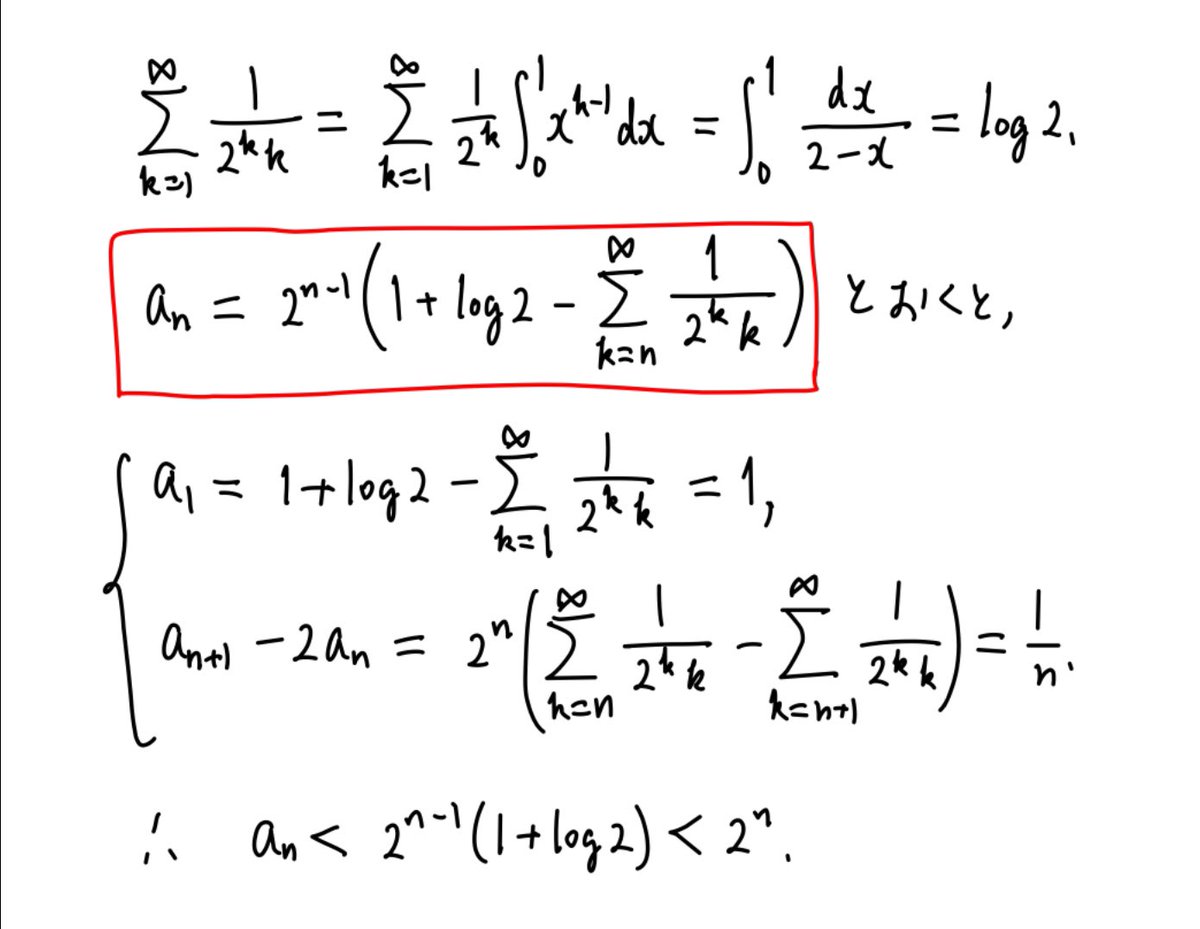#統計 n回中k回奇数の目が出たというデータが得られたとき、
pᵏ(1-p)ⁿ⁻ᵏ
を最大化するpの値k/nを奇数の目が出る確率の推定値とするのが、二項分布モデルでの最尤法に一致します。
その最尤法では、n回中k回奇数の目が出たら、奇数の目が出る確率はk/nだと推定される。非常に安易!続く
pᵏ(1-p)ⁿ⁻ᵏ
を最大化するpの値k/nを奇数の目が出る確率の推定値とするのが、二項分布モデルでの最尤法に一致します。
その最尤法では、n回中k回奇数の目が出たら、奇数の目が出る確率はk/nだと推定される。非常に安易!続く
https://twitter.com/genkuroki/status/1503630749223641088
#統計 データからの最も安易な推定法は、シンプルなモデルを使った最尤法に一致することが多いです。
上の例では、3回中3回とも奇数の目が出ると、奇数の目が出る確率は3/3=1だと推定される。
この推定結果は真実を意味するわけでも何でもなくて、特定の方法による単なる推定結果に過ぎません。
上の例では、3回中3回とも奇数の目が出ると、奇数の目が出る確率は3/3=1だと推定される。
この推定結果は真実を意味するわけでも何でもなくて、特定の方法による単なる推定結果に過ぎません。
#統計 最尤法については、入門的な教科書の多くに妙な説明がよく書いてあります。
東大出版会の『統計学入門』は最尤法に限らず統計学における基本概念についてことごとくミスリーディングな説明をしているのに、標準的教科書の地位を占めてしまった。
これが高等教育の現実で結構厳しい。
東大出版会の『統計学入門』は最尤法に限らず統計学における基本概念についてことごとくミスリーディングな説明をしているのに、標準的教科書の地位を占めてしまった。
これが高等教育の現実で結構厳しい。
https://twitter.com/genkuroki/status/1175814998347501574
#統計 【「現実の標本は確率最大のものが実現した」という仮定】(東大出版会『統計学入門』より)と本当に書いてある!
