I'm going to live tweet Esther Duflo's Master Lecture at the NBER Development Economics meeting on "Machinistas meet Randomistas: Some useful ML tools for RCT researchers"
This presentation will focus more on methods rather than on anything specifically about development economics.
Many empirical researchers are starting to use machine learning (ML) in their work. This can provide some pointers and avoid reinventing the wheel.
Many empirical researchers are starting to use machine learning (ML) in their work. This can provide some pointers and avoid reinventing the wheel.

Machine learning usually is good for predictions while RCTs are mostly focused on causal identification. So is there even any intersection? The answer is yes.


In ML there are attempts for getting at causal estimation. And in RCTs there are sometimes high dimensional problems, where ML can help for choosing:
- Choosing covariates
- Subgroup Analysis for heterogeneity
- Cases with many treatments and potential outcomes
- Choosing covariates
- Subgroup Analysis for heterogeneity
- Cases with many treatments and potential outcomes

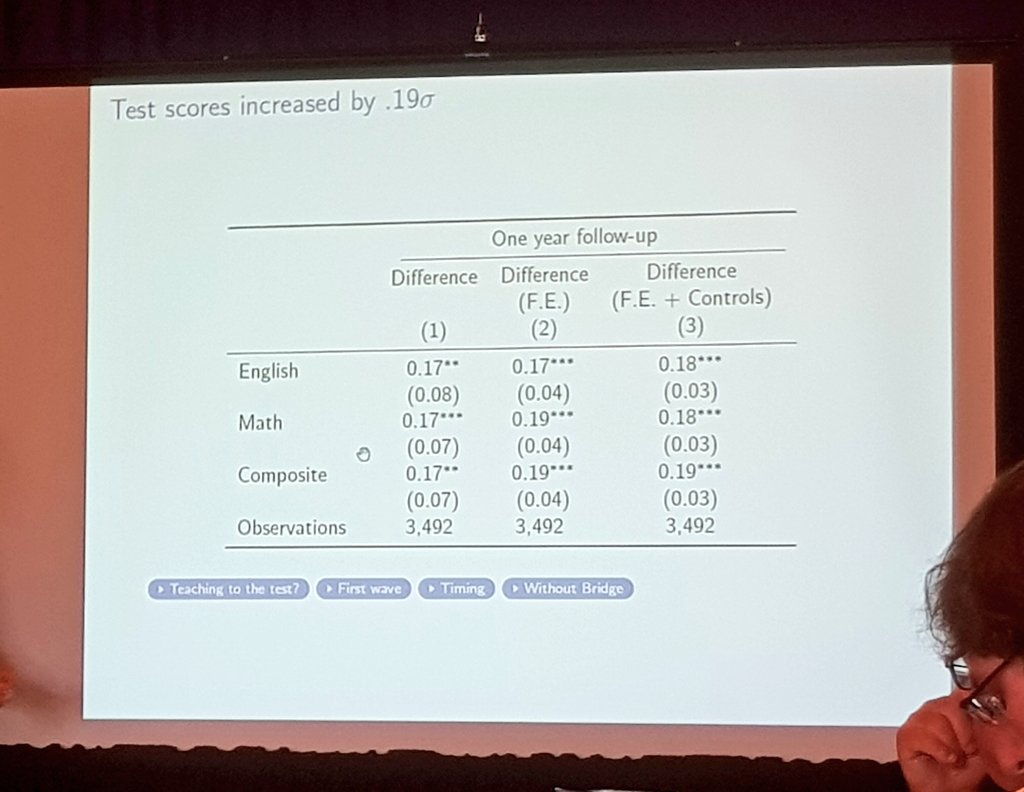
We can do a comparison of results of different methods including ML, following the example of Lalonde.
There is a paper by Chernozhukhov and many co-authors:
There is a paper by Chernozhukhov and many co-authors:

When people do RCTs, they can now going forward use them to also help test the validity of some of these new methods.




This has to be done in two steps


There is no magic there. Similarly as to how with matching methods,the matching is only as good as the observable variables that researchers have, machine learning has these limits, too.

