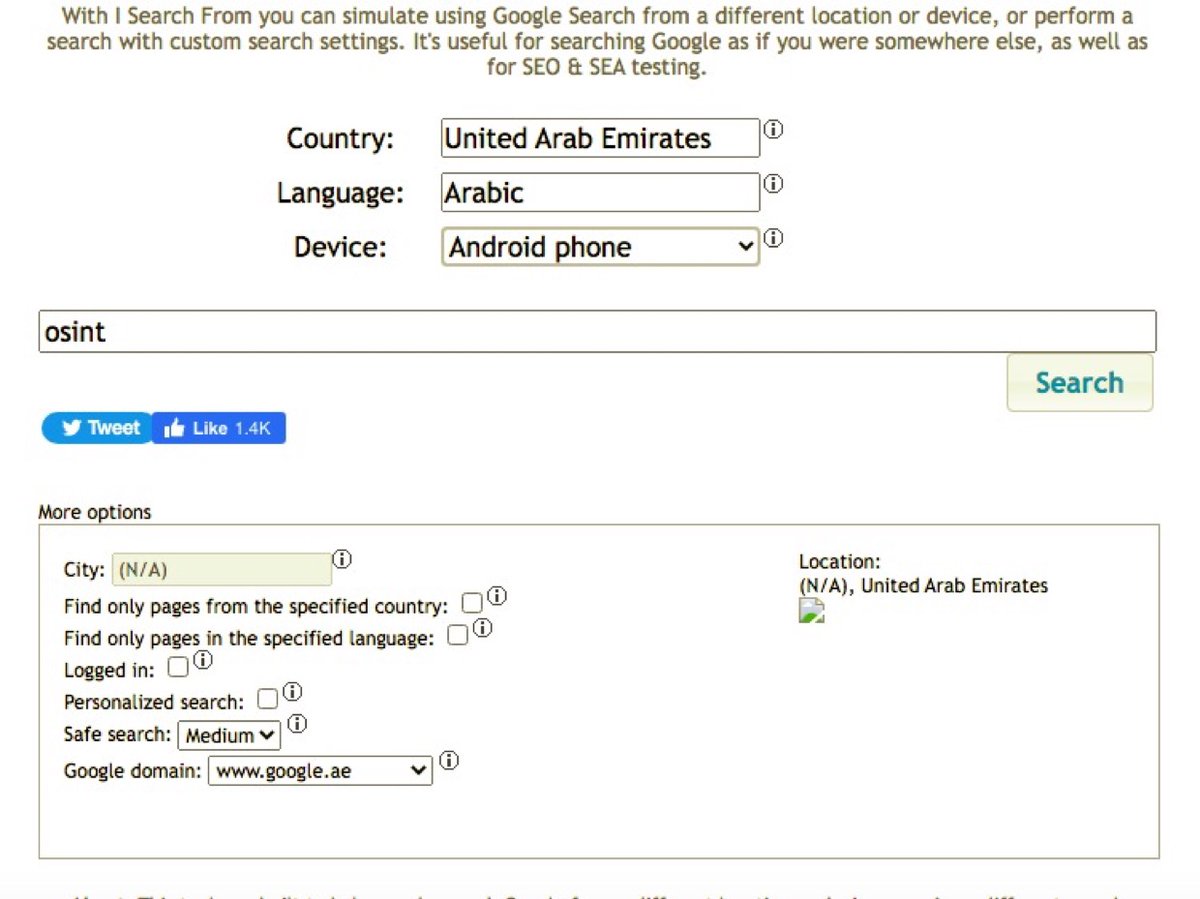
When searching for an old version of any site or page is not to limit to one archive.org, but to try different archives. Here is a link checker for all (26+search engines) archives I know at once:
cipher387.github.io/quickcacheanda…
Internet-archives #osint thread🧵⤵️⤴️
cipher387.github.io/quickcacheanda…
Internet-archives #osint thread🧵⤵️⤴️

