Thread Reader helps you read and share Twitter threads easily!
I'm @ThreadReaderApp a Twitter bot here to help you read threads more easily. To trigger me, you just have to reply to (or quote) any tweet of the thread you want to unroll and mention me with the "unroll" keyword and I'll send you a link back on Twitter 😀
— Thread Reader App (@threadreaderapp) November 25, 2017
X thread is series of posts by the same author connected with a line!
From any post in the thread, mention us with a keyword "unroll"
@threadreaderapp unroll
Follow @ThreadReaderApp to mention us easily!
Practice here first or read more on our help page!
Recent

Different people have asked my advice after a vulnerable boy got lost and died despite massive search effort. I'm an engineer with telecom background and experience with mobile devices.
Here are my recommendations. I have no commercial interest in any of them.
@paul_dunphy
Here are my recommendations. I have no commercial interest in any of them.
@paul_dunphy




While most of my experience is Apple AirTag, I also recommend a product that is BOTH Apple Find My® and Google Find My Device (Android) compatible.
I cover situations with informed consent or protection of vulnerable people, from children to seniors.
apple.com/ca/airtag/
I cover situations with informed consent or protection of vulnerable people, from children to seniors.
apple.com/ca/airtag/
My usual recommendation is @LOGiiX $10 Armour Tag, which looks like a sports watch, and sits nice and flat against a wrist band, dog collar, backpack strap, or wheelchair sling strap.
Great for consenting older kids, seniors who wander, hidden in a car.
logiix.ca/products/armou…
Great for consenting older kids, seniors who wander, hidden in a car.
logiix.ca/products/armou…

