
1/ First things first: Metrics, Logs, and Traces are not “the three pillars of observability.”
They are just the raw materials – the *telemetry* – and we must reframe our discussion of observability around use cases and problems-to-solve.
Thread:
They are just the raw materials – the *telemetry* – and we must reframe our discussion of observability around use cases and problems-to-solve.
Thread:

2/ The conventional wisdom looks like this…
Observability is this cool 6-syllable word that you know you want because it’s trendier than monitoring. And you get it (somehow) by purchasing Logs, Metrics, and Tracing.
Observability is this cool 6-syllable word that you know you want because it’s trendier than monitoring. And you get it (somehow) by purchasing Logs, Metrics, and Tracing.

3/ Of course, that makes no sense.
TL;DR, the people making the most noise about “metrics, logs, and traces as the three pillars of observability” are trying to sell them all to you. (Separately, of course)
How could the right observability workflow be so fragmented??
TL;DR, the people making the most noise about “metrics, logs, and traces as the three pillars of observability” are trying to sell them all to you. (Separately, of course)
How could the right observability workflow be so fragmented??
4/ The metrics, logs, and traces are all part of the story, but they are “the telemetry,” not “the observability.” Don’t confuse the two – conceptually, they are totally different. (PS: for high-quality, portable, easily-integrated telemetry, bet on @OpenTelemetry)
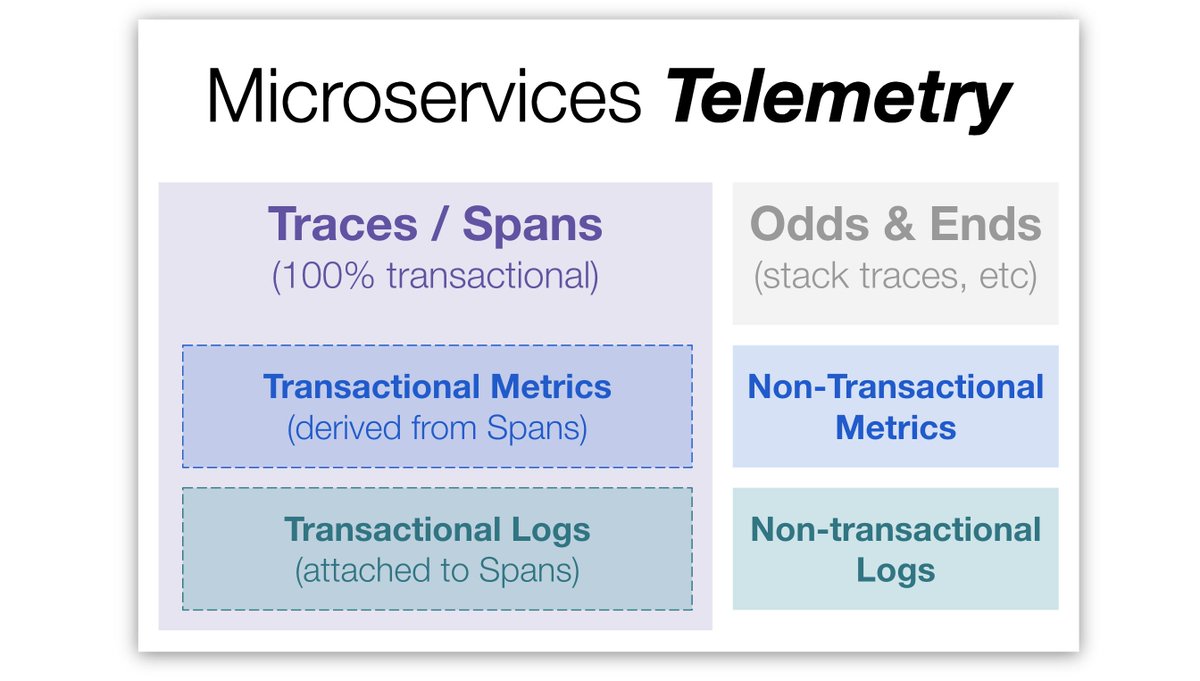
5/ Per the diagram ^^^, metrics, logs, and traces aren’t even conceptually distinct. Most metrics and logs describe end-to-end transactions, and thus derive from or decorate Spans.
Really, “metrics, logs, and traces” are more like “Spans, more spans… and some metrics and logs.”
Really, “metrics, logs, and traces” are more like “Spans, more spans… and some metrics and logs.”
6/ For microservices, 99.X% of observability use cases fall into one of two overarching themes:
1) Releasing new functionality with confidence
2) Minimizing SLO (“Service Level Objective”) violations
(For more on SLOs, see and/or oreilly.com/library/view/t…)
1) Releasing new functionality with confidence
2) Minimizing SLO (“Service Level Objective”) violations
(For more on SLOs, see and/or oreilly.com/library/view/t…)
7/ The first allows us to introduce new semantics/features, and the second makes our services dependable actors in the larger system, application, and *business*.
Most everything else (alerting, performance tuning, CI/CD, etc) rolls up into one of these broader use cases.
Most everything else (alerting, performance tuning, CI/CD, etc) rolls up into one of these broader use cases.
8/ We can only advance our practice of observability by getting away from the primitive idea that logs, metrics, and traces are *products*, and instead to see them as telemetry (that is, as *inputs*) to a modern observability solution (ahem, like @LightStepHQ).
9/ Once we reframe the problem in this way, we see what world-class observability can really be…
Scalable.
Robust.
Simple.
Scalable.
Robust.
Simple.





