The fifth episode (of five) of the energy 🔋 saga is out! 🤩
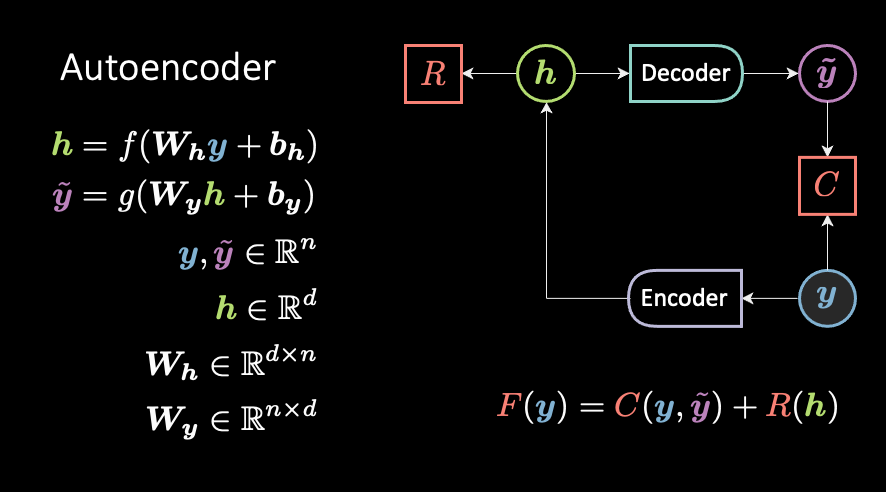
In this last episode of the energy saga we code up an AE, DAE, and VAE in @PyTorch. Then, we learn about GAN, where a cost net C is trained contrastively with samples generated by another net.

In this last episode of the energy saga we code up an AE, DAE, and VAE in @PyTorch. Then, we learn about GAN, where a cost net C is trained contrastively with samples generated by another net.




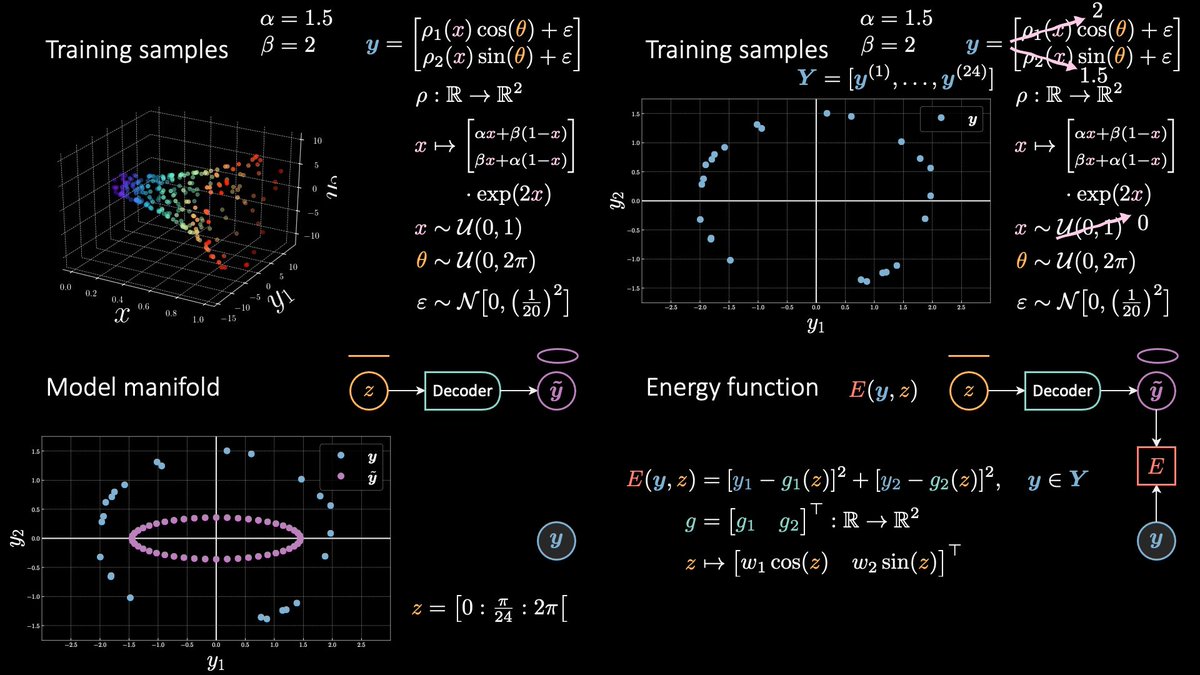
A GAN is simply a contrastive technique where a cost net C is trained to assign low energy to samples y (blue, cold 🥶, low energy) from the data set and high energy to contrastive samples ŷ (red, hot 🥵, where the “hat” points upward indicating high energy).
y comes from the data set Y.
ŷ is produced by the generating network G, which maps a random vector to the input space ŷ = G(z).
To train G we simply minimise C(G(z)).
And that's it.
No fooling around with discriminators. 🥸
It's *simply* contrastive energy learning. 😇
ŷ is produced by the generating network G, which maps a random vector to the input space ŷ = G(z).
To train G we simply minimise C(G(z)).
And that's it.
No fooling around with discriminators. 🥸
It's *simply* contrastive energy learning. 😇
Moreover, we compare and contrast DAE, VAE, and GAN, noticing similarities and differences.
They are *all* made of the *same* building blocks, like Lego™ blocks, but arranged in different configurations.
Check out the video to learn all the details! 😋
They are *all* made of the *same* building blocks, like Lego™ blocks, but arranged in different configurations.
Check out the video to learn all the details! 😋
Errata: in this video I managed to decouple the energy level from the “height” of the data point in consideration. In episode 2 I did get this mixed up, since the potential energy indeed is proportional to the height of a mass. But here things don't apply.
https://twitter.com/alfcnz/status/1382178290375520256
• • •
Missing some Tweet in this thread? You can try to
force a refresh