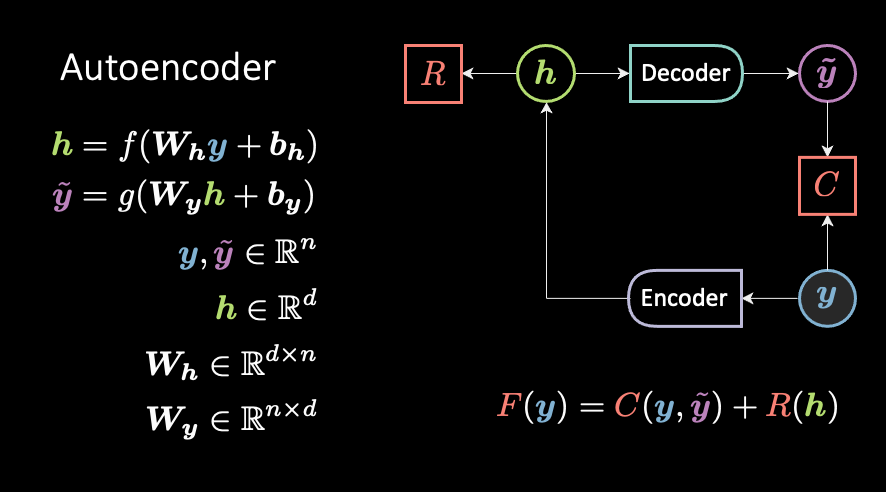
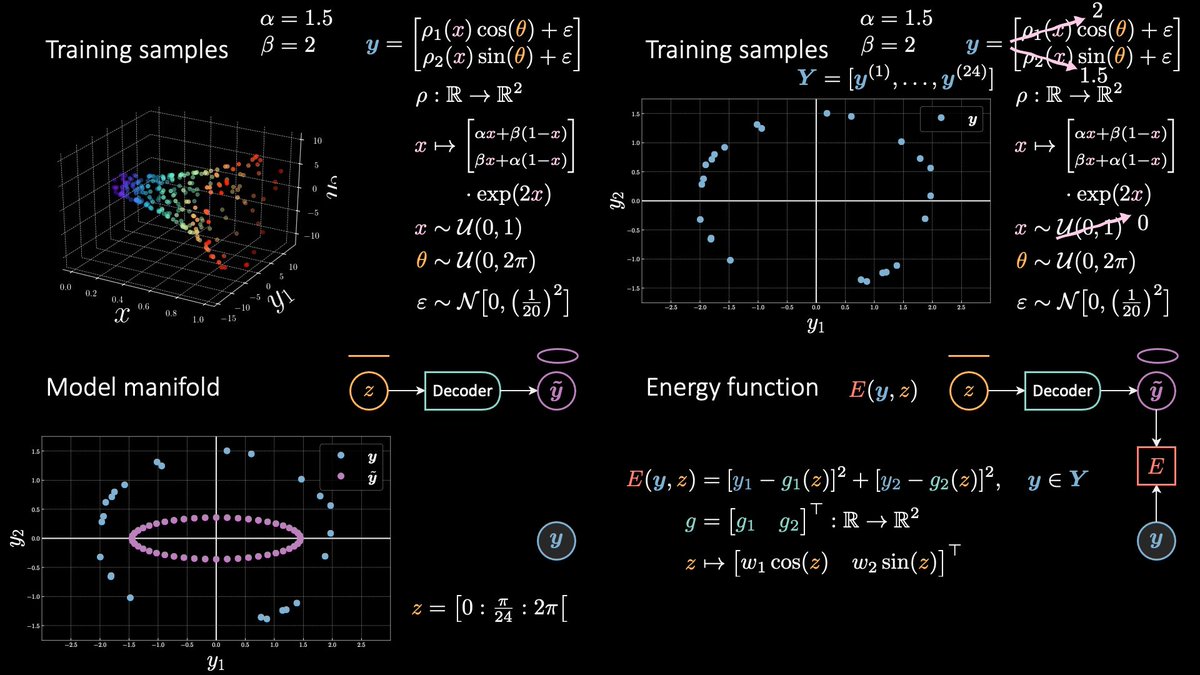
The energy 🔋 saga complete index ☝🏻
💜💚💜
Episode I
💜💚💜
Episode I
https://twitter.com/alfcnz/status/1379112137587630087
• • •
Missing some Tweet in this thread? You can try to
force a refresh