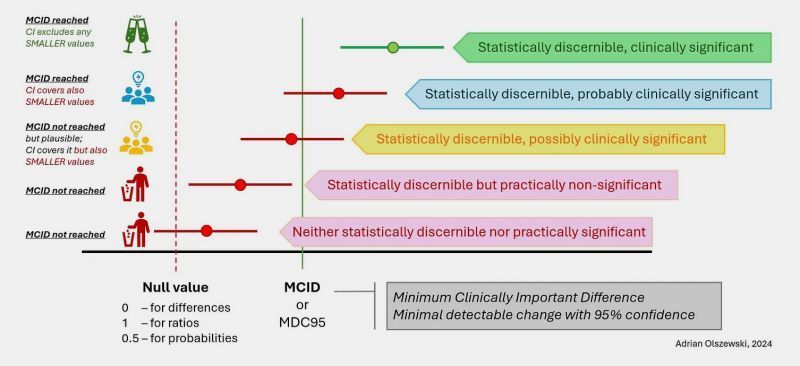
ERRORES QUE DAN MIEDO👻en #DataScience🎃
📊"Una imagen vale más que mil palabras", o que mil datos. Los gráficos cuentan la historia de los datos, nos ayudan a guiar, interpretar y comunicar😉
Cuidado con estos #HorrorStats
#HappyHalloween #Halloween #FelizDomingo #HalloweenEnds
📊"Una imagen vale más que mil palabras", o que mil datos. Los gráficos cuentan la historia de los datos, nos ayudan a guiar, interpretar y comunicar😉
Cuidado con estos #HorrorStats
#HappyHalloween #Halloween #FelizDomingo #HalloweenEnds

🚫1. Elegir el gráfico incorrecto💀
Cada gráfico tiene sus propios casos de uso. ¿Tiene sentido representar el crédito € de una tarjeta con un gráfico de sectores? 🤌
#HorrorStats #HappyHalloween~ #trickortreat #DataScience #dataviz #DataScience #data
¿Qué gráfico utilizar?👇
Cada gráfico tiene sus propios casos de uso. ¿Tiene sentido representar el crédito € de una tarjeta con un gráfico de sectores? 🤌
#HorrorStats #HappyHalloween~ #trickortreat #DataScience #dataviz #DataScience #data
¿Qué gráfico utilizar?👇

🚫2. Manipular los ejes del gráfico💀
👉Distorsionar la escala, truncarla u omitir líneas de base es un error, intencionado o no.🤦🏻♀️
¿Quieres más ejemplos?👇
#HorrorStats #HappyHalloween~ #trickortreat #DataScience #dataviz #RStats #Python #DataVisualization #Stats #Analytics
👉Distorsionar la escala, truncarla u omitir líneas de base es un error, intencionado o no.🤦🏻♀️
¿Quieres más ejemplos?👇
#HorrorStats #HappyHalloween~ #trickortreat #DataScience #dataviz #RStats #Python #DataVisualization #Stats #Analytics

🚫3. Eliminar datos atípicos del gráfico.😱
👨💻Si un gráfico parece que recorta algunos de los datos, no es confiable. Los valores atípicos (outliers) también deben representarse.👻
¿Qué son los "outliers"? 👇maximaformacion.es/blog-dat/como-…
#HorrorStats #HappyHalloween #DataScience #ML
👨💻Si un gráfico parece que recorta algunos de los datos, no es confiable. Los valores atípicos (outliers) también deben representarse.👻
¿Qué son los "outliers"? 👇maximaformacion.es/blog-dat/como-…
#HorrorStats #HappyHalloween #DataScience #ML

🚫4. No evaluar los supuestos del modelo y su ajuste mediante gráficos.🎃
El Cuarteto de Anscombe: 4 conjuntos de datos con misma media, var, correlación, línea de regresión, etc. pero ¿En cuál tiene sentido ajustar una regresión lineal?😱👇
maximaformacion.es/blog-dat/error…
#HorrorStats
El Cuarteto de Anscombe: 4 conjuntos de datos con misma media, var, correlación, línea de regresión, etc. pero ¿En cuál tiene sentido ajustar una regresión lineal?😱👇
maximaformacion.es/blog-dat/error…
#HorrorStats

🚫5. Utilizar datos incorrectos🤦🏻♀️
🗑"Basura entra, basura sale". En el contexto de los gráficos esto significa que los datos incorrectos darán lugar a visualizaciones incorrectas.💀
#HorrorStats #HappyHalloween~ #dataviz #FelizDomingoParaTodos #DataScience #HalloweenEnds #ML
🗑"Basura entra, basura sale". En el contexto de los gráficos esto significa que los datos incorrectos darán lugar a visualizaciones incorrectas.💀
#HorrorStats #HappyHalloween~ #dataviz #FelizDomingoParaTodos #DataScience #HalloweenEnds #ML

¿Conoces algún ejemplo famoso con errores en sus gráficos? Te leo😉
🚀Si te quedaste con ganas de más descarga nuestro recurso gratuito ¡IMPRESIONA CON TUS GRÁFICOS! maximaformacion.es/wp-content/upl…
Mañana otra serie ESCALOFRIANTE QUE DA MIEDO en #DataScience #HorrorStats #HappyHalloween
🚀Si te quedaste con ganas de más descarga nuestro recurso gratuito ¡IMPRESIONA CON TUS GRÁFICOS! maximaformacion.es/wp-content/upl…
Mañana otra serie ESCALOFRIANTE QUE DA MIEDO en #DataScience #HorrorStats #HappyHalloween
• • •
Missing some Tweet in this thread? You can try to
force a refresh