいで、本当は正の値なのに、推定結果は負の値になっただけの可能性がある。
普通は信頼区間の方を見る。
推定の誤差が単に大きいせいで、本当は正の値なのに、推定結果は負の値になっただけの可能性がある。
普通は信頼区間の方を見る。
#統計 普通は点推定の値だけで判断せずに信頼区間も見る。だから「○○の効果は負である」とおかしなことを述べてしまった人も信頼区間を見ているだろうと推測することは、かなり好意的な推測の仕方になる。「点推定の結果が負だから○○の効果は負である」のような判断の仕方はあまりにも論外すぎる。
#統計 例えば、サイコロを3回ふったら3回とも奇数の目が出たとする。このとき、奇数の目が出る確率の点推定の結果は100%になる。
その結果を見て「このサイコロは奇数の目だけが100%の確率で出るイカサマのサイコロだ!」などと叫ぶと、賭場では大変なことになってしまふだろう(笑)。
その結果を見て「このサイコロは奇数の目だけが100%の確率で出るイカサマのサイコロだ!」などと叫ぶと、賭場では大変なことになってしまふだろう(笑)。
#統計 細かい注意:1つ前のツイートでは点推定の方法として二項分布モデルでの最尤法を使った。点推定の方法には最尤法以外にも沢山の選択肢がある。多くの目的について最尤法は最適戦略にならないので、最尤法が至上であるかのような説明はミスリーディングで好ましくない。
#統計 少し脱線:「P値」の利用と「有意水準」(閾値)の利用の問題は明瞭に区別することが必要。後者のみに重大な問題がある。Rothmanさん達の有名な疫学の教科書では、有意水準という名の閾値を設定する二値的判断よりも、P値函数全体を使った総合的判断をすすめている。
#統計 続き:さらに厳密に細かいことを言うと、有意水準(もしくは信頼係数)という名の閾値を設定することと、現実での意思決定で安易に二値的判断をすることの区別も必要。後者には問題があるが、例えば、閾値の設定を単にグラフを見易くプロットするために使うことには大して問題はないと思う。
• • •
Missing some Tweet in this thread? You can try to
force a refresh