I'm going to live tweet @m_sendhil's talk on "Economic Applications of Machine Learning" at @econ_uzh today 

We'll see 3 applications today. There have been hugely impressive engineering advances in this area in recent years.

Sendhil starts by introducing concepts with the example of face recognition.
The first step is to transform the engineering problem into an empirical problem. Rather than programming what a face looks like, make it into an empirical learning exercise. Is this a face, yes or no?
The first step is to transform the engineering problem into an empirical problem. Rather than programming what a face looks like, make it into an empirical learning exercise. Is this a face, yes or no?
A lot of this looks like computer science discovering statistics.
A large part is like money ball: application of statistical methods to new areas.
But that's not all.
A large part is like money ball: application of statistical methods to new areas.
But that's not all.

Many applications are high dimensional statistical problems. These are cases with many more variables than observations.
This type of high-dimensionality is relatively new. Especially what is new is that there are now a set of practical tools for this "applied nonparametrics".
This type of high-dimensionality is relatively new. Especially what is new is that there are now a set of practical tools for this "applied nonparametrics".

These models are data hungry in interesting ways. The more observations I get, the better more variable-intensive specifications will fit.

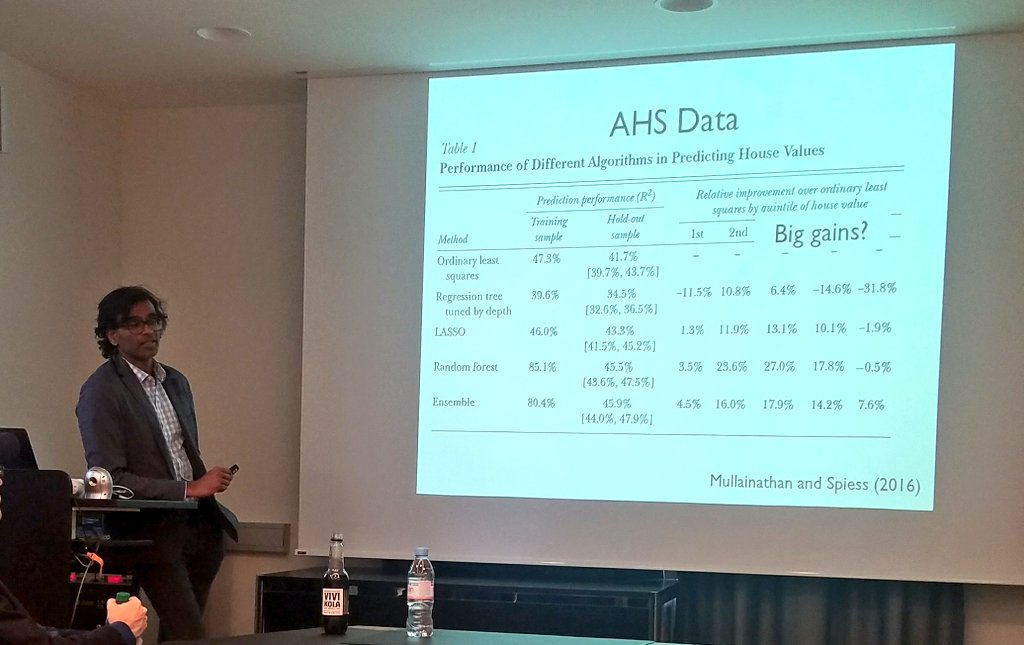
Example: House prices.
Improvement of R-square from OLS to bettet method from 42% to 46%. Is that a lot? Do we care?
Improvement of R-square from OLS to bettet method from 42% to 46%. Is that a lot? Do we care?

Difference of traditional econometrics regressions and machine learning:
First fits Y to X with low dimensionality. Machine learning does it out of sample and with high dimensionality.
Is machine learning just better?
First fits Y to X with low dimensionality. Machine learning does it out of sample and with high dimensionality.
Is machine learning just better?

Machine learning is perfect for a problem of predicting, like face recognition.
Economist often care less about that & more about the causal role of specific covariates.
E.g. if two covariates are correlated, we care about that for parameter estimation, but not for prediction.
Economist often care less about that & more about the causal role of specific covariates.
E.g. if two covariates are correlated, we care about that for parameter estimation, but not for prediction.

