
If you want to predict clinical phenotypes using #MachineLearning, check out our systematic review on ML-based #sepsis prediction. A THREAD with take-aways that could be relevant to #AI in #healthcare in general. (--> = hints for practitioner) 1/n
bit.ly/34pIvRs
bit.ly/34pIvRs



1) Motivation: why should we even care about #sepsis? For decades clinicians have a) struggled to detect it in its early stages where organ damage is still reversible and b) failed to find a robust and early biomarker for sepsis. 2/n
--> Make sure that your problem (as well as your solution) *actually matters* (e.g., how is it helping doctors if you just foresee that a patient won't make it?) and ensure that it cannot be easily solved by conventional approaches.
3/n
3/n
2) Definition: ok, we know *why* we want to predict sepsis, but how do we define it's onset in the first place?
We find that various definitions (and modifications thereof) are implemented -- and this frequently without sharing the labelling code or even a description.
4/n
We find that various definitions (and modifications thereof) are implemented -- and this frequently without sharing the labelling code or even a description.
4/n


--> When your endpoint is based on a complex phenotype (not just 30d mortality),
i) report with great detail EVERY turn and decision you take for defining and implementing the endpoint; seemingly minor choices can impact the numbers by orders of magnitudes!
5/n
i) report with great detail EVERY turn and decision you take for defining and implementing the endpoint; seemingly minor choices can impact the numbers by orders of magnitudes!
5/n
ii) share the code for implementing and extracting the endpoint! For complex clinical endpoints, the "labelling pipeline" could be as large as (and more important than) the prediction pipeline itself! But most studies didn't make it available, adding little value to the lit.
6/n
6/n
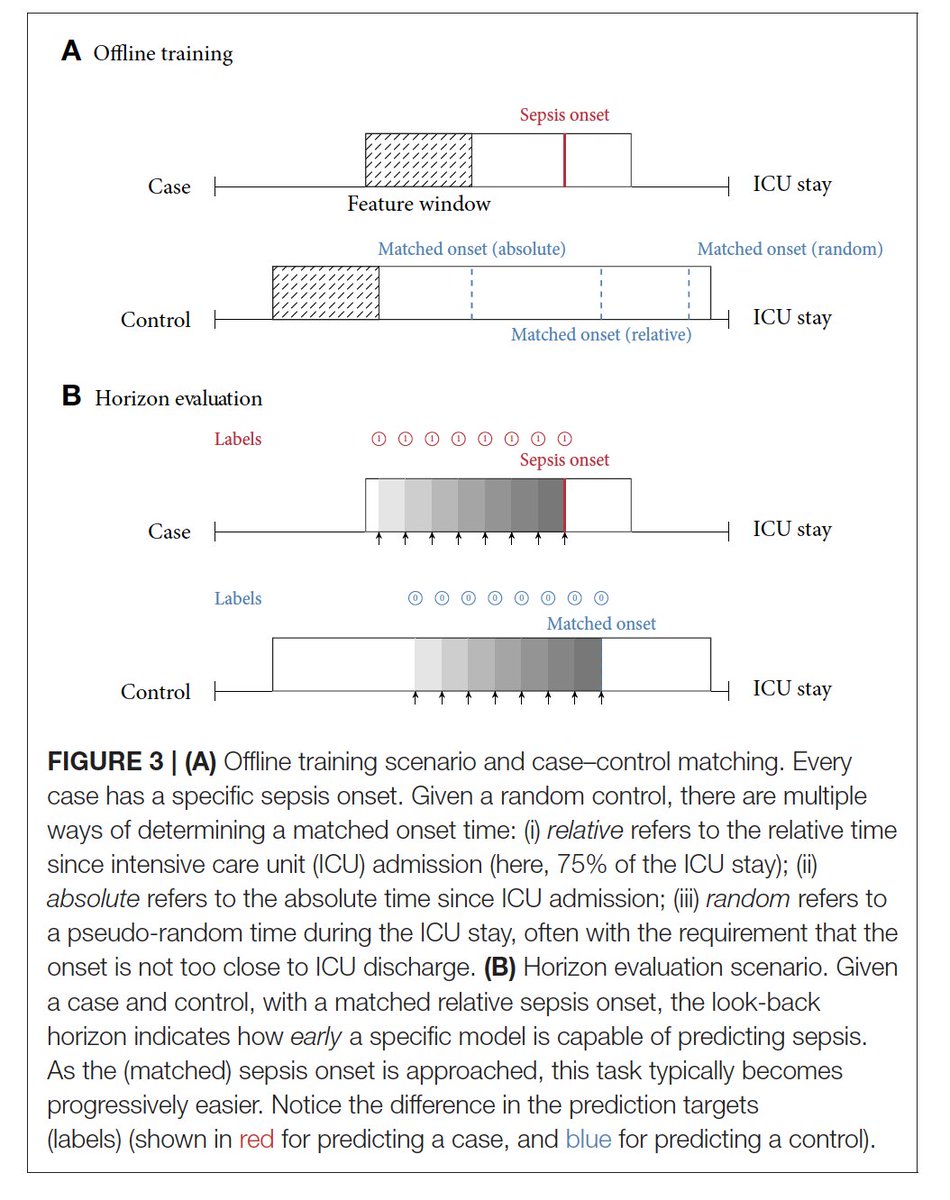
3) Task setup: how should our prediction task look like? For #sepsis onset, we find most studies frame it as a classification task by comparing time windows of cases before onset with "control windows". How control windows are defined is crucial, but often NOT reported. 7/
For instance, setting the matched "control onset" at the discharge made the task trivial leading to stellar AUROC measures, whereas matching random or comparable onset times makes it much harder (and the task more useful). Check this visualization for different control onsets: 8/

4) Comparability: The above points illustrate that it's currently not possible to determine a SOTA approach for predicting sepsis early. This actually matters a lot, as in prospective RCTs we cannot afford to send 50 "horses" into the race, but only the best.
9/
9/
Thus, in retrospective analyses it should be *the* virtue to aim for comparability that allows for collective learning and informed prospective studies.
Furthermore, in the paper we also cover further crises of the field like reproducibility and even circularity!
10/
Furthermore, in the paper we also cover further crises of the field like reproducibility and even circularity!
10/
To conclude, I would like to thank my amazing co-authors @Pseudomanifold, @ExpectationMax, @Jutzeler_Cathy and @kmborgwardt!
11/11
11/11
PS: gonna tag some experts and idols in the field who I hope may find this thread worthwhile:
@kdpsinghlab @MarkSendak @FinaleDoshi @EricTopol @suchisaria @kat_heller @DaniCMBelg @RoxanaDaneshjou
#tech #MedTwitter #AI #aihealth
#AcademicTwitter @AcademicChatter
@kdpsinghlab @MarkSendak @FinaleDoshi @EricTopol @suchisaria @kat_heller @DaniCMBelg @RoxanaDaneshjou
#tech #MedTwitter #AI #aihealth
#AcademicTwitter @AcademicChatter
• • •
Missing some Tweet in this thread? You can try to
force a refresh