The Lalonde exercise with the two step machine learning.
Caveats: 1) Is the IV estimate valid? 2) Is the effect different for compliers in the local average treatment effect than in population?
Can address the 2nd caveat with this method but not the 1st:
Caveats: 1) Is the IV estimate valid? 2) Is the effect different for compliers in the local average treatment effect than in population?
Can address the 2nd caveat with this method but not the 1st:


For some outcomes the results are similar, for others very different. Hard to know which is the better one. Would be great to compare directly with RCT results. It was not possible here.
Interesting question: What kind of heterogeneity can be picked up with observables?
Interesting question: What kind of heterogeneity can be picked up with observables?



Second topic of the lecture: Choosing control variables in RCTs.
People tend to include the variables that are very imbalanced and those that they think most predict the outcomes.
It turns out with Lasso it has been shown that's exactly what one should indeed do.
People tend to include the variables that are very imbalanced and those that they think most predict the outcomes.
It turns out with Lasso it has been shown that's exactly what one should indeed do.

This is better than using a specific set of variables pre-specified in a pre-analysis plan, since you don't know ex-ante which variables will be unbalanced.
Make the choice ex-post, but in a structured way (can pre specify this process.)
Make the choice ex-post, but in a structured way (can pre specify this process.)

Third topic of the lecture: heterogeneity of treatment effects on different populations.
This is something that could actually have substantive impact for many research areas.
Often there is a large number of groups one could look at.
This is something that could actually have substantive impact for many research areas.
Often there is a large number of groups one could look at.

That's potentially a problem for multiple hypothesis testing.
One solution is pre-registering.
This is important for clinical trials. There, the goal is simply to test, does this drug work? Also, there's a slot of money on the table to find a "yes" answer.
One solution is pre-registering.
This is important for clinical trials. There, the goal is simply to test, does this drug work? Also, there's a slot of money on the table to find a "yes" answer.
However its different in social science, where we want to learn more about the world.
There, pre-registering specific subgroups risks throwing out valuable information that is only available ex-post.
Alternative solution: use a ML process to select the groups.
There, pre-registering specific subgroups risks throwing out valuable information that is only available ex-post.
Alternative solution: use a ML process to select the groups.
However, it's not as simple. We don't just want to predict who will benefit most in this particular setting based on a large number of variable. We want to draw inferences out of sample for particular types of people.
Focus on key feature that are of interest.
Focus on key feature that are of interest.

Methodological notation:




This approach is generic for different types of ML being used.
Proofs are in the paper.
Two different strategies:
Proofs are in the paper.
Two different strategies:




One of the lessons: if one is interested in heterogeneity, might want to double the sample size. But don't need to double the number of clusters. Can split the sample within the clusters.

Two sources of the noise:


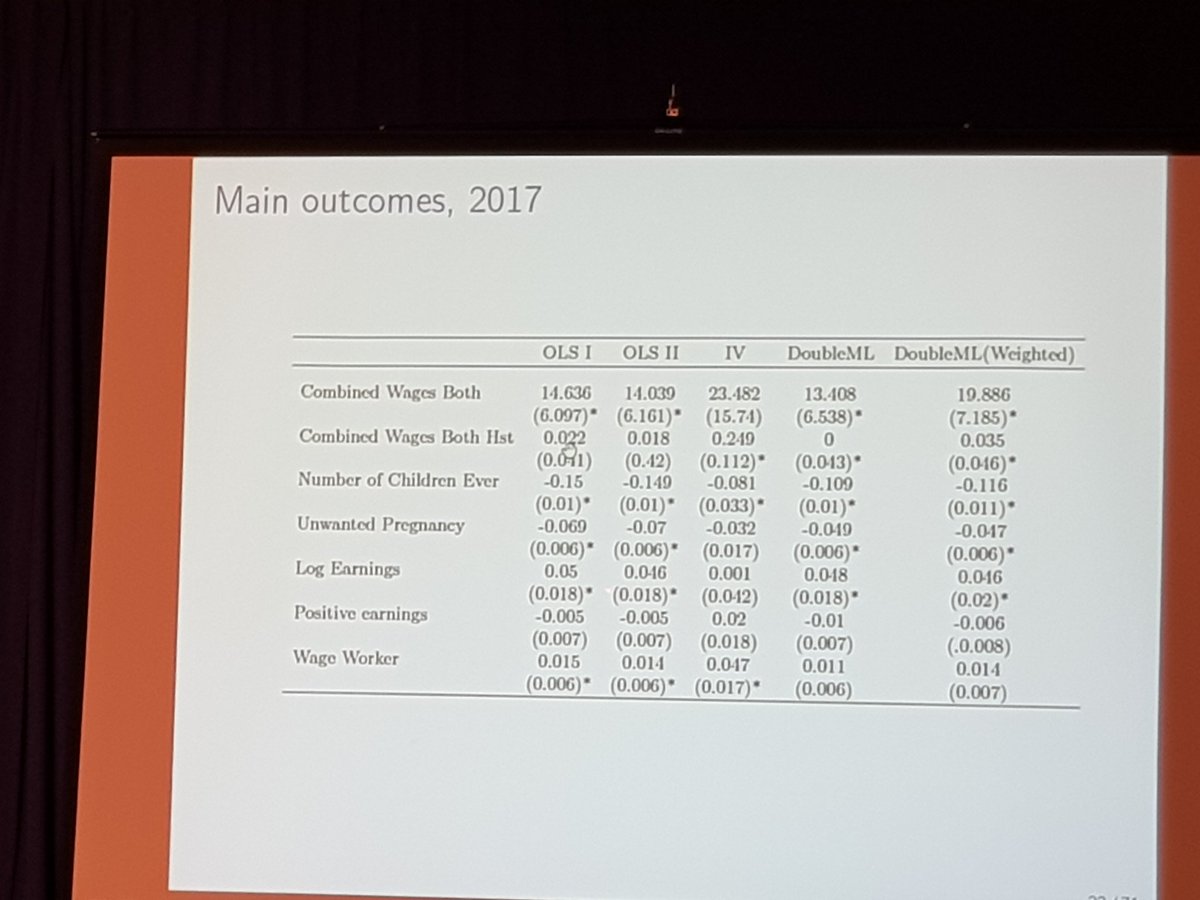
Application to data from Morocco:

The technical process:

Reject zero: some real heterogeneity in loans, output, and profit, but not in consumption.
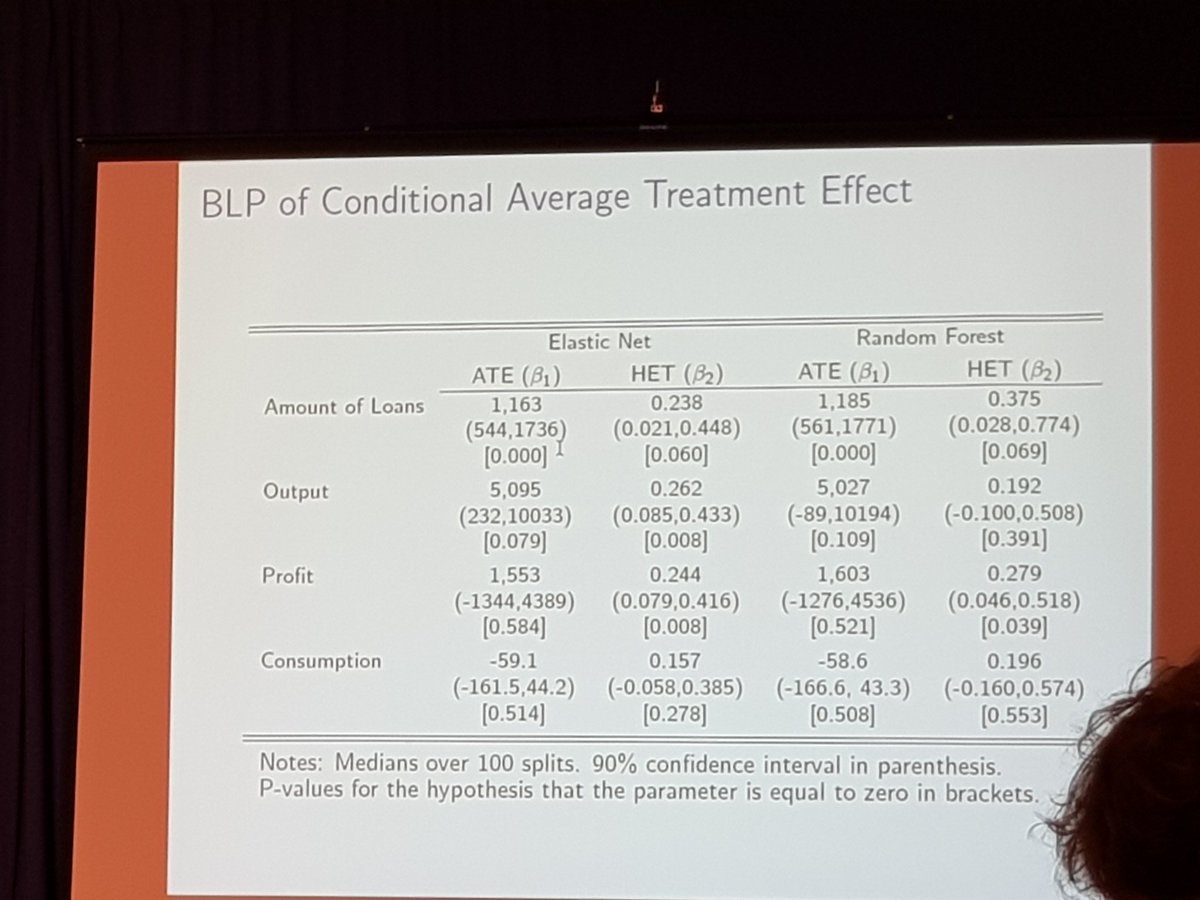
Sorting from least to most affected groups.
Now can try and say something about the characteristics of people in these groups:
Now can try and say something about the characteristics of people in these groups:


Next we're going to look at a more substantive application, which is not in development. It's about France:
Comparing two intervention that have the same goal, but have been analyzed in two separate studies:
Comparing two intervention that have the same goal, but have been analyzed in two separate studies:

So there are both differences in the intervention but also in the population.
Can we predict what would have been the effect of intervention A in the population B?
Can we predict what would have been the effect of intervention A in the population B?

Comparing 2 programs. One by a microcredit agency, one by the social service.
They target youths with difficult employment situations who have a self-employment project.
The first program is selective. Tries to select the most enthusiastic & most prepared. The second takes all.
They target youths with difficult employment situations who have a self-employment project.
The first program is selective. Tries to select the most enthusiastic & most prepared. The second takes all.
Also the first program really tries to train the youths in entreneurship. The second tries to help them see if entreperenuship is a good fit for them, or employment would be better.
Second program has effects. First doesn't.
Is this because of selection or treatment?
Second program has effects. First doesn't.
Is this because of selection or treatment?

Matching on observables: not much of a difference.
But: the control group in the first program still develops very differently from the second.
They select on the basis of an interview that the researchers don't observe.
But: the control group in the first program still develops very differently from the second.
They select on the basis of an interview that the researchers don't observe.


Take the experiment where have many baseline characteristics.
Look at probability of being employed in the control group. Sample people in the other experiment who have similar characteristics:
Look at probability of being employed in the control group. Sample people in the other experiment who have similar characteristics:




This is what Heckmann calls cream-skimming, but in reverse: selective program took people who would have likely found a job anyway & there they had less impact.
The effect was largest for people with low probability of employement without the program. (They also look at income.)
The effect was largest for people with low probability of employement without the program. (They also look at income.)


Last point: Weight the population to look observably similar.
There's an entire literature on how to do that.
Were limited in this because of sample size. Very large standard errors. But the logic of this approach could be used elsewhere.
There's an entire literature on how to do that.
Were limited in this because of sample size. Very large standard errors. But the logic of this approach could be used elsewhere.


You can find all the code online here:

They videotaped this, so I hope this will be online some time soon. I'll post the video when I see it come online.