In other words, the classical approach is about estimating beta-hat, while machine learning is about estimating y-hat.
We'll now look at 3 types of application for economics:
We'll now look at 3 types of application for economics:

Application 1: machine learning in aid of parameter estimation.
Experimental analysis. Imagine I ran an RCT & I have a large number of outcomes. I want to see if there's an overall effect.
Experimental analysis. Imagine I ran an RCT & I have a large number of outcomes. I want to see if there's an overall effect.
Better than adjustment for multiple hypothesis testing (Bonferoni, etc.): check whether the outcomes predicts treatment better than chance. If yes, there's an effect. This requires fewer assumptions than what we typically need.
There are also ways to get exact p-values here.
There are also ways to get exact p-values here.

Treatment heterogeneity/subgroup analysis:
We know already that the question about which group responds more is not causal.
See work by Athey and Imbens on this.
We know already that the question about which group responds more is not causal.
See work by Athey and Imbens on this.


There are many parameter estimation problems that have machine learning aspects to them.
Here's a list:
Here's a list:

Application type 2: When predictability itself is of economic interest.
Example: 25% of health spending is in last part of people's life. If we could predict who would die despite of this treatment, we would not need to spend this amount and to make people undergo treatment.
Example: 25% of health spending is in last part of people's life. If we could predict who would die despite of this treatment, we would not need to spend this amount and to make people undergo treatment.
Problem: So far we can really not predict well at all who will die. Even among people with very similar conditions.
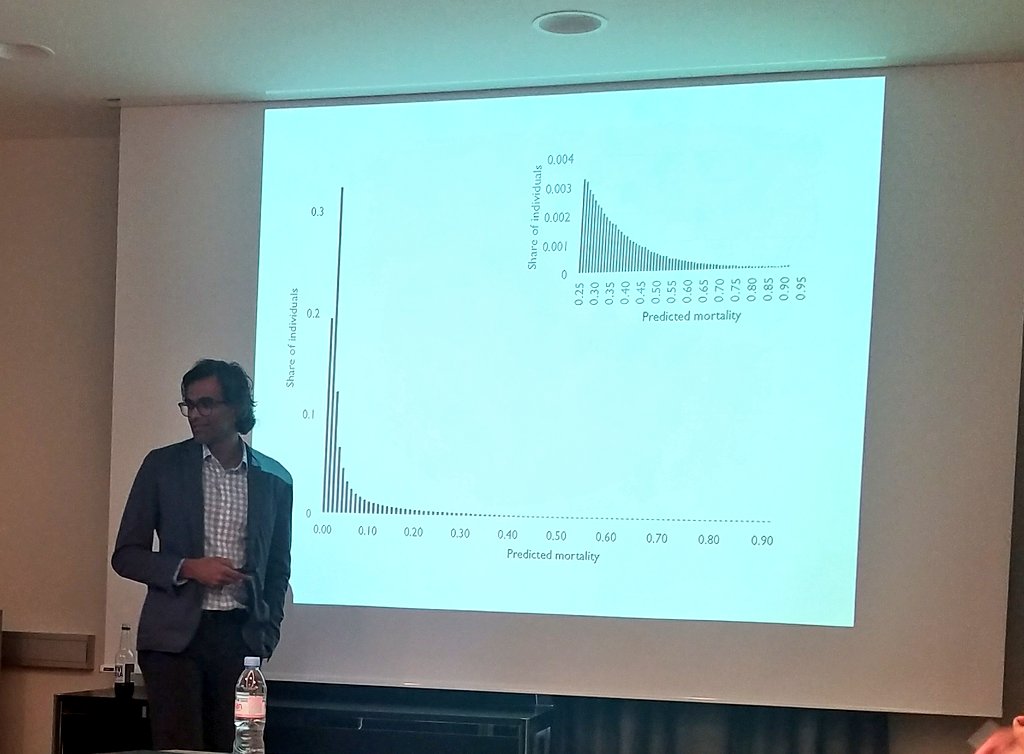
Would a better predictor fix this? No. When we have a base rate of dying of 5%, even with an excellent predictor we would mispredict many cases.