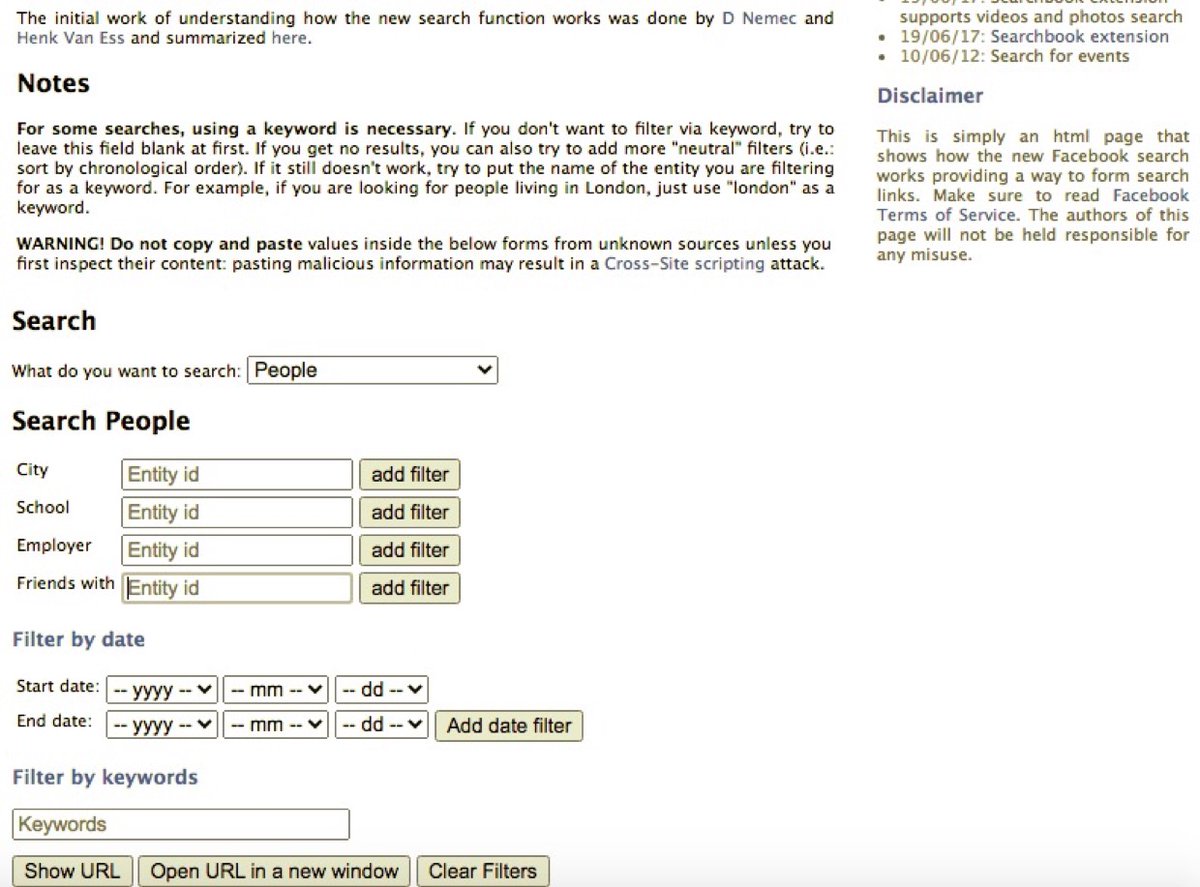
To see a list of all pages of a particular site stored in the archive, put an asterisk at the end of its URL (view pic).
This trick works for archive.org, Troove, and many other archives.
Internet-archives #osint thread🧵⤵️⤴️
This trick works for archive.org, Troove, and many other archives.
Internet-archives #osint thread🧵⤵️⤴️

For archive.org there is a special tool that shows a list of saved Wayback copies of the site and allows you to download a list of links to them in txt.
Internet Archive Wayback Machine Link Ripper:
tools.digitalmethods.net/beta/internetA…
Internet-archives #osint thread🧵⤵️⤴️
Internet Archive Wayback Machine Link Ripper:
tools.digitalmethods.net/beta/internetA…
Internet-archives #osint thread🧵⤵️⤴️

Remember that images in web archives are indexed by search engines. You can do a reverse image search on them using the "site:" operator in Google and Yandex.
Here's an example of the image from the first tweet.
Internet-archives #osint thread🧵⤵️⤴️
Here's an example of the image from the first tweet.
Internet-archives #osint thread🧵⤵️⤴️

