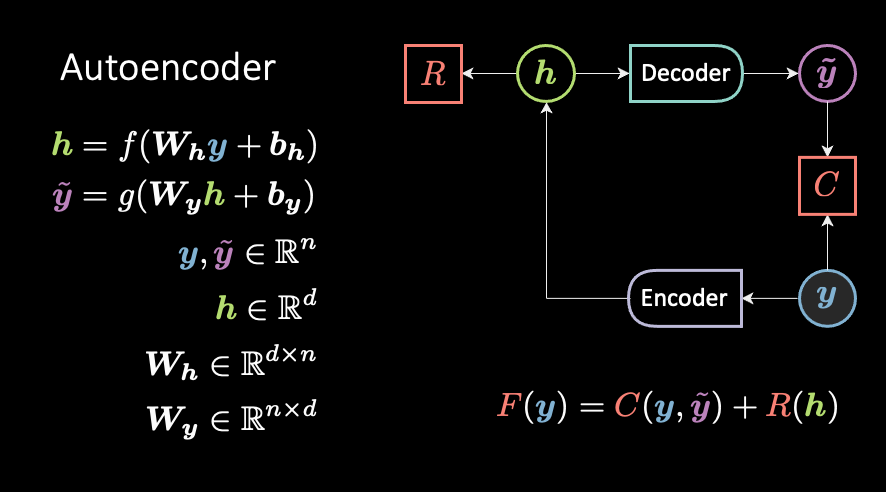
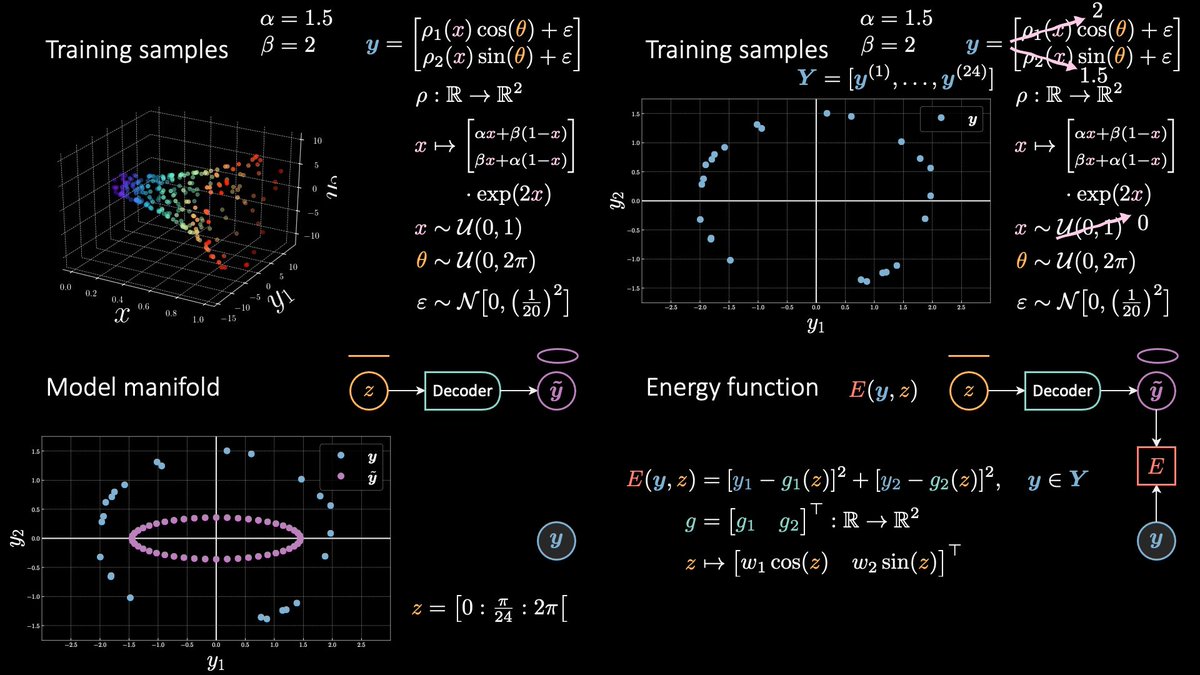
The fourth episode (of five) of the energy 🔋 saga is out! 🤩
From LV EBM to target prop(agation) to vanilla autoencoder, and then denoising, contractive, and variational autoencoders. Finally, we learn about the VAE's bubble-of-bubbles interpretation.

From LV EBM to target prop(agation) to vanilla autoencoder, and then denoising, contractive, and variational autoencoders. Finally, we learn about the VAE's bubble-of-bubbles interpretation.




Edit: updating a thumbnail and adding one more.
In this episode I *really* changed the content wrt last year. Being exposed to EBMs for several semesters now made me realise how all these architectures (and more to come) are connected to each other.
In this episode I *really* changed the content wrt last year. Being exposed to EBMs for several semesters now made me realise how all these architectures (and more to come) are connected to each other.


In the companion lecture (which will soon come online), @ylecun goes over a more powerful interpretation of VAE, which I still struggle to understand. As you can imagine, another tweak to my deck will occur when I'll actually get it. (Yeah, I'm slow, yet persistent.)
In this lesson you'll also learn the step-by-step solution to ⁂ Quiz #5 ⁂. A powerful tool to add to your portfolio of useful architectures. More precisely, if it's hard to get it in one go, break it down in smaller chunks.
https://twitter.com/alfcnz/status/1387862030749667340
Moreover, you will also find the solution to ⁂ Quiz #3 ⁂. In case you haven't seen these before, I highly recommend trying them out *before* watching this episode. Struggling a little and engaging in critical thinking will be highly beneficial for you.
https://twitter.com/alfcnz/status/1384545631885213706
• • •
Missing some Tweet in this thread? You can try to
force a refresh