0/ One of the upcoming L1s I'm most excited about is @CelestiaOrg, a modular, chain-agnostic data availability & consensus layer that provides a highly scalable & decentralized DA solution to rollups & app-specific L1 chains✨
A mega-🧵 on why you should pay attention (0/39)👀👇
A mega-🧵 on why you should pay attention (0/39)👀👇

@CelestiaOrg 1/ While most blockchain ecosystems agree that the future is multi-chain, the way they envision a multi-chain world can differ heavily. Approaches that have started to gain traction over the past few months are #Ethereum (rollups), #Polkadot (parachains) & #Cosmos (zones)
@CelestiaOrg 2/ So, according to its rollup-centric roadmap, #Ethereum envisions the future to evolve around rollup-based L2 solutions. But unfortunately, rollups tend to be rather expensive to operate/use & are less flexible than L1 chains (at least pre EIP-4844 / $ETH 2.0)
@CelestiaOrg 3/ One of the big advantages #rollups have though is shared security. @Cosmos on the other hand is an ecosystem of interoperable but sovereign application-specific L1 blockchains known as zones
@CelestiaOrg @cosmos 4/ While zones can be cheaper to use and more flexible than rollups, they don’t share full security with each other and spinning up a validator set to secure the network can be hard & expensive in itself
@CelestiaOrg @cosmos 5/ What #Celestia does, is it basically combines elements from both $ETH and $ATOM approaches & merges Cosmos' vision of sovereign & interoperable zones with Ethereum's rollup-centric shared security approach

@CelestiaOrg @cosmos 6/ Originally, #Celestia was born in search of an answer to the question what the least is a blockchain can do in order to offer shared security for other blockchains
@CelestiaOrg @cosmos 7/ The answer the @CelestiaOrg team came to, is that the most minimalistic blockchain to fulfill this criteria needs to do two things. It has to order the txs & ensure data availability for chains plugged into the #Celestia DA/consensus layer
@CelestiaOrg @cosmos 8/ Based on these two features, developers can basically build out any application on top of the data availability layer. It’s important to note though, that execution doesn't happen on Celestia. But we will get to that later
@CelestiaOrg @cosmos 9/ What's important to remember is that @CelestiaOrg only focuses on doing two things (tx ordering & making data available) but aims to do these two core things in a highly scalable way
@CelestiaOrg @cosmos 10/ So, before we dive into how #Celestia works in more detail, a few basic concepts should be quickly recalled. Every blockchain needs a set of nodes to validate the network's state. In general, these can be broken down into two categories. There are full nodes and light clients

