,
10 tweets,
5 min read
Read on Twitter
Make music with GANs!
GANSynth is a new method for fast generation of high-fidelity audio.
🎵 Examples: goo.gl/magenta/gansyn…
⏯ Colab: goo.gl/magenta/gansyn…
📝 Paper: goo.gl/magenta/gansyn…
💻 Code: goo.gl/magenta/gansyn…
⌨️ Blog: magenta.tensorflow.org/gansynth
1/
GANSynth is a new method for fast generation of high-fidelity audio.
🎵 Examples: goo.gl/magenta/gansyn…
⏯ Colab: goo.gl/magenta/gansyn…
📝 Paper: goo.gl/magenta/gansyn…
💻 Code: goo.gl/magenta/gansyn…
⌨️ Blog: magenta.tensorflow.org/gansynth
1/
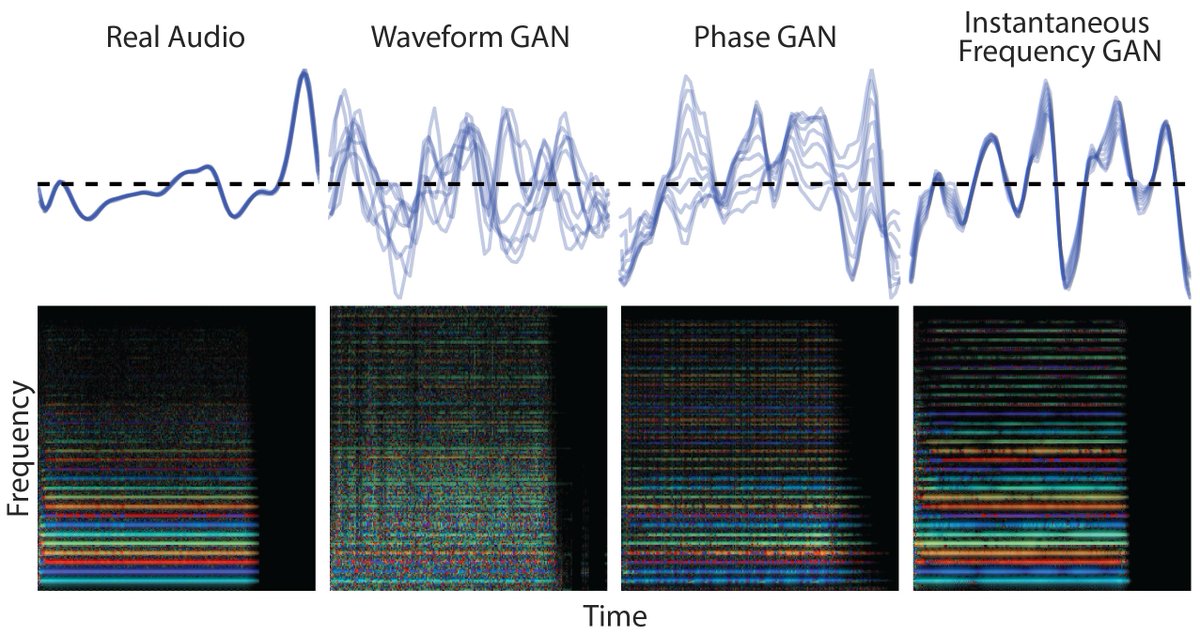
2/ tl; dr: We show that for musical instruments, we can generate audio ~50,000x faster than a standard WaveNet, with higher quality (both quantitative and listener tests), and have independent control of pitch and timbre, enabling smooth interpolation between instruments.

3/ We explore a range of architectures and audio representations and find that the best results come from generating in the spectral domain, with large FFT sizes to allow for better frequency resolution (H) and generating the instantaneous frequency (IF) instead of phase directly

3/ Why? Directly generating waveforms with GANs is tough because our ears are very sensitive to discontinuities in highly periodic audio. Both upsampling convolution and STFTs generate audio in chunks. For coherent waveforms, you need to line up the phase variations perfectly.
4/ This figure shows this effect, where each frame (dotted vertical line) moves at a different rate than the signal (black dot), leaving a phase difference (bold black line) that precesses.

5/ By unrolling the phase, and taking the finite difference, we get a constant value (Instantaneous Frequency) for a constant difference between the audio periodicity and frame periodicity, as is often seen in the highly periodic waveforms of music.


6/ Unlike previous audio models like WaveNet Autoencoders, we learn a single latent vector for the entire audio clip, and add a pitch conditioning vector. This results in smoother interpolations where each point sounds like a valid sample in its own right.

7/ There still is some work left to handle variable length sequences, and audio in more domains, but hopefully this is a significant step in that direction.
I'm excited to finally release this code, have fun making your own sounds with the colab notebook!
I'm excited to finally release this code, have fun making your own sounds with the colab notebook!
8/ Had a great time collaborating on this work with @kumarkagrawal, Shuo Chen, @__ishaan, @chrisdonahuey, @ada_rob, and @rifasaurousrex
9/ I also hope this inspires GAN researchers to play around more with audio. Fun note: the NSynth dataset (magenta.tensorflow.org/datasets/nsynth) was designed to mirror CelebA pretty closely (aligned, cropped, attribute labels, focus on one object, dataset size). Similar tradeoffs too.