We all knew he was lying about the Reflecting Pool. The problem is that he lies so often that it’s almost impossible to keep up.
So I asked AI to compile claims from just the past twenty-four months and then checked them against official data, contemporaneous reporting and independent fact-checks.
Here is a partial list of 86 lies:
1. He promised to bring prices down “starting on Day One.” Grocery prices remained high and continued rising.
2. After winning, he admitted that prices are very hard to bring down once they have gone up.
3. He said egg prices had fallen 93 percent. They had not fallen remotely close to 93 percent.
4. He said he inherited the highest inflation in American history. He inherited an annual inflation rate of 2.9 percent.
5. When corrected, he changed the claim to the worst inflation in 49 years. That was also false. Annual inflation reached 23.7 percent in 1920.
6. He said there was virtually no inflation during his first term. Consumer prices rose approximately 8 percent.
7. He repeatedly claimed he had already brought inflation down, including during periods when the annual inflation rate was higher than the 2.9 percent reported shortly before he took office.
8. He told Congress inflation was “plummeting.” Prices were still rising overall, including major household expenses such as housing, electricity and medical care.
9. He claimed to have secured $18 trillion in new investment.
10. He then raised the figure to $19.2 trillion.
11. Even the White House’s own tracker listed far less, and its total included multiyear pledges, purchasing agreements, previously announced projects and commitments that might never become actual US investment.
12. He said America was building more factories than ever.
13. He said factory construction was rising.
14. He said the country had achieved its highest growth ever. Manufacturing employment declined, factory-construction claims depended on cherry-picked categories, and economic growth was nowhere near a historical record.
15. He called the country he inherited a dead country. The US economy grew 2.8 percent in 2024, faster than every other major wealthy economy except Spain.
16. He says foreign countries pay his tariffs. American importers pay them and frequently pass the cost on to American consumers.
17. He said the evidence overwhelmingly showed consumers did not pay his tariffs. Economic studies found that American consumers and businesses absorbed nearly all their cost.
18. He said tariff revenue came with “no inflation.” Prices continued rising, and economic research found that the tariffs themselves increased costs for American consumers and businesses.
19. He repeatedly said drug prices were down 70, 80 or 90 percent. No broad measure of prescription-drug prices showed anything close to those reductions.
20. He said Medicaid was “left the same.” The Congressional Budget Office estimated that the legislation would reduce federal Medicaid spending by roughly $930 billion over ten years.
21. He said Americans were “not going to feel any of it.” The Congressional Budget Office projected that the legislation would leave approximately 11.8 million more people uninsured.
22. He said the Medicaid changes touched only waste, fraud and abuse. Independent analyses found that the legislation reduced coverage and federal spending far beyond fraudulent claims.
23. He said he had eliminated taxes on Social Security. The law created a temporary deduction, unavailable to many beneficiaries, that expires after 2028. It did not abolish taxation of Social Security benefits.
24. He said taxes would rise 68 percent without his bill. No credible independent estimate came close to supporting that figure.
25. He then declared, “I’ve kept all my promises and much more.”
26. He publicly promised at least 53 times to end the Ukraine war within 24 hours, or even before taking office.
Continued in replies…
So I asked AI to compile claims from just the past twenty-four months and then checked them against official data, contemporaneous reporting and independent fact-checks.
Here is a partial list of 86 lies:
1. He promised to bring prices down “starting on Day One.” Grocery prices remained high and continued rising.
2. After winning, he admitted that prices are very hard to bring down once they have gone up.
3. He said egg prices had fallen 93 percent. They had not fallen remotely close to 93 percent.
4. He said he inherited the highest inflation in American history. He inherited an annual inflation rate of 2.9 percent.
5. When corrected, he changed the claim to the worst inflation in 49 years. That was also false. Annual inflation reached 23.7 percent in 1920.
6. He said there was virtually no inflation during his first term. Consumer prices rose approximately 8 percent.
7. He repeatedly claimed he had already brought inflation down, including during periods when the annual inflation rate was higher than the 2.9 percent reported shortly before he took office.
8. He told Congress inflation was “plummeting.” Prices were still rising overall, including major household expenses such as housing, electricity and medical care.
9. He claimed to have secured $18 trillion in new investment.
10. He then raised the figure to $19.2 trillion.
11. Even the White House’s own tracker listed far less, and its total included multiyear pledges, purchasing agreements, previously announced projects and commitments that might never become actual US investment.
12. He said America was building more factories than ever.
13. He said factory construction was rising.
14. He said the country had achieved its highest growth ever. Manufacturing employment declined, factory-construction claims depended on cherry-picked categories, and economic growth was nowhere near a historical record.
15. He called the country he inherited a dead country. The US economy grew 2.8 percent in 2024, faster than every other major wealthy economy except Spain.
16. He says foreign countries pay his tariffs. American importers pay them and frequently pass the cost on to American consumers.
17. He said the evidence overwhelmingly showed consumers did not pay his tariffs. Economic studies found that American consumers and businesses absorbed nearly all their cost.
