,
10 tweets,
7 min read
Read on Twitter
Delighted to see our new paper out in @NatureMedicine - see below for a few take-home messages. @mgroussi @gibbological @ejalm @jravilap @jiang_bioinfo @microbetrainer @BerdyAndTheBees @Shijie_Zhao @conTaminatedsci @OpenBiome @broadinstitute
nature.com/articles/s4159…
nature.com/articles/s4159…
Cross-sectional surveys have generated exciting hypotheses for how our bacteria influence our health and well-being. Next phase in #microbiome research requires that we develop a personalized model of the gut ecosystem and test hypotheses more directly with bacterial isolates.
Here, we unveil the @broadinstitute @OpenBiome Microbiome Library (BIO-ML) a resource of thousands of human gut bacterial isolates paired with whole genome sequences and longitudinal multi-omic data (broadinstitute.org/bio-ml).
Culturing can capture extensive bacterial diversity including fastidious species that only have very few representatives in databases and organisms that are missed by culture-free methods. We isolated previously unknown species within #Akkermansia and #Faecalibacterium genera. 
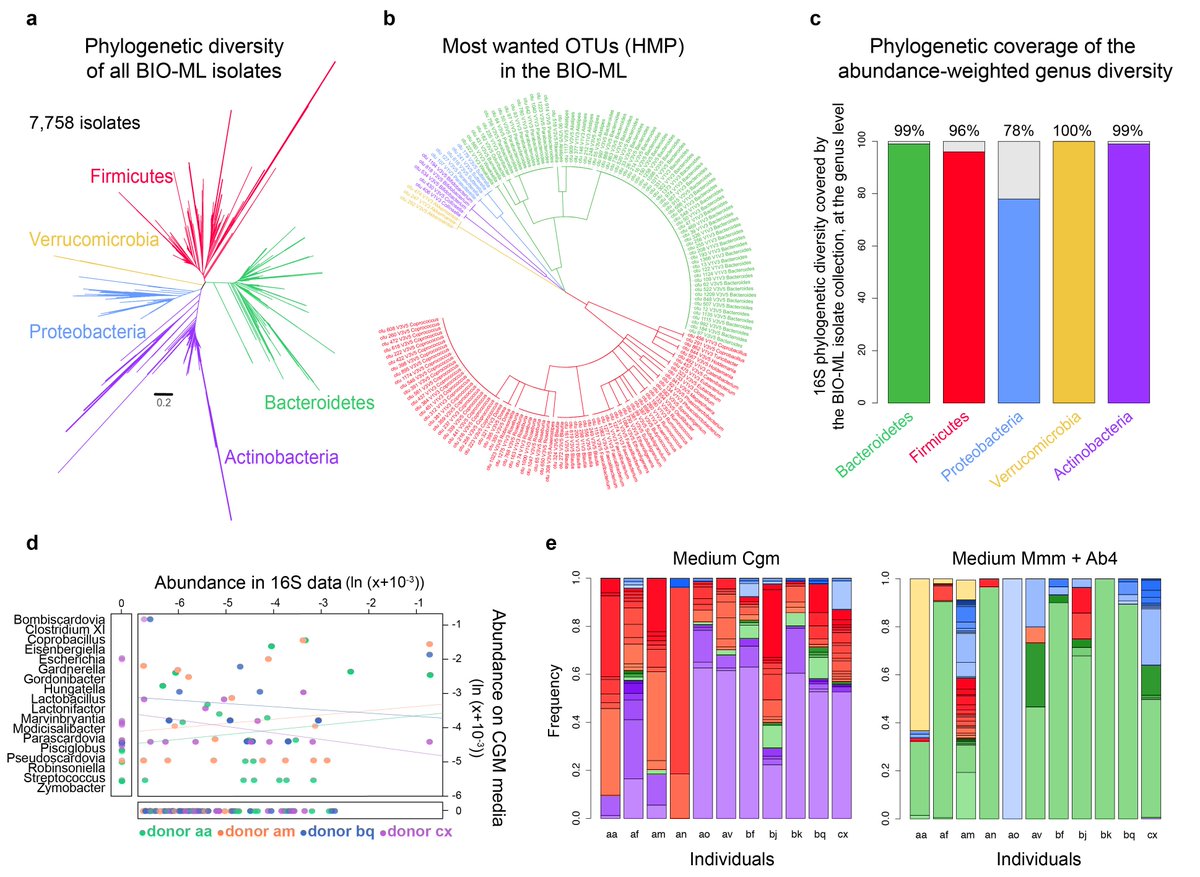
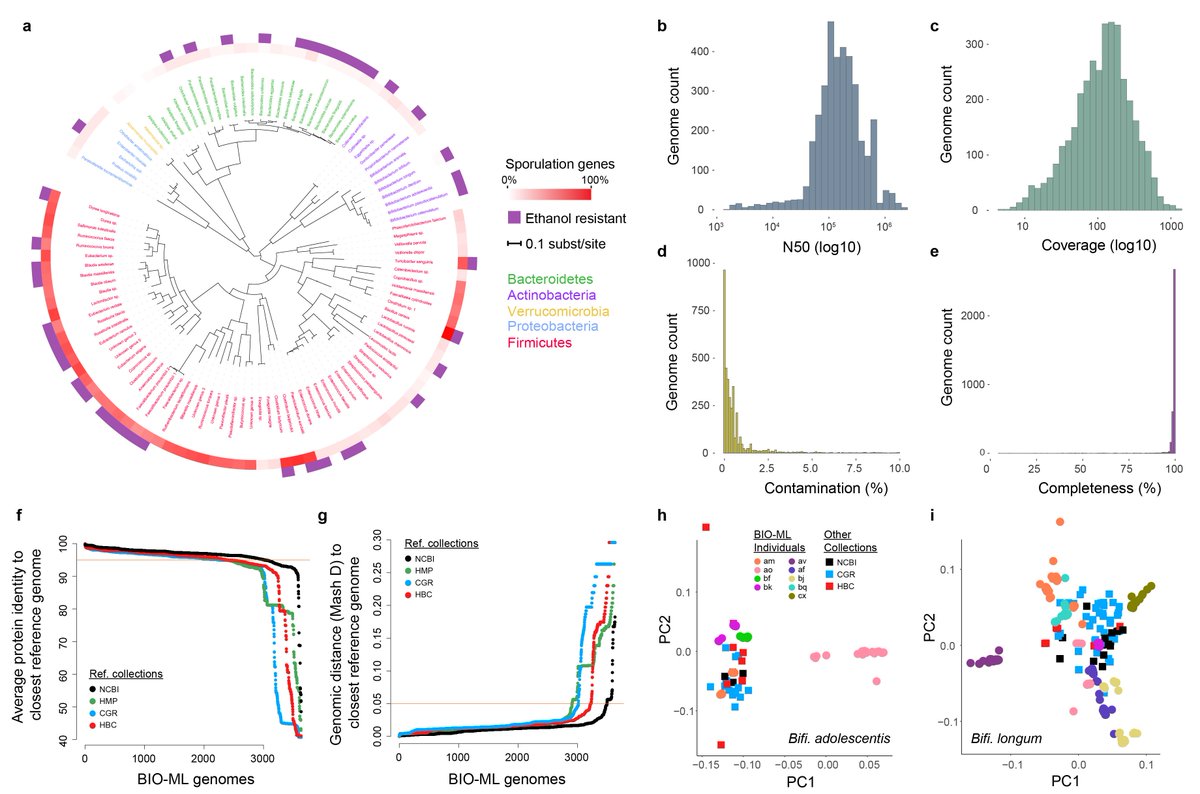
Genomic analyses reveal ecological and evolutionary processes shaping the gut microbiome. For example resistance to ethanol is more widespread than previously thought and not restricted to spore-formers.
The BIO-ML set of genomes provide high-resolution cross-sectional and longitudinal data, at the strain level. As an illustration of what this resource offers, we show that gene content dynamics pre- and post-colonization of individual hosts can be estimated.

How many samples from the same person do you need to get accurate estimates of abundance? We show that a minimum of 5-9 time points provide optimal estimate of bacterial population sizes, which in turn allows for more reliable estimation of cross-sectional correlation networks.

Despite longitudinal abundance stabilities of bacterial species and functions over time within people, non-stationary dynamics associated with genomic diversification and ecological replacements can be observed at the strain level.

Gut metabolome profiles are highly donor-specific and differences between people are driven by differences in bile acid concentrations. Temporal fluctuations within a donor’s gut metabolome are dominated by changes in amino acids. Future experiments are needed to understand why.

Sequencing data is available online: NCBI BioProject PRJNA544527 - Scripts and command lines are available at github.com/almlab/BIO-ML - Isolates can be requested at broadinstitute.org/bio-ml