
✅Linear Neural Networks for Regression and Classification explained in simple terms and how to use it (with code).
A quick thread 🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #deeplearning
Pic credits : Joshua
A quick thread 🧵👇🏻
#Python #DataScience #MachineLearning #DataScientist #Programming #Coding #100DaysofCode #hubofml #deeplearning
Pic credits : Joshua
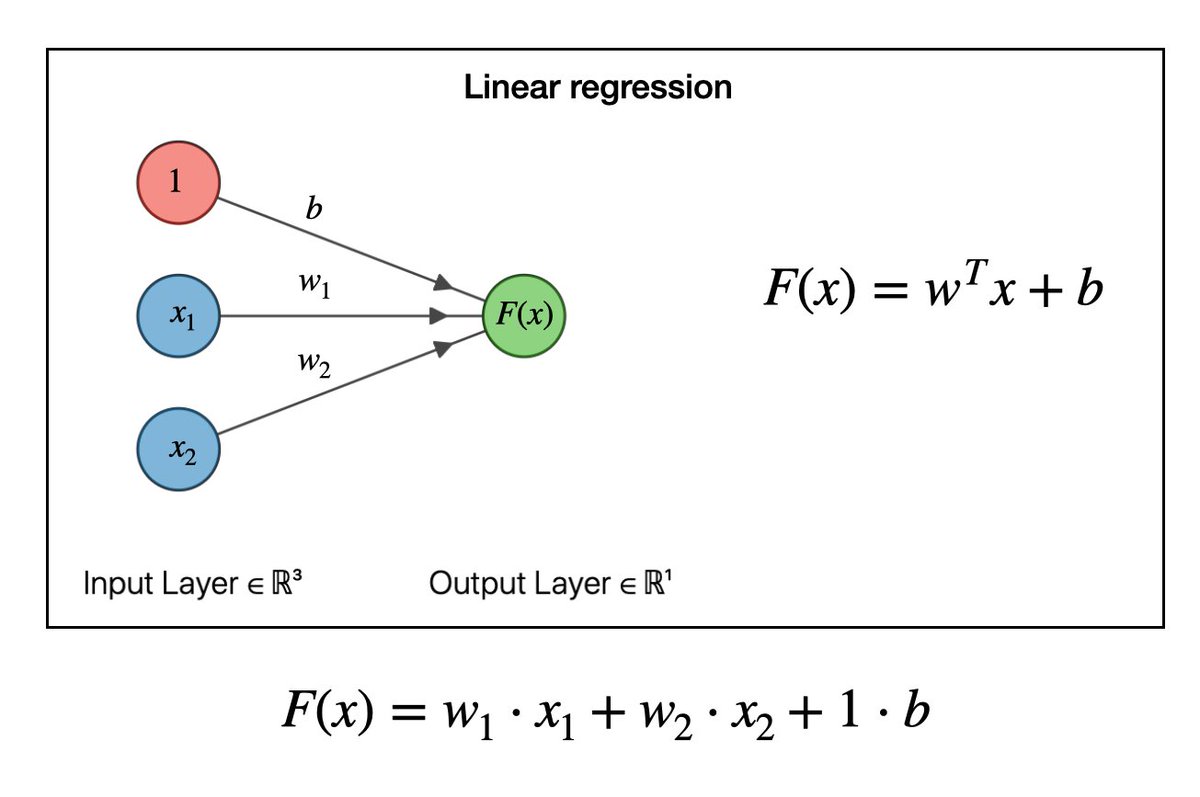
1/ Imagine you have a box with a lot of buttons on it, and each button can give you a different answer. You also have a big list of questions that you want to ask, like "What's the weather like today?" or "Is this a cat or a dog?".
2/ Now, instead of asking just one button at a time, you can connect all the buttons together with wires. When you ask a question, it goes through the wires and each button can help decide the answer a little bit.
3/ Linear neural networks are like those wires and buttons. The wires connect different buttons, and each button has a number associated with it. When you ask a question, answer goes through all buttons, and each button multiplies answer by its number and passes it to next button
4/ In regression, the goal is to find the best combination of numbers for the buttons so that the final answer is as close as possible to the right answer. It's like finding the best set of numbers that gives you the right temperature when you ask about the weather.
5/ In classification, the goal is a bit different. Instead of just getting a number, you want to know if something belongs to a certain group. For example, if you show a picture of a cat or a dog, you want to know if it's a cat or a dog.
6/ So, linear neural networks are like a bunch of connected buttons that help us find the right answer to different questions, whether it's finding the right temperature or deciding if something is a cat or a dog.
7/ Linear neural networks for regression and classification are ML models that are used to predict numerical values (regression) or classify data into different categories (classification). Linear regression, which involves finding best line that fits a set of data points.
8/ In a linear neural network, there are input features (like temperature, age, or size) that are multiplied by weights (numbers) and then summed up. This sum goes through an activation function, which helps determine the final output.
9/ For regression, the output is a numerical value, while for classification, the output represents the predicted class or category. Linear neural networks are relatively simple models compared to more complex ones like deep neural networks.
10/ Implement Linear Regression -

11/ Implement Generalization in Linear Regression -
To demonstrate concept of generalization in linear regression, we can split dataset into training and testing sets. We will train linear regression model on training set and then evaluate its performance on unseen testing set.
To demonstrate concept of generalization in linear regression, we can split dataset into training and testing sets. We will train linear regression model on training set and then evaluate its performance on unseen testing set.

12/ Implement Weight Decay in Linear Regression - Weight decay, also known as L2 regularization, is a technique used to prevent overfitting in ML models, including linear regression. It adds a penalty term to loss function that encourages model to have smaller weights.

13/ Generate synthetic regression data - Implementation

14/ Implement Softmax Regression - Softmax regression, also known as multinomial logistic regression, is a classification algorithm that extends logistic regression to handle multi-class classification problems.

15/ Implement Generalization in Classification -

16/ Efficiency: Linear neural networks are computationally efficient and can handle large datasets and high-dimensional input features with relative ease. They can be trained quickly and used for real-time predictions.
17/ Baseline model: Linear neural networks serve as a good starting point for modeling. They provide a baseline performance against which more complex models can be compared. If a linear model performs well, there might not be a need for a more complex model.
18/ Feature importance: Linear neural networks can help identify the most influential features in predicting the output. By examining the weights assigned to each feature, you can understand which factors have a stronger impact on the prediction.
19/ Generalization: Linear neural networks can generalize well to unseen data if the input features have a linear relationship with the output. This means they can make accurate predictions even for new examples that were not part of the training data.
20/ Interpretable results: Because linear neural networks are based on linear regression, the weights assigned to each feature can provide insights into their importance in predicting the output. This makes it easier to interpret the model's behavior.
21/ Hyperparameter optimization is the process of finding best set of hyperparameters for a machine learning model. Hyperparameters are parameters that are not learned directly from the training data but are set before training and affect the behavior of the model.
22/The goal of hyperparameter optimization is to search through a specified set of hyperparameters and their possible values to find the combination that maximizes the performance of the model on unseen data.
23/ The performance metric used for optimization can vary depending on the problem, such as accuracy, precision, recall, or F1 score for classification tasks, or mean squared error (MSE) for regression tasks.
• • •
Missing some Tweet in this thread? You can try to
force a refresh