18. He said tariff revenue came with “no inflation.” Prices continued rising, and economic research found that the tariffs themselves increased costs for American consumers and businesses.
19. He repeatedly said drug prices were down 70, 80 or 90 percent. No broad measure of prescription-drug prices showed anything close to those reductions.
20. He said Medicaid was “left the same.” The Congressional Budget Office estimated that the legislation would reduce federal Medicaid spending by roughly $930 billion over ten years.
21. He said Americans were “not going to feel any of it.” The Congressional Budget Office projected that the legislation would leave approximately 11.8 million more people uninsured.
22. He said the Medicaid changes touched only waste, fraud and abuse. Independent analyses found that the legislation reduced coverage and federal spending far beyond fraudulent claims.
23. He said he had eliminated taxes on Social Security. The law created a temporary deduction, unavailable to many beneficiaries, that expires after 2028. It did not abolish taxation of Social Security benefits.
24. He said taxes would rise 68 percent without his bill. No credible independent estimate came close to supporting that figure.
25. He then declared, “I’ve kept all my promises and much more.”
26. He publicly promised at least 53 times to end the Ukraine war within 24 hours, or even before taking office.
Continued in replies…
27. After failing to do so, he said the promise had been sarcastic or made in jest. Fifty-three times of sarcasm.
28. He claimed Ukraine started the war. Russia invaded Ukraine.
29. He used inflated and inconsistent figures to claim America had contributed vastly more to Ukraine than Europe. On total aid allocated by European countries and European Union institutions collectively, Europe had contributed more.
30. He said Russia failed to take Kyiv because its forces avoided the highways. The article he cited described Russian forces invading along the highways.
31. He repeatedly said Biden gave Ukraine $350 billion. That conflated the full cost of Ukraine-related appropriations with money and equipment actually delivered to Ukraine.
32. Official figures for direct military assistance were a fraction of his claim.
33. After repeatedly saying the earlier strikes had “obliterated” Iran’s nuclear program, he later took the country to war over the continuing threat posed by that same program.
34. An early assessment by the Pentagon’s Defense Intelligence Agency concluded that the strikes had set the program back rather than destroyed it.
35. He presented the war as necessary to stop an impending Iranian attack. Pentagon officials told Congress they had not identified evidence that Iran was preparing an imminent attack on the United States.
36. He said half the world might have been eradicated without his intervention. His own intelligence director had testified that Iran had not made a decision to build a nuclear weapon.
37. Nine days into the war, he declared, “We’ve already won.” The fighting continued.
38. On May 1, he formally notified Congress that US hostilities with Iran had “terminated,” even though the broader military confrontation and US operations continued.
39. He said the war was going “swimmingly” as it ground on.
40. He repeatedly declared total victory and then issued new threats against Iran, sometimes contradicting himself within a single day.
41. On June 1, he said he did not care whether negotiations were over. The same day, he posted that talks were continuing at a rapid pace.
42. His administration insisted that continuing military operations did not constitute legally relevant “hostilities,” allowing it to argue that the War Powers deadline no longer applied.
43. He said Iran’s leaders were all gone and “everything” was gone. In the same meeting, he acknowledged that Iran still possessed missiles and drones.
44. He repeatedly claimed Iran’s military capabilities had been entirely eradicated. They had not.
45. He now says Iran has been denuclearized, even though he made essentially the same “obliterated” claim after the earlier strikes and later said Iran remained dangerous enough to justify another war.
28. He claimed Ukraine started the war. Russia invaded Ukraine.
29. He used inflated and inconsistent figures to claim America had contributed vastly more to Ukraine than Europe. On total aid allocated by European countries and European Union institutions collectively, Europe had contributed more.
30. He said Russia failed to take Kyiv because its forces avoided the highways. The article he cited described Russian forces invading along the highways.
31. He repeatedly said Biden gave Ukraine $350 billion. That conflated the full cost of Ukraine-related appropriations with money and equipment actually delivered to Ukraine.
32. Official figures for direct military assistance were a fraction of his claim.
33. After repeatedly saying the earlier strikes had “obliterated” Iran’s nuclear program, he later took the country to war over the continuing threat posed by that same program.
34. An early assessment by the Pentagon’s Defense Intelligence Agency concluded that the strikes had set the program back rather than destroyed it.
35. He presented the war as necessary to stop an impending Iranian attack. Pentagon officials told Congress they had not identified evidence that Iran was preparing an imminent attack on the United States.
36. He said half the world might have been eradicated without his intervention. His own intelligence director had testified that Iran had not made a decision to build a nuclear weapon.
37. Nine days into the war, he declared, “We’ve already won.” The fighting continued.
38. On May 1, he formally notified Congress that US hostilities with Iran had “terminated,” even though the broader military confrontation and US operations continued.
39. He said the war was going “swimmingly” as it ground on.
40. He repeatedly declared total victory and then issued new threats against Iran, sometimes contradicting himself within a single day.
41. On June 1, he said he did not care whether negotiations were over. The same day, he posted that talks were continuing at a rapid pace.