Web Archives
An extension for Chrome that allows you to quickly check if there is a copy of the currently open page in 18 archives and search engine caches.
chrome-extension://hkligngkgcpcolhcnkgccglchdafcnao/src/options/index.html
Internet-archives #osint thread🧵⤴️⤵️
An extension for Chrome that allows you to quickly check if there is a copy of the currently open page in 18 archives and search engine caches.
chrome-extension://hkligngkgcpcolhcnkgccglchdafcnao/src/options/index.html
Internet-archives #osint thread🧵⤴️⤵️
Vandal
This extension speeds up, supplements, and enhances the standard Wayback Machine interface.
chrome.google.com/webstore/detai…
Internet-archives #osint thread🧵⤴️⤵️
This extension speeds up, supplements, and enhances the standard Wayback Machine interface.
chrome.google.com/webstore/detai…
Internet-archives #osint thread🧵⤴️⤵️
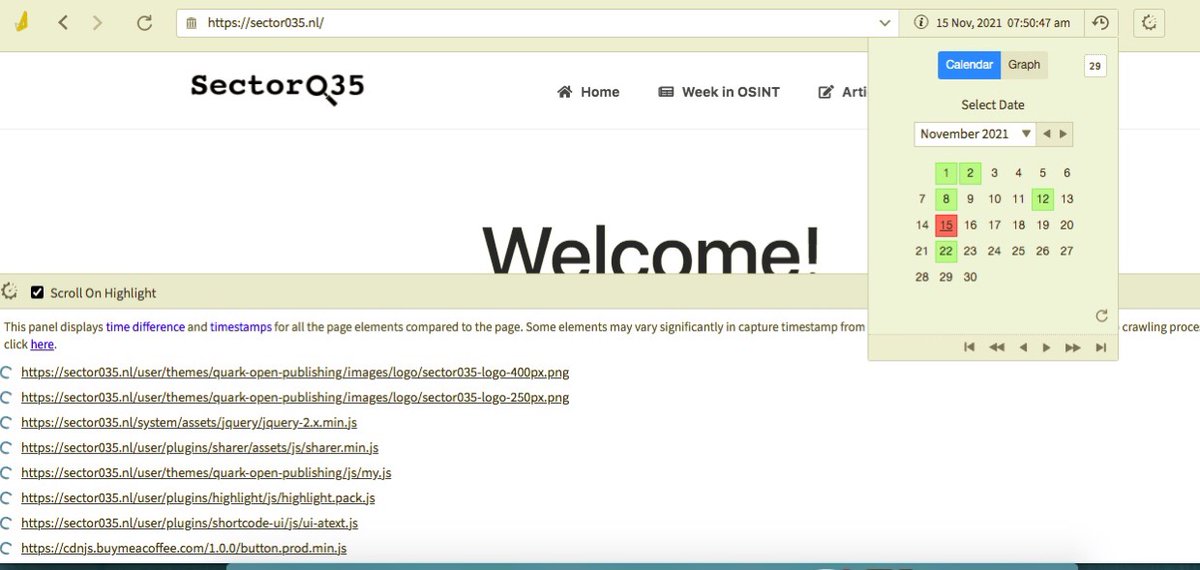
Wayback Pack
This #python-written tool allows you to automatically download all copies of the site saved to archive.org for a specific time period.
Internet-archives #osint thread🧵⤴️⤵️
This #python-written tool allows you to automatically download all copies of the site saved to archive.org for a specific time period.
Internet-archives #osint thread🧵⤴️⤵️

Wayback Machine Downloader
This #Ruby-based tool allows you to quickly download all the pages of a particular site from archive.org.
github.com/hartator/wayba…
Internet-archives #osint thread🧵⤴️⤵️
This #Ruby-based tool allows you to quickly download all the pages of a particular site from archive.org.
github.com/hartator/wayba…
Internet-archives #osint thread🧵⤴️⤵️