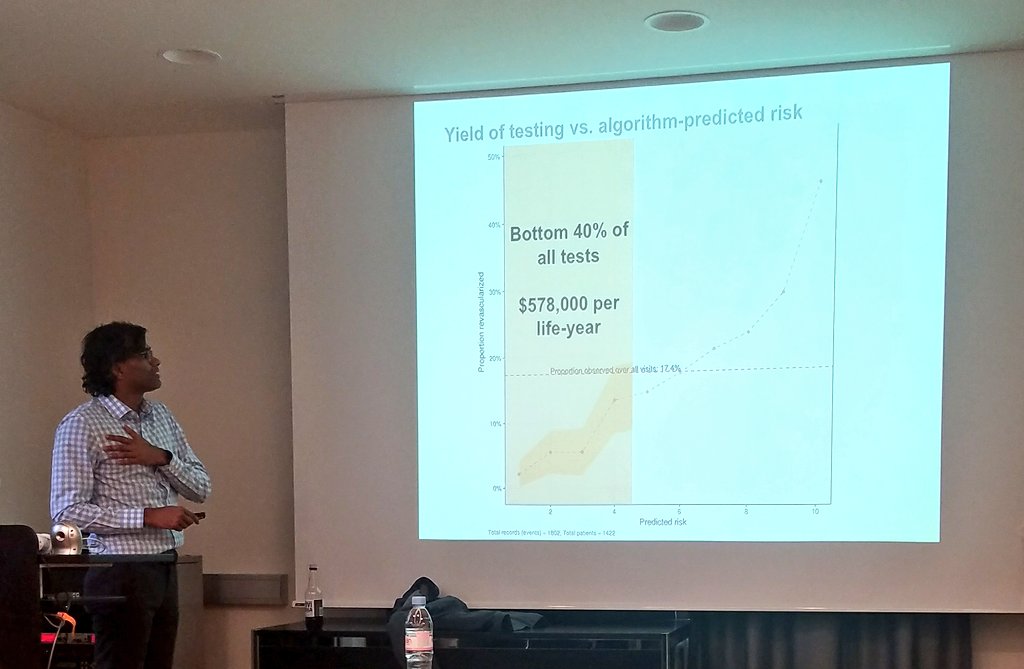
Another example: lots of testing for heart attacks are wasted.
The decision of who to test is actually a prediction problem: I wanna test the people for whom the test will find that they have a heart attack.
The decision of who to test is actually a prediction problem: I wanna test the people for whom the test will find that they have a heart attack.