42. His administration insisted that continuing military operations did not constitute legally relevant “hostilities,” allowing it to argue that the War Powers deadline no longer applied.
43. He said Iran’s leaders were all gone and “everything” was gone. In the same meeting, he acknowledged that Iran still possessed missiles and drones.
44. He repeatedly claimed Iran’s military capabilities had been entirely eradicated. They had not.
45. He now says Iran has been denuclearized, even though he made essentially the same “obliterated” claim after the earlier strikes and later said Iran remained dangerous enough to justify another war.
46. He claimed a former president had privately endorsed his handling of the Iran war. Representatives for the four living former presidents said none had held such a conversation with him.
47. He repeated his debunked claim that his 2000 book warned about Osama bin Laden. The book contains no such warning.
48. He said news organizations should be prosecuted for treason for supposedly circulating fake aircraft-carrier footage, while providing no identified example of a news organization fabricating such a video.
49. He says he ended eight wars. His list includes disputes that were not wars, conflicts that had not actually ended and ceasefires whose participants dispute his role.
50. He repeatedly increased the number from six to seven to eight without providing a consistent list or standard for what counts as a war he ended.
51. He says he stopped the conflict between India and Pakistan. India says the ceasefire was reached bilaterally and that he was not part of it.
52. He counted Congo and Rwanda among the wars he ended. Fresh fighting broke out weeks later.
53. He counted Kosovo and Serbia. Experts noted that the two countries were not at war.
54. He declared the war in Gaza over. The next phase of the ceasefire did not begin, the parties remained divided over its terms and both sides threatened renewed fighting.
55. He said Greenland was surrounded by Chinese and Russian ships. Officials and regional experts said there was no such ring of ships.
56. He described Greenland as a piece of ice that was difficult to call land. It is the world’s largest island and home to approximately 56,000 people.
57. He said there was no sign of Denmark in Greenland. Denmark has governed Greenland for centuries.
58. He said America paid 100 percent of NATO. The United States accounted for roughly two-thirds of total allied defense spending but only about one-sixth of NATO’s jointly funded budgets.
59. He said the United States never got anything from NATO. NATO has invoked its mutual-defense clause once in its history. It did so for the United States after September 11.
60. Denmark alone lost more than 40 service members fighting alongside the United States in Afghanistan.
61. He said most NATO countries were not paying anything before he became president. Ev member had national defense spending, even when many fell below the alliance’s 2 percent target.
62. He said Barack Obama had been “caught” committing treason. John Durham’s investigation did not charge Obama or establish the alleged conspiracy.
63. Durham charged three other people, produced one guilty plea involving an altered email, and ended with two acquittals.
64. He dismissed evidence pointing toward Iranian-linked hackers and blamed Tim Walz and Minnesota’s supposed incompetence for cyberattacks that struck water systems in several states. He offered no evidence that Walz caused them.
47. He repeated his debunked claim that his 2000 book warned about Osama bin Laden. The book contains no such warning.
48. He said news organizations should be prosecuted for treason for supposedly circulating fake aircraft-carrier footage, while providing no identified example of a news organization fabricating such a video.
49. He says he ended eight wars. His list includes disputes that were not wars, conflicts that had not actually ended and ceasefires whose participants dispute his role.
50. He repeatedly increased the number from six to seven to eight without providing a consistent list or standard for what counts as a war he ended.
51. He says he stopped the conflict between India and Pakistan. India says the ceasefire was reached bilaterally and that he was not part of it.
52. He counted Congo and Rwanda among the wars he ended. Fresh fighting broke out weeks later.
53. He counted Kosovo and Serbia. Experts noted that the two countries were not at war.
54. He declared the war in Gaza over. The next phase of the ceasefire did not begin, the parties remained divided over its terms and both sides threatened renewed fighting.
55. He said Greenland was surrounded by Chinese and Russian ships. Officials and regional experts said there was no such ring of ships.
56. He described Greenland as a piece of ice that was difficult to call land. It is the world’s largest island and home to approximately 56,000 people.
57. He said there was no sign of Denmark in Greenland. Denmark has governed Greenland for centuries.
58. He said America paid 100 percent of NATO. The United States accounted for roughly two-thirds of total allied defense spending but only about one-sixth of NATO’s jointly funded budgets.
59. He said the United States never got anything from NATO. NATO has invoked its mutual-defense clause once in its history. It did so for the United States after September 11.
60. Denmark alone lost more than 40 service members fighting alongside the United States in Afghanistan.
61. He said most NATO countries were not paying anything before he became president. Ev member had national defense spending, even when many fell below the alliance’s 2 percent target.
62. He said Barack Obama had been “caught” committing treason. John Durham’s investigation did not charge Obama or establish the alleged conspiracy.
63. Durham charged three other people, produced one guilty plea involving an altered email, and ended with two acquittals.
64. He dismissed evidence pointing toward Iranian-linked hackers and blamed Tim Walz and Minnesota’s supposed incompetence for cyberattacks that struck water systems in several states. He offered no evidence that Walz caused them.