Sorry, link github.com/jsvine/wayback…
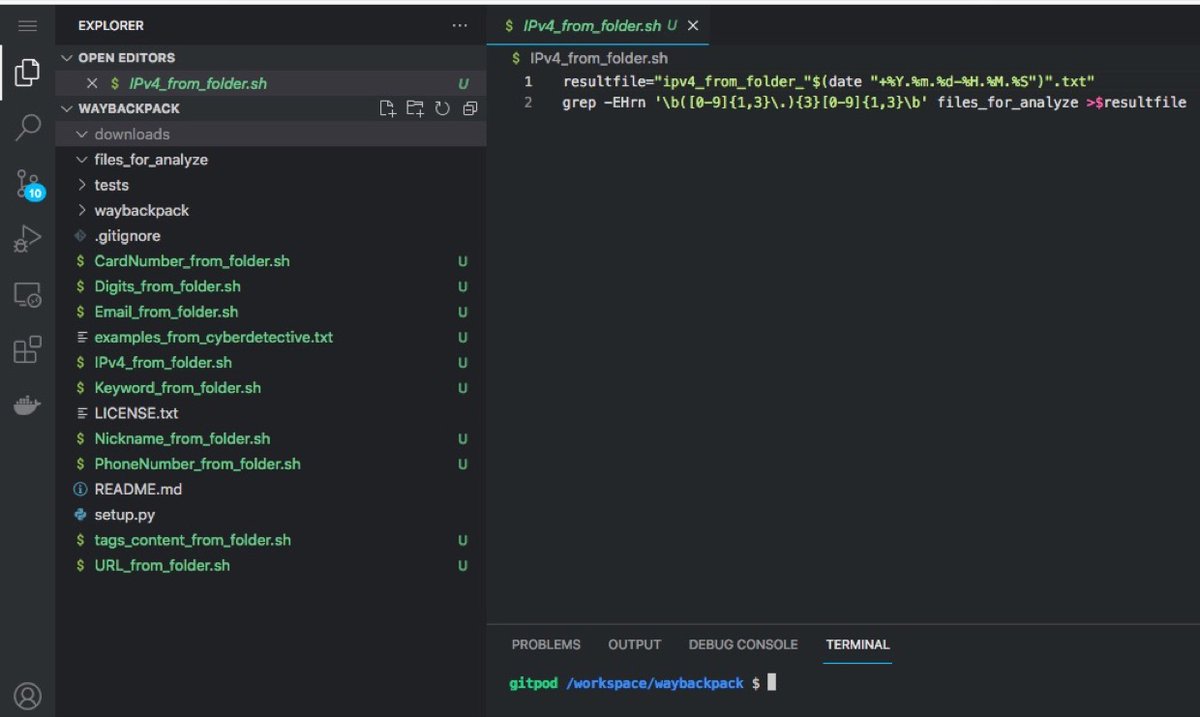
After downloading thecopies of the pages, they can be automatically analyzed for useful info: phone numberrs, emails, nicknames.
This is where #regularexpression and the Grep for OSINT shell-script set come in handy
github.com/cipher387/grep…
Internet-archives #osint thread🧵⤴️⤵️
This is where #regularexpression and the Grep for OSINT shell-script set come in handy
github.com/cipher387/grep…
Internet-archives #osint thread🧵⤴️⤵️
Archivarix.com
This tool allows you to restore an old version of a site from the archive and place it on a separate domain (in some cases you can even restore the CMS, but not always).
Partially free
Internet-archives #osint thread🧵⤴️⤵️
This tool allows you to restore an old version of a site from the archive and place it on a separate domain (in some cases you can even restore the CMS, but not always).
Partially free
Internet-archives #osint thread🧵⤴️⤵️

