
Does your diff-in-diff treatment variable turn on at different times? Of course! Most of them do!
nber.org/papers/w25018
Very happy to share my paper showing how DD with variation in treatment timing works and what that means in theory and practice. 1/29
nber.org/papers/w25018
Very happy to share my paper showing how DD with variation in treatment timing works and what that means in theory and practice. 1/29

So…
Maybe there are untreated units and units treated at different times.
Maybe you ONLY have variation in timing (ie. everyone winds up treated).
Essentially your data look like this: 2/29
Maybe there are untreated units and units treated at different times.
Maybe you ONLY have variation in timing (ie. everyone winds up treated).
Essentially your data look like this: 2/29

We add “two-way fixed effects” for units and times to our regression. But what comparisons actually get made in this case? Where did the elegant DD expression in terms of sample means go? 3/29

We *could* pull out 4 simple “2x2” DDs this kind of set up:
1.Early vs Untreated
2.Late vs Untreated
3.Early vs Late before the late group turns on
4.Late vs Early after the early group turns on
Each of these is easy: treat/control/pre/post. We’ve understood them since 1855. 4/29
1.Early vs Untreated
2.Late vs Untreated
3.Early vs Late before the late group turns on
4.Late vs Early after the early group turns on
Each of these is easy: treat/control/pre/post. We’ve understood them since 1855. 4/29

Turns out that the TWFE DD coefficient is a weighted average of all 2x2 DD’s you could form.
Betas = 2x2 DDs
Weights = sample shares (the n’s) times treatment variances (the D-bars)
We have our expression in terms of means back! 5/29
Betas = 2x2 DDs
Weights = sample shares (the n’s) times treatment variances (the D-bars)
We have our expression in terms of means back! 5/29

Why variances?
B/c we use least *squares*! High var terms get more weight, just like Wald/IV theorem, “saturate and weight”, pooled OLS avgs w/in and b/w estimators, one-way FE: doi.org/10.1515/jem-20…...
The tool (OLS) shapes the result (variance weighting). 6/29
B/c we use least *squares*! High var terms get more weight, just like Wald/IV theorem, “saturate and weight”, pooled OLS avgs w/in and b/w estimators, one-way FE: doi.org/10.1515/jem-20…...
The tool (OLS) shapes the result (variance weighting). 6/29
What does this mean? Lets start with theory:
The y-bar parts make it easy to plug potential outcomes into each 2x2 DD, which we already know = ATT + differential trends (for the relevant “treatment” group and the relevant periods, which vary across terms). 7/29
The y-bar parts make it easy to plug potential outcomes into each 2x2 DD, which we already know = ATT + differential trends (for the relevant “treatment” group and the relevant periods, which vary across terms). 7/29

Knowing the weights lets us to map our understanding of the 2x2 estimand (an ATT) and ID assumption (pairwise commons trends) to the full TWFE case. 8/29
For example: at best regression DD = variance-weighted average of ATTs; NOT the overall ATT.
Treated in the middle of the data-->more weight than your sample share
Treated at the ends-->less weight than your sample share
9/29
Treated in the middle of the data-->more weight than your sample share
Treated at the ends-->less weight than your sample share
9/29
Interpretation depends on:
Selection on gains: do early groups have biggest/smallest effects?
+
Data structure: do early groups have biggest/smallest variances?
DD could be too big, too small, or just fine!
(def see @pedrohcgs & Callaway on this: ssrn.com/abstract=31482…) 10/29
Selection on gains: do early groups have biggest/smallest effects?
+
Data structure: do early groups have biggest/smallest variances?
DD could be too big, too small, or just fine!
(def see @pedrohcgs & Callaway on this: ssrn.com/abstract=31482…) 10/29
Other good recent papers show a version of this, too:
scholar.harvard.edu/files/borusyak…
arxiv.org/abs/1804.05785…
sites.google.com/site/clementde…
antonstrezhnev.com/s/generalized_…
nber.org/papers/w24963
Knowing that the weights come from variances explains why these issues arise. 11/29
scholar.harvard.edu/files/borusyak…
arxiv.org/abs/1804.05785…
sites.google.com/site/clementde…
antonstrezhnev.com/s/generalized_…
nber.org/papers/w24963
Knowing that the weights come from variances explains why these issues arise. 11/29
A much worse issue comes when effects vary over time. The treatment effects themselves put already treated units on a differential trend. The 2x2 DD’s that use already-treated units as controls are totally wrong and usually even wrong-signed! This will bias the whole thing. 12/29
I also show what “common trends” (approximately) means with timing. This was confusing before. Did we need common trends between early/late groups? Treated/untreated groups? Both? 13/29
Suppose group k is trending up. Terms where it’s the treatment group are biased up, but terms where it’s the control group are biased down. The difference in weight on these two things shows how group k’s trend feeds through to the overall DD estimator. 14/29

Some groups get 0 weight: bias perfectly cancels out across their 2x2 DDs.
Low-treatment-variance groups get more weight as controls than treatments.
When everyone eventually gets treated, this always happens. In fact, this defines “the control group” in these models! 15/29
Low-treatment-variance groups get more weight as controls than treatments.
When everyone eventually gets treated, this always happens. In fact, this defines “the control group” in these models! 15/29