Last night, _seattlestorm co-owner Celeste Keaton cursed out two teen girls for wearing _xx_xyathletics shirts, calling them "f*cking insane." One of them was left in tears. [29JUL26]
I tried to get security involved and was told I should email the front office.
- Brandi Kruse - unDivided with Brandi Kruse
“The most formidable weapon against errors of every kind is reason.”
-
- Brandi Kruse - unDivided with Brandi Kruse
“The most formidable weapon against errors of every kind is reason.”
-

The way Seattle Storm owner Celeste Keaton treated the two young female Sophie Cunningham supporters was despicable…
The WNBA should reprimand her.
- Jon Root ⛪️ CHRIST 🏈 SPORTZ 🇺🇸 CULTURE
The WNBA should reprimand her.
- Jon Root ⛪️ CHRIST 🏈 SPORTZ 🇺🇸 CULTURE

1/10
I'm a cardiologist. Your scan came back and there's plaque in your arteries.
A calcium score of 200. Carotid plaque on ultrasound. Soft plaque on CT angiogram.
You're scared. Here's the first thing I tell every patient:
Plaque can stabilize. And it can regress. We have imaging proof.
This is not a life sentence — but what happens next depends almost entirely on what you do in the next 12 months.
Here is the exact protocol. Save this.
I'm a cardiologist. Your scan came back and there's plaque in your arteries.
A calcium score of 200. Carotid plaque on ultrasound. Soft plaque on CT angiogram.
You're scared. Here's the first thing I tell every patient:
Plaque can stabilize. And it can regress. We have imaging proof.
This is not a life sentence — but what happens next depends almost entirely on what you do in the next 12 months.
Here is the exact protocol. Save this.
2/10 — GET THE RIGHT NUMBERS
Your standard cholesterol panel is not enough. Demand these:
ApoB — the true count of atherogenic particles. This is the number that matters, not LDL alone. One analysis found 54% of patients had dangerous levels that standard LDL testing missed entirely.
Lp(a) — once in your lifetime. It's genetic and never changes. One in five people carry dangerous levels. It triples heart attack risk. Most people have never been tested.
hs-CRP — inflammation. You can have perfect cholesterol and arteries actively preparing to rupture.
Fasting insulin + HbA1c — insulin resistance drives plaque a decade before diabetes shows up.
Also: homocysteine, thyroid panel, and a full lipid fractionation.
You cannot fix what you never measured.
Your standard cholesterol panel is not enough. Demand these:
ApoB — the true count of atherogenic particles. This is the number that matters, not LDL alone. One analysis found 54% of patients had dangerous levels that standard LDL testing missed entirely.
Lp(a) — once in your lifetime. It's genetic and never changes. One in five people carry dangerous levels. It triples heart attack risk. Most people have never been tested.
hs-CRP — inflammation. You can have perfect cholesterol and arteries actively preparing to rupture.
Fasting insulin + HbA1c — insulin resistance drives plaque a decade before diabetes shows up.
Also: homocysteine, thyroid panel, and a full lipid fractionation.
You cannot fix what you never measured.
3/10 — DRIVE APOB DOWN. HARD.
This is non-negotiable, and it's where regression actually happens.
Plaque regression in imaging trials occurs at aggressive lowering — generally LDL under 70, and in established disease many of us target 50-55. ApoB ideally under 60.
Statins are first-line with the deepest outcome evidence. And here's what surprises people: statins can increase the calcification of existing plaque. That's good. Calcified plaque is scarred, stable, quiet plaque. Soft, lipid-rich plaque is what ruptures and kills you.
If statins cause muscle pain, CoQ10 depletion is real — supplement it, or switch agents.
This is non-negotiable, and it's where regression actually happens.
Plaque regression in imaging trials occurs at aggressive lowering — generally LDL under 70, and in established disease many of us target 50-55. ApoB ideally under 60.
Statins are first-line with the deepest outcome evidence. And here's what surprises people: statins can increase the calcification of existing plaque. That's good. Calcified plaque is scarred, stable, quiet plaque. Soft, lipid-rich plaque is what ruptures and kills you.
If statins cause muscle pain, CoQ10 depletion is real — supplement it, or switch agents.