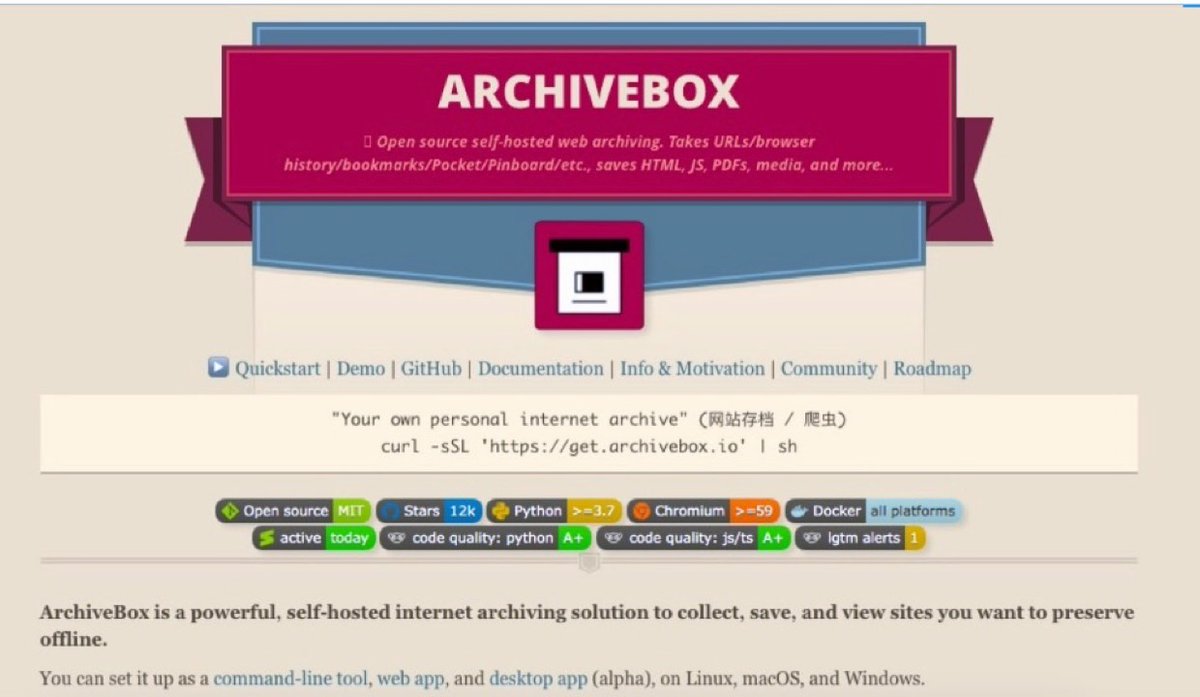
archivebox.io
Internet archives are a very unreliable thing. And a huge number of sites are not covered by them.
Therefore, if you need to save any important and useful web pages for the future, then create your own local archive.
Internet-archives #osint thread🧵⤴️⤵️
Internet archives are a very unreliable thing. And a huge number of sites are not covered by them.
Therefore, if you need to save any important and useful web pages for the future, then create your own local archive.
Internet-archives #osint thread🧵⤴️⤵️
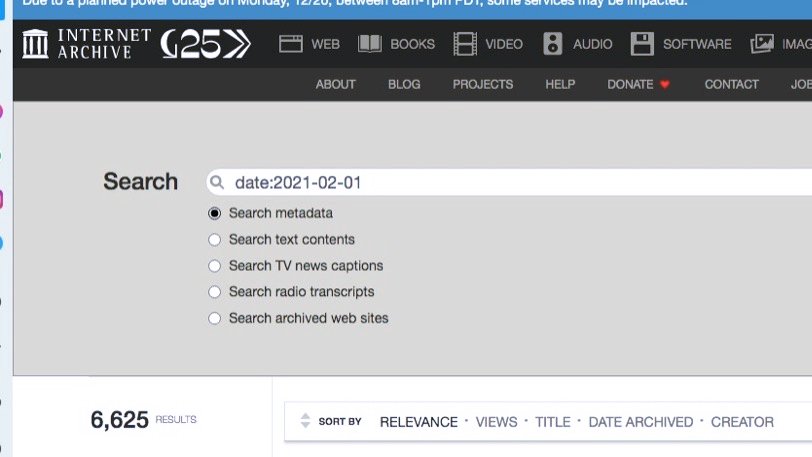
Archive.org stores all kinds of content: photos, documents, press, etc. When searching for these items, you can use advanced searches (and search operators) to filter results.
Internet-archives #osint thread🧵⤴️⤵️
Internet-archives #osint thread🧵⤴️⤵️

When investigating incidents that took place few years ago, be sure to consult local and federal television's archives for the relevant date.
Example of such site: americanarchive.org
Internet-archives #osint thread🧵⤴️⤵️
Example of such site: americanarchive.org
Internet-archives #osint thread🧵⤴️⤵️

This thread is end. I suggest you check out my other threads:
Google
Facebook
YouTube
Internet-archives #osint thread🧵⤴️⤴️
https://twitter.com/cyb_detective/status/1471791943592067076
https://twitter.com/cyb_detective/status/1468211025174540292
YouTube
https://twitter.com/cyb_detective/status/1438405361954865154
Internet-archives #osint thread🧵⤴️⤴️

@threader compile
@threadreaderapp unroll
@threadrip unroll
@PingThread unroll
@threadreaders unroll
@TurnipSocial save
@readwiseio save thread
@tresselapp save thread
@threadreaderapp unroll
@threadrip unroll
@PingThread unroll
@threadreaders unroll
@TurnipSocial save
@readwiseio save thread
@tresselapp save thread
• • •
Missing some Tweet in this thread? You can try to
force a refresh