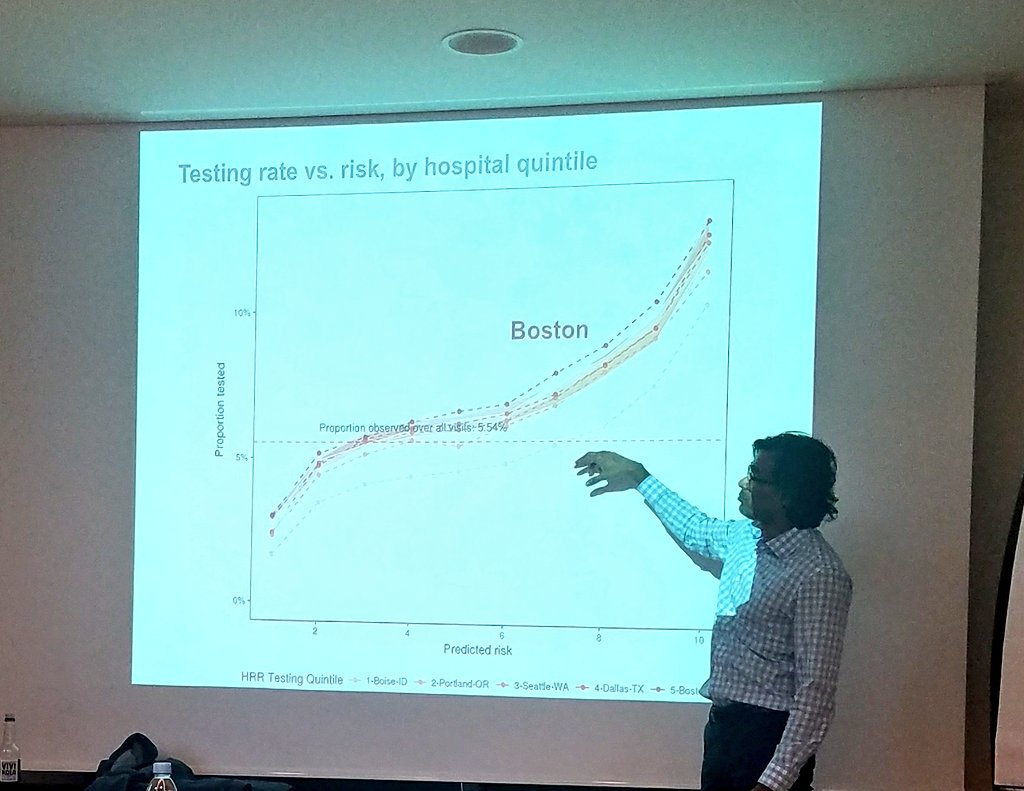
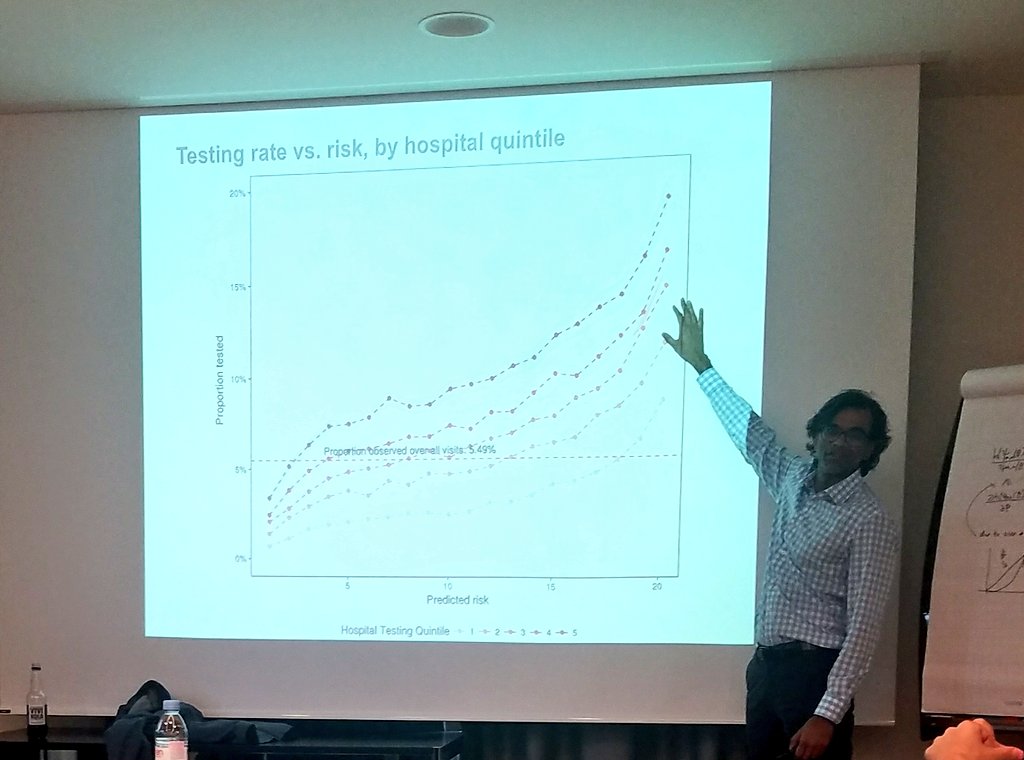
Rather than looking at the average, need to differentiate for whom the yield is large and for whom not.
There is under-testing of some people and over-testing of others.
There is under-testing of some people and over-testing of others.
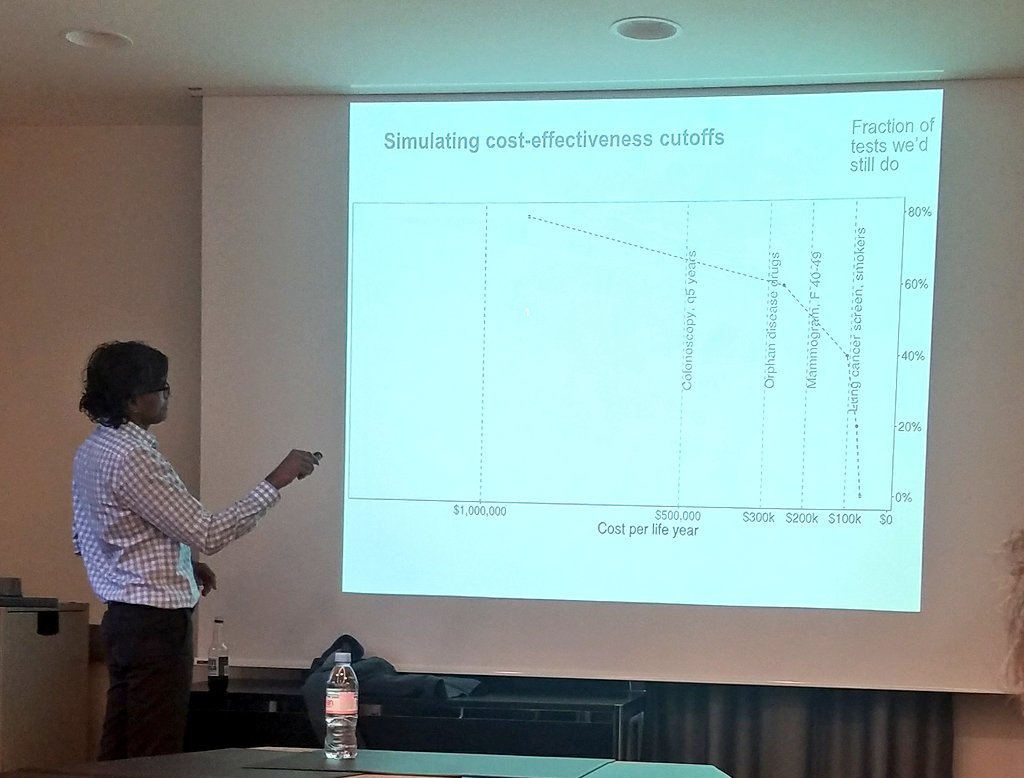
Problem: if you don't do the test, you don't know what the outcome of the test would have been.
Then testing on that selected sample will not be sufficient.
Need to look at what happened to the untested later on, and see if they got heart attacks.
Then testing on that selected sample will not be sufficient.
Need to look at what happened to the untested later on, and see if they got heart attacks.