EXCLUSIVE
Nigel Farage struck secret deal for return as Reform leader months before election — challenging claim he wasn't involved in politics so didn't need to report gifts.
In May 24 he showed deal to treasurer, who tonight acknowledged its existence thetimes.com/uk/politics/ar…
Nigel Farage struck secret deal for return as Reform leader months before election — challenging claim he wasn't involved in politics so didn't need to report gifts.
In May 24 he showed deal to treasurer, who tonight acknowledged its existence thetimes.com/uk/politics/ar…
The deal ensured that, if Farage returned as leader, he would repay up to £1m loaned to party by Richard Tice, its then leader. It included schedule of payments
Reform sources say deal was for if, not when, Farage returned. They insist it had still been plan to spend time in US
Reform sources say deal was for if, not when, Farage returned. They insist it had still been plan to spend time in US
George Cottrell was involved in the deal, supervising the process in March and April 2024.
He was with Farage in mid-May when he presented its contents to Mehrash A'zami, the party's treasurer, in an office space near Buckingham Palace.
He was with Farage in mid-May when he presented its contents to Mehrash A'zami, the party's treasurer, in an office space near Buckingham Palace.

matt furie lore 🧵

on weds july 29, @Matt_Furie follows hoodrat on x
we receive a dm hours later
we receive a dm hours later

conversation was spaced apart quite a bit, replying to us multiple hrs later with what seemed like genuine responses.
A few key things:
- no immediate wallet was sent
- wasn't in a rush with getting compensation etc
- follow and comment was live for an extended period of time.
- concern about the nft mint was raised (sparking genuine belief that matt was not hacked)
A few key things:
- no immediate wallet was sent
- wasn't in a rush with getting compensation etc
- follow and comment was live for an extended period of time.
- concern about the nft mint was raised (sparking genuine belief that matt was not hacked)


🧵It’s almost that time: Flu shots will likely be rolling out later this month.
Flu might be more “simple” than SARS2, but it’s important to stay vigilant and informed.
I made a short guide on what you need to know for flu season: vaccine choice, tests, & treatments⬇️ (1/11)
Flu might be more “simple” than SARS2, but it’s important to stay vigilant and informed.
I made a short guide on what you need to know for flu season: vaccine choice, tests, & treatments⬇️ (1/11)

💉Vaccine choice, in short:
I recommend Flublok for most people who have access. It’s only indicated for ages 9+, making Flucelvax my choice for <9.
However, there are many platforms you may be interested in trying. Detailed comparisons of all 6 vaccine “types” below⬇️ (2/11)
I recommend Flublok for most people who have access. It’s only indicated for ages 9+, making Flucelvax my choice for <9.
However, there are many platforms you may be interested in trying. Detailed comparisons of all 6 vaccine “types” below⬇️ (2/11)

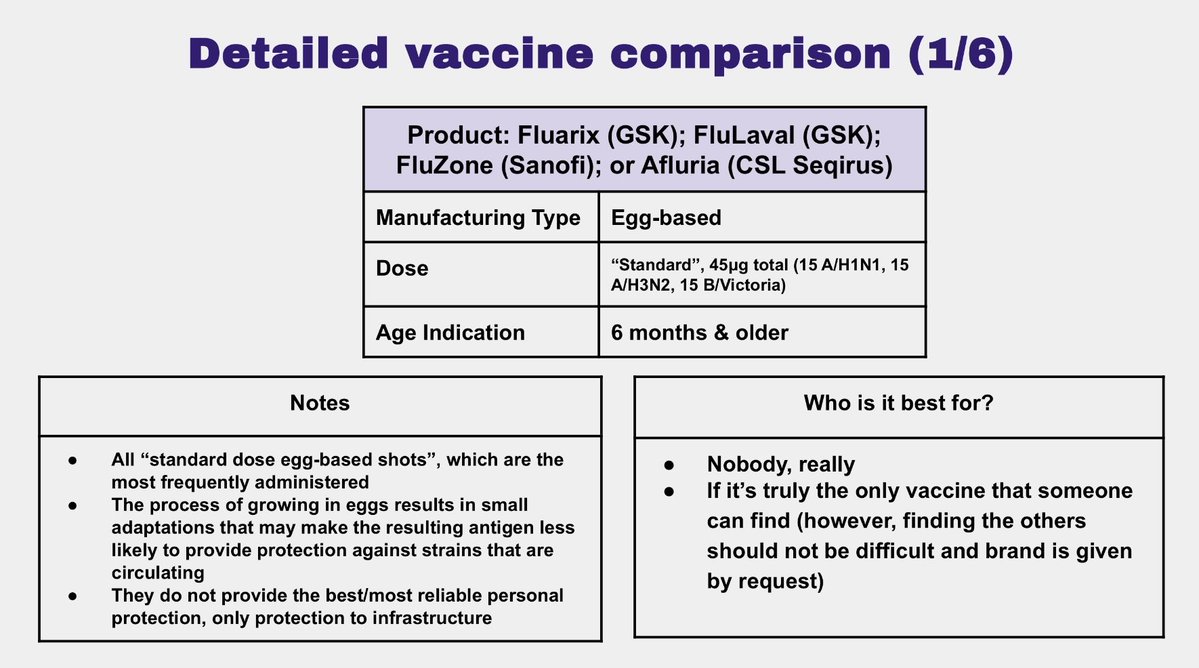
❌Standard dose egg-based vaccines:
These are the “standard”, and most frequently used, but they don’t offer much for informed patients. Growing the antigen in eggs is problematic because it results in small adaptations that drift the product from circulating strains. (3/11)
These are the “standard”, and most frequently used, but they don’t offer much for informed patients. Growing the antigen in eggs is problematic because it results in small adaptations that drift the product from circulating strains. (3/11)