@CelestiaOrg @cosmos 11/ Full Nodes: Also known as validator nodes, these nodes require a lot of resources because they download & validate every transaction on the blockchain. Full nodes offer a lot of security guarantees because they can't be fooled into accepting blocks with invalid txs
@CelestiaOrg @cosmos 12/ Light Clients: Do not download or validate any of the txs. Instead, they just download & check the block header, while assuming that the block contains valid txs. Hence, light clients offer weaker security guarantees compared to full nodes
@CelestiaOrg @cosmos 13/ Nevertheless, bc full nodes are very resource intensive, some network participants will prefer to run a light client. This is especially important from a decentralization point of view (lower barriers of entry)
@CelestiaOrg @cosmos 14/ To ensure light nodes are not tricked, full nodes can send over a fraud proof to the light clients if a block contains an invalid tx, instead of the light clients checking the txs themselves (and having to download all the data)
@CelestiaOrg @cosmos 15/ In a fraud-proof, full nodes provide light nodes with just enough data so they can autonomously identify invalid txs. The first step of this process requires full nodes to show light nodes a particular piece of data (e.g. tx claimed to be invalid) is included in the block
@CelestiaOrg @cosmos 17/ But there's a problem. Full nodes need to know the full tx data for a specific block to generate a fraud proof. If a block producer publishes the block header but not all tx data, the full nodes won't be able to check if txs are valid & generate fraud proofs if they are not
@CelestiaOrg @cosmos 18/ On @CelestiaOrg, data availability is guaranteed through light nodes using data availability sampling on erasure coded blocks. Erasure coding is a block encoding technique that empowers light nodes to verify at high probability that all data of a block has been published
@CelestiaOrg @cosmos 19/ At a high level, erasure coding adds redundancy to a string of data. The key property is that, if the redundant data is available, the original data can be reconstructed in the event some part of the data gets lost
@CelestiaOrg @cosmos 20/ Even more importantly though, it doesn’t matter which part of the data is lost. As long as X% (tolerance threshold) of the data is available, the full original data can be reconstructed
@CelestiaOrg @cosmos 21/ @CelestiaOrg uses 2D Reed-Solomon erasure codes with a 1/4 code rate. Validators erasure code blocks prior to publishing, turning a 1MB block of data into a 4MB block. Hence, if at least 25% of the txs in a block are available to the network, it can recover the remaining 75%
@CelestiaOrg @cosmos 22/ But let's have a quick look how data availability sampling works. So, initially a block producer publishes a block header. Subsequently, light nodes will start to request random chunks of data from that block from the block producer
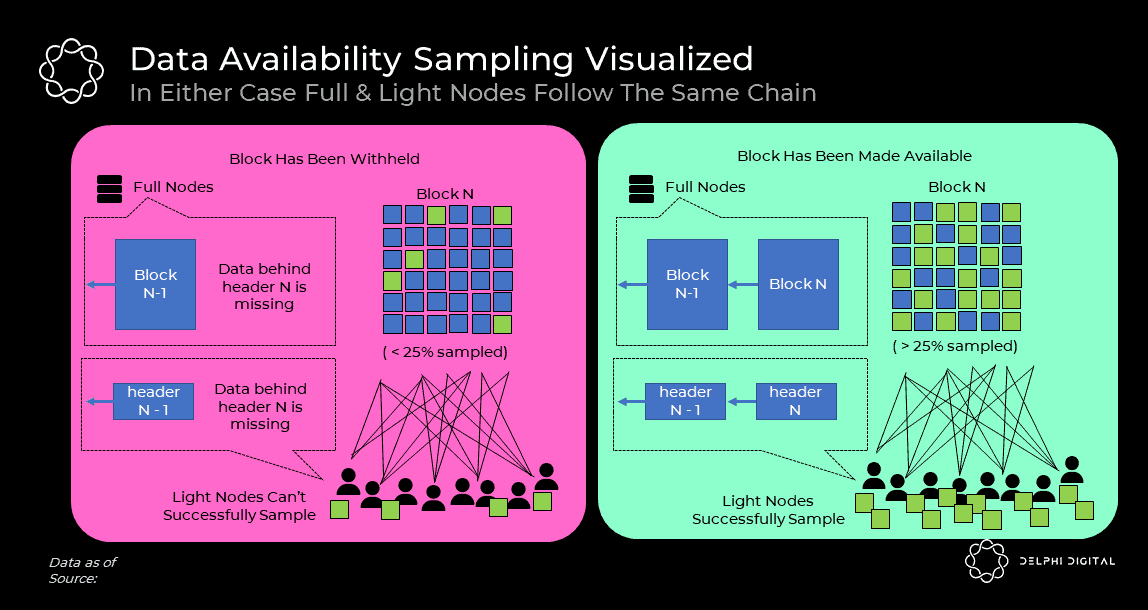
@CelestiaOrg @cosmos 23/ If data has been made available, the producer releases data chunks as light nodes request. Thanks to erasure coding, honest full node in the network can recover the original block from the broadcast chunks if light nodes collectively sample >25% of the erasure-coded block
@CelestiaOrg @cosmos 24/ By verifying that all tx data has been made available, light nodes can now fully rely on fraud proofs, knowing that any single honest full node can generate these proofs for them. However, there is a minimum number of light nodes required for this data sampling to work
@CelestiaOrg @cosmos 25/ If the block producer is malicious and withholds data, the light nodes notice as their sampling test fails and the network can be halted / recovered (ultimately through social consensus if needed)
@CelestiaOrg @cosmos 26/ A powerful feature is that @CelestiaOrg scales with the number of light nodes in the network. The more data sampling light nodes there are, the larger the block size can be while still ensuring security & decentralization