最尤法ではデータに最もフィットするパラメータ値を求めているだけです。そのようにして得た推定値は現実における真の値からかけ離れた値になっている可能性もある。
最尤法ではデータに最もフィットするパラメータ値を求めているだけです。そのようにして得た推定値は現実における真の値からかけ離れた値になっている可能性もある。

#統計 likelihoodで日常用語的には「もっともらしさ」という意味を持ちますが、数学的に正確に定義された概念について日常用語的な解釈を与えることはよく見る典型的にダメな考え方です。
尤度は「もっともらしさ」の指標ではありません。モデルのデータへの適合度の指標の1つに過ぎない。
尤度は「もっともらしさ」の指標ではありません。モデルのデータへの適合度の指標の1つに過ぎない。

#統計 Fisherさんが専門用語としてのlikelihoodという用語を正確に定義するまでには、「ひとり伝言ゲーム」をやっています(おそらく誤解を含んでいた)。専門用語は偉い人が使ったものがそのまま使われて続けることがあり、そういう悪しき事情と無関係に理解するようにしないとまずい。
https://twitter.com/genkuroki/status/1502039055747653633
#統計 いずれにせよ、「現実の標本は確率最大のものが実現した」のように仮定することは馬鹿げています。
最尤法では、統計モデル内で現実から得た標本と同じ数値が生成される確率密度が最大化されるパラメータ値を求めているだけ。その方法で求めたパラメータの推定値は的を外しているかもしれない。
最尤法では、統計モデル内で現実から得た標本と同じ数値が生成される確率密度が最大化されるパラメータ値を求めているだけ。その方法で求めたパラメータの推定値は的を外しているかもしれない。
#統計 最尤法の基礎は「データサイズが十分に大きいならば、データにフィットするようにモデルのパラメータ値を調節すれば、現実を近似する推定結果が得られるだろう」という考え方。
データからの推定値がどれだけ的を外すかに関する評価を行うと、本質的に信頼区間及びその一般化の話になる。
データからの推定値がどれだけ的を外すかに関する評価を行うと、本質的に信頼区間及びその一般化の話になる。
#統計 最尤法が有用であることの理解には、「現実の標本は確率最大のものが実現した」のような不合理な仮定は無用です。必要なのは、最尤法の数学的性質の理解です。
#統計 「現実の標本は確率最大のものが実現した」の解釈で重要なのは最尤法の文脈でその意味での「確率」は現実世界におけるなんらかの適切な意味での確率という意味ではなく、数学的フィクションである統計モデル内部で測った確率(尤度)という意味に過ぎないこと。
#統計 例えば、現実の標本は平均μ₀と分散σ₀²を持つ未知の正規分布から程遠い確率分布(のiid)に従って生成されている状況に、正規分布モデルを使った最尤法を適用したとしましょう。
すると、最尤法による平均μと分散σ²の推定量はそれぞれ標本平均と標本分散になります。続く
すると、最尤法による平均μと分散σ²の推定量はそれぞれ標本平均と標本分散になります。続く
#統計 以上の状況では、正規分布から程遠い母集団分布の標本に、正規分布モデルの最尤法を適用している。
はっきり間違ったモデルを適用しているのに、標本サイズ→∞の極限で、正しく母平均と母分散を推定できることを証明できます。
続く
はっきり間違ったモデルを適用しているのに、標本サイズ→∞の極限で、正しく母平均と母分散を推定できることを証明できます。
続く
#統計 平均と分散の推定では、正規分布モデルの最尤法が一応いつでも使える。
しかし、正規分布モデルよりも母集団分布をよく近似できてパラメータ数も少なめの統計モデルを使った方が、より小さな標本サイズでより正確な最尤推定が可能になる。
不合理な仮定ではなく、こういう数学の理解が大事。
しかし、正規分布モデルよりも母集団分布をよく近似できてパラメータ数も少なめの統計モデルを使った方が、より小さな標本サイズでより正確な最尤推定が可能になる。
不合理な仮定ではなく、こういう数学の理解が大事。
#統計 最尤法の数学的性質をある程度理解していれば、
* 母平均と母分散の推定にいつでも正規分布モデルを使えること
* 分野固有の知識を使ってより適切な統計モデルを設定できれば確率的に誤差をより小さくできること
などが分かります。こういう類の知識は明らかに役に立ちます。
* 母平均と母分散の推定にいつでも正規分布モデルを使えること
* 分野固有の知識を使ってより適切な統計モデルを設定できれば確率的に誤差をより小さくできること
などが分かります。こういう類の知識は明らかに役に立ちます。
#統計 専門知識を使って設定したモデルがある程度以上複雑になると、最尤法のコンピュータでの実装自体が結構面倒になったり、得意モデルに近い状況が生じて最尤法の使用が不適切になるリスクも増えます。そういう場合にはベイズ法やその変種の採用の検討も必要になる。
#統計 「異なる主義思想哲学に基く別の統計学がある」(それぞれ別のお墨付きが得られる)のような有害に見える言説に乗っかる必要は皆無で、普通に地道に理解するべきことを理解して道具を使って行けばよいと思います。
• • •
Missing some Tweet in this thread? You can try to
force a refresh