1/6 When roughly 60,000 people suddenly rushed across the heavily guarded borders of Ceuta, Spain's enclave in North Africa, mainstream observers called it a humanitarian accident.
They were wrong. It was a calculated geopolitical power play--of course the Jews get blamed. 🧵👇
They were wrong. It was a calculated geopolitical power play--of course the Jews get blamed. 🧵👇

2/6 The real culprit? Morocco. When Spain got too friendly with Morocco's rival, Algeria, Rabat flipped a switch on its border enforcement. Tens of thousands crossed into Ceuta in under 48 hours to remind Madrid who controls the border tap.
Classic statecraft, not an accident.
Classic statecraft, not an accident.
3/6 But instead of confronting this North African realpolitik, a loud group of European politicians and digital shock-jocks immediately jumped to a lazy, pre-packaged narrative: they blamed Israel.
How did a territorial squeeze in North Africa become an anti-Israel conspiracy?
How did a territorial squeeze in North Africa become an anti-Israel conspiracy?

Curtis Yarvin (a close associate of Peter Thiel & Marc Andreessen) wrote that “as the crappy govts we inherited … are smashed, they shld be replaced by a global spiderweb of…independent mini-countries, each governed by its own…corporation w/o regard to the residents’ opinions.” 1/

@pabloserdan 2/ Link: unqualified-reservations.org/2008/11/patchw…

@pabloserdan 3/ In 2013, Peter Thiel invested in a tech company founded by “patchwork society” blogger Curtis Yarvin aka Mencius Moldbug. So did Andreessen Horowitz, “led in the investment by Balaji Srinivasan, who was then a general partner”. archive.ph/2025.01.26-024…

Her wisdom was so great… even ‘Umar ibn al-Khattab (RA) trusted her judgment in matters of public welfare.
Who was she??
Who was she??
The streets of Madinah were alive. Merchants calling out prices, people trading, negotiating - the marketplace was the heartbeat of daily life, but also a place where injustice could quietly spread.
Among those trusted to uphold fairness was a woman.
Among those trusted to uphold fairness was a woman.
Her name was Shifā’ bint ‘Abdullāh (RA).
She was among the early Muslims of Makkah and was known for her intelligence and literacy at a time when reading and writing were not widespread.
She was among the early Muslims of Makkah and was known for her intelligence and literacy at a time when reading and writing were not widespread.

🚩 Children all over the UK have been the victims of sexual crimes in public swimming pool mixed-sex changing villages.
🚩 Sexual predators know that they can easily find their young victims in mixed-sex changing villages - especially during the school holidays.
🚩 When @Sport_England stated in its pool design guidance that ‘mixed-sex changing villages are the preferred option’ did they think of the safeguarding implications of presenting children to sexual predators?
🚩 When Councils built these pools - with public money - did they listen to local residents’ concerns? Did they even think of the hazards of allowing women and children to get undressed in cubicles next to predatory males?
🚩 Children are now suffering the consequences of decisions made without any regard for their safety. We have highlighted just a handful of the sexual crimes in swimming pool changing rooms. These all involve children, some as young as nine-years-old. 🧵
1/8
🚩 Sexual predators know that they can easily find their young victims in mixed-sex changing villages - especially during the school holidays.
🚩 When @Sport_England stated in its pool design guidance that ‘mixed-sex changing villages are the preferred option’ did they think of the safeguarding implications of presenting children to sexual predators?
🚩 When Councils built these pools - with public money - did they listen to local residents’ concerns? Did they even think of the hazards of allowing women and children to get undressed in cubicles next to predatory males?
🚩 Children are now suffering the consequences of decisions made without any regard for their safety. We have highlighted just a handful of the sexual crimes in swimming pool changing rooms. These all involve children, some as young as nine-years-old. 🧵
1/8