@CelestiaOrg @cosmos 27/ One very distinctive feature of @CelestiaOrg is the separation of execution and consensus / DA layer. While validity rules determine which txs are considered valid, consensus allows nodes to agree on the order of these valid txs
@CelestiaOrg @cosmos 28/ While #Celestia does have a consensus protocol (Tendermint) to order txs, it doesn’t reason about the validity of the txs & isn't responsible for executing them. Separating execution & consensus, ensuring validity is a responsibility of the chains composed on top of Celestia

@CelestiaOrg @cosmos 29/ Hence, rollup nodes simply monitor @CelestiaOrg to identify and download the txs that are relevant to their rollup to subsequently execute the txs & compute the rollup state
@CelestiaOrg @cosmos 30/ Interestingly, #Celestia implements a merkle tree sorted by namespaces. This is key in making Celestia a rollup-agnostic DA layer. Any rollup on Celestia can just download data relevant to their chain & ignore data for other rollups that are built on top of @CelestiaOrg
@CelestiaOrg @cosmos 31/ Rollups on @CelestiaOrg can basically be broken down into two main categories:
@CelestiaOrg @cosmos 32/ #Ethereum-based rollups: Use Celestia as a data availability layer, while Celestia would attest that to the $ETH L1. Hence, the flow is $ETH Rollup > #Celestia > $ETH. At no point does Celestia attest the block data back to the L2, making it entirely rollup agnostic
@CelestiaOrg @cosmos 33/ Celestia-based rollups: Post data & validity proofs (if zk-rollup) on Celestia. But while the data is stored on Celestia, Celestia won't verify the data's correctness. Hence, verification has to happen on a separate layer. An example is the #Cevmos stack which I'll cover tmrw

@CelestiaOrg @cosmos 34/ @CelestiaOrg also makes rollups super flexible. As it doesn’t make any sense of the data it stores & leaves all the interpretation to rollup nodes, the canonical state of a rollup on Celestia is independently determined by nodes choosing to run a certain client software
@CelestiaOrg @cosmos 35/ Hence, rollups on #Celestia are basically self-sovereign blockchains & nodes are free to hard/soft fork by upgrading their software & choosing to make sense of the underlying data in a different way, without significantly diluting network security
@CelestiaOrg @cosmos 36/ Another core feature is @CelestiaOrg’s execution-agnostic nature. Unlike Ethereum rollups, rollups on #Celestia don’t necessarily have to be designed for fraud/validity proofs interpretable by the EVM, opening up a wide array of alternative VM choices to #rollups
@CelestiaOrg @cosmos 37/ Also, unlike on $ETH, active state growth & historical data are treated completely separately on @CelestiaOrg. Celestia’s block space only stores historical rollup data measured & paid in bytes, while state execution is metered by the rollups themselves in their own units
@CelestiaOrg @cosmos 38/ Consequently, because the two things have separated fee markets, a spike of activity (and fees) in one place can’t deteriorate user experience in the other
@CelestiaOrg @cosmos 39/ So in conclusion, @Celestia is a modular data availability & consensus layer achieving scalability while maintaining a high degree of decentralization by scaling block verification instead of production through a scalable network of light nodes leveraging DAS & erasure coding
If you liked this thread please support with a a follow & retweet of the first tweet below👇🙏
https://twitter.com/expctchaos/status/1535970188012572672
• • •
Missing some Tweet in this thread? You can try to
force a refresh