Turns out there is huge under-testing.
It's a problem of sorting, of not predicting well whom to test. Not a case of generalized overtesting.
It's a problem of sorting, of not predicting well whom to test. Not a case of generalized overtesting.
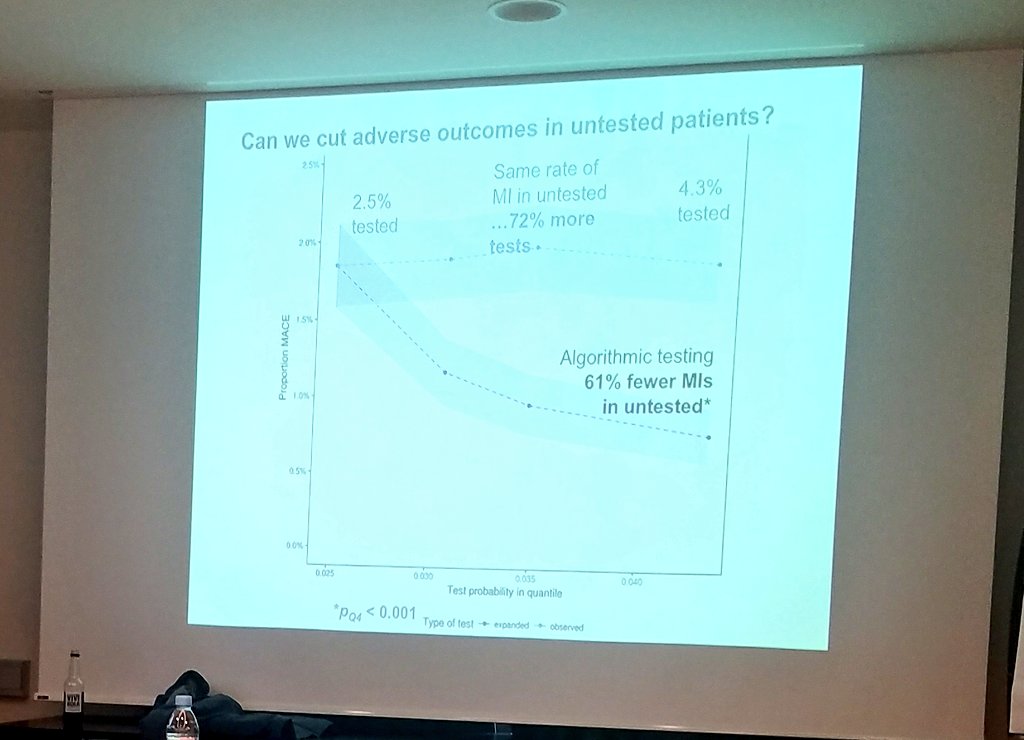
Getting people to cut overuse leads them to also cut high-yield use.
In conclusion:
Machine learning may help us improve in answering certain questions that economist already ask.
In addition, it allows us to ask entirely new questions.
Machine learning may help us improve in answering certain questions that economist already ask.
In addition, it allows us to ask entirely new questions.
Are these new question really economics? Well, much of what many people in this room do was not considered economics 10 years ago ;)
/end
/end