In Stoke-on-Trent, a mother took her daughter and another girl swimming at Waterworld.
Edward Earnshaw, 27, sexually assaulted the woman’s nine-year-old daughter while she was in a cubicle in the mixed-sex changing village.
The girl and her friend gave pre-recorded evidence to the court. The court recorder stated: “The trial put both girls through quite an ordeal having to give evidence… She was isolated and vulnerable in the cubicle.”
The girl’s mother said her daughter was normally a confident young girl, but she now suffers with separation anxiety and won't go upstairs on her own or remain downstairs alone. "She is receiving counselling through school and I worry about what long term effects this will have on her wellbeing as she approaches early adolescence. She will likely be more emotionally vulnerable than her peers on account of this awful experience.” 2/8
Edward Earnshaw, 27, sexually assaulted the woman’s nine-year-old daughter while she was in a cubicle in the mixed-sex changing village.
The girl and her friend gave pre-recorded evidence to the court. The court recorder stated: “The trial put both girls through quite an ordeal having to give evidence… She was isolated and vulnerable in the cubicle.”
The girl’s mother said her daughter was normally a confident young girl, but she now suffers with separation anxiety and won't go upstairs on her own or remain downstairs alone. "She is receiving counselling through school and I worry about what long term effects this will have on her wellbeing as she approaches early adolescence. She will likely be more emotionally vulnerable than her peers on account of this awful experience.” 2/8

Children aged 12 years old were among the many victims of ex-Scout Leader Ian Butcher, 55, who preyed on children in swimming pool changing rooms around Suffolk. The crimes were uncovered when a teenage girl reported that she had been filmed in a swimming pool cubicle by a man putting his hand over the top of the cubicle.
Police checks of his phone revealed 11 videos of voyeurism, mostly filmed in swimming pool changing rooms. Twenty screenshots from the videos capturing moments when nudity was visible were also found on Butcher’s phone.
Eight victims aged 12 to 32 were identified from the footage. A further six people could not be identified.
The crimes were investigated by the Internet Child Abuse Investigation Team. Detective Constable Santiago Nield said: “The crimes we discovered took place over a period of almost two years, so his offending was persistent for a significant length of time. Although not all of the victims were children, the majority were and so he clearly had a sexual interest in juveniles.”
DC Nield praised the bravery of the girl who first reported Butcher’s offending saying it had been crucial to his crimes being uncovered.
3/8
Police checks of his phone revealed 11 videos of voyeurism, mostly filmed in swimming pool changing rooms. Twenty screenshots from the videos capturing moments when nudity was visible were also found on Butcher’s phone.
Eight victims aged 12 to 32 were identified from the footage. A further six people could not be identified.
The crimes were investigated by the Internet Child Abuse Investigation Team. Detective Constable Santiago Nield said: “The crimes we discovered took place over a period of almost two years, so his offending was persistent for a significant length of time. Although not all of the victims were children, the majority were and so he clearly had a sexual interest in juveniles.”
DC Nield praised the bravery of the girl who first reported Butcher’s offending saying it had been crucial to his crimes being uncovered.
3/8


🚨🛑Spent all week tracing stolen crypto from 3 major hacks (Ronin, KelpDAO, Drift) linked to North Korean hackers.
Not the hack itself: what happens AFTER. Where does the money actually go?🛑
Thread 🧵
Not the hack itself: what happens AFTER. Where does the money actually go?🛑
Thread 🧵

Each hack laundered money completely differently:
• One used a privacy mixer
• One used a cross-chain swap tool
• One just sat on $90M+ for 110+ days before moving a cent
• One used a privacy mixer
• One used a cross-chain swap tool
• One just sat on $90M+ for 110+ days before moving a cent
I found the same "watcher" wallets touching all 3 unrelated hacks.
Almost certainly other researchers/bots doing exactly what I was doing.
Almost certainly other researchers/bots doing exactly what I was doing.
