Differentiable Digital Signal Processing (DDSP)! Fusing classic interpretable DSP with neural networks.
⌨️ Blog: magenta.tensorflow.org/ddsp
🎵 Examples: g.co/magenta/ddsp-e…
⏯ Colab: g.co/magenta/ddsp-d…
💻 Code: github.com/magenta/ddsp
📝 Paper: g.co/magenta/ddsp-p…
1/
⌨️ Blog: magenta.tensorflow.org/ddsp
🎵 Examples: g.co/magenta/ddsp-e…
⏯ Colab: g.co/magenta/ddsp-d…
💻 Code: github.com/magenta/ddsp
📝 Paper: g.co/magenta/ddsp-p…
1/
2/ tl; dr: We've made a library of differentiable DSP components (oscillators, filters, etc.) and show that it enables combining strong inductive priors with expressive neural networks, resulting in high-quality audio synthesis with less data, less compute, and fewer parameters.

3/ An example DDSP module is an Additive Synthesizer (sum of time-varying sinusoids). A network provides controls (frequencies, amplitudes), the synthesizer renders audio, and the whole op is differentiable . Here's a simple example with harmonic (integer multiple) frequencies.
4/ While the DDSP components can be used in any end-to-end system, we focus on the effect of the components themselves by performing experiments with a simple audio autoencoder (no autoregression or GAN required). The DDSP components are the yellow blocks. F0 is frequency.

5/ We combine a harmonic additive synth (sum of sinusoids) with a subtractive noise synth (filtering white noise), and a learned room reverb, to generate a waveform. The loss is then L1 on a multi-scale spectrogram. Since everything is differentiable we can train with SGD.
6/ The key idea of DDSP is that simple DSP components can be quite expressive when precisely controlled by a neural network (e.g. high-quality reconstructions). We can also exploit modularity and interpretablity to swap components and get things like dereverberation for free.
7/ Since the model directly uses interpretable inputs like frequency in rendering the waveform, it allows generalization outside the domain of the training data. Here we transpose the violin an octave lower than is physically possible and it sounds somewhat like a cello.
8/ Further, we can get features such as pitch and loudness from one signal and use the trained model to resynthesize (timbre transfer). There are small hiccups when the features don't match training, but the model does surprisingly well given that it wasn't trained to do this.
9/ Here's an example of turning @hanoihantrakul into a violin. You can try this yourself with the colab demo (g.co/magenta/ddsp-d…). You can also train your own models and use them in the demo. We can't wait to see how you use it!
10/ One of the coolest things about using these priors is it takes much less data and compute to do ML with audio. All examples here use less than 13 minutes of data and a few hours on a V100. Hanoi could even train a model on his own Salo instrument (cargocollective.com/sloh/filter/Sl…).
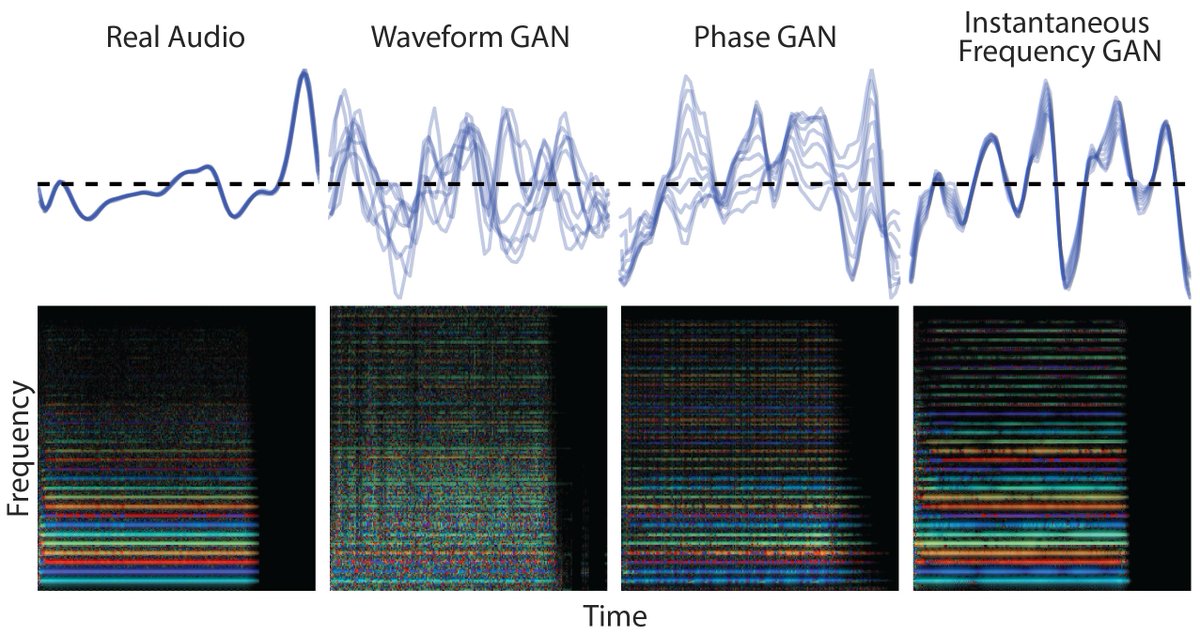
11/ One of the key priors these models exploit is perceptual invariance to relative phase for steady state signals (which was the basis of GANSynth, a differentiable phase vocoder). Notice how all these examples sound the same even though the waves look quite different.
12/ Since we're excited about the possibilities of this approach, we've worked really hard to make a clean and modular code base (github.com/magenta/ddsp), several colab tutorials (github.com/magenta/ddsp/t…), and we welcome contributions! DSP is hard to get all the details right 😇
13/ From a research perspective there's a lot of potential followup. We've added some new modules (Wavetable synth, ModDelays, etc.) but still many more possible (Polyphony, IIR, etc.). Also, models using DDSP create samples during training, which is ideal for GANs, EBMs, etc.
14/ For applications, early experiments are promising. We can push the model size down very small (a single 256 unit GRU, 240k parameters, g.co/magenta/ddsp-e…) and still get pretty good performance, opening avenues towards realtime neural audio synthesis and manipulation.
This was a really fun collaboration with @HanoiHantrakul, @ada_rob, and @calbeargu. Also thanks to @notwaldorf for all the help, and to @andycoenen for the designing a sweet logo.
Finally, many thanks to Dr. Xavier Serra of @mtg_upf and Dr. Julius O. Smith III of @ccrma, whose pioneering work on Spectral Modeling Synthesis (jstor.org/stable/3680788…) was the foundation and inspiration for a lot of this research.