This also shows how to test balance in a DD with timing. This is better than testing:
(a) joint balance across all groups (low power)
(b) x-sec and timing balance separately (they both contribute)
(c) linear relationship b/w x’s and timing (misses that hump-shape)
16/29
(a) joint balance across all groups (low power)
(b) x-sec and timing balance separately (they both contribute)
(c) linear relationship b/w x’s and timing (misses that hump-shape)
16/29

To see how to use all this, I replicate @betseystevenson and @justinwolfers (2006):
doi.org/10.1093/qje/12…
37 states did divorce reforms in the 70s/80s; 14 didn’t. Perfect for TWFE DD. I easily match their result that unilateral divorce D female suicide: 17/29
doi.org/10.1093/qje/12…
37 states did divorce reforms in the 70s/80s; 14 didn’t. Perfect for TWFE DD. I easily match their result that unilateral divorce D female suicide: 17/29



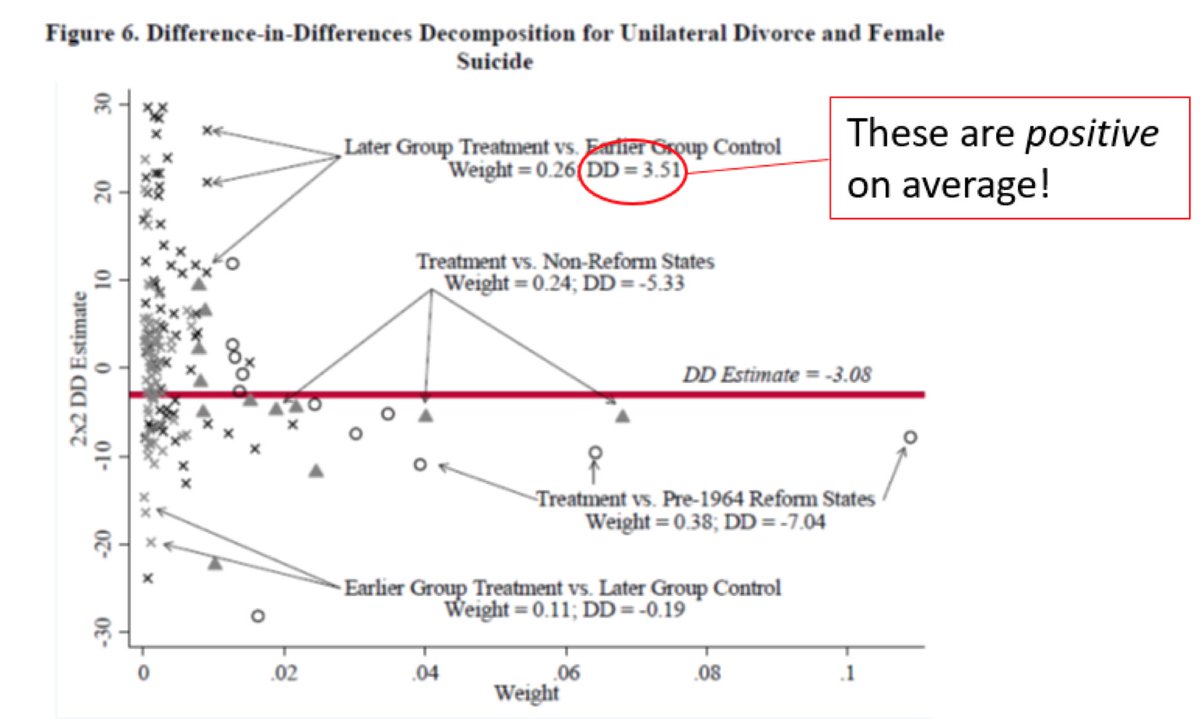
It is easy to see exactly where the DD estimate of -3.08 comes from. Just plot each 2x2 against its weight. DD estimate = the y-axis weighted by the x-axis. 18/29

How much variation comes from different sources?
Sum of weights on treated/untreated DDs 62% from treated/untreated variation (38% vs. pre-1964 reform states, 24% vs. non-reform).
Sum of weights DDs comparing 2 timing groups 37% from “timing” variation.
19/29
Sum of weights on treated/untreated DDs 62% from treated/untreated variation (38% vs. pre-1964 reform states, 24% vs. non-reform).
Sum of weights DDs comparing 2 timing groups 37% from “timing” variation.
19/29
Remember those time-varying treatment effects? The decomposition plot shows that they bias the DD estimate specifically because terms that use an already-treated control group are wrong-signed! 20/29
Any paper w/ an event-study like this will have DD estimates that are too small (or even wrong-signed). Maybe this has happened to you? great event-study, totally screwed up DD coef. Once you see it you can’t unsee it. 21/29
I also test balance. Comparing EVERY timing group is too noisy to detect imbalance in p.c. income. But noisy balance tests are bad. The reweighted test does better: treatment states (weighted by their contribution in the estimator) are richer than control states. 22/29

Finally, we can learn *why* DD estimates differ across specifications. This can come from the 2x2 DD’s, the weights, or a combination. That’s exactly a Oaxaca-Blinder-Kitagawa decomposition! (@mzgrosz, @shenhav_n, and Doug Miller do this for family FE) 23/29

Weighting by population, for example, changes the unilateral divorce estimates a lot (-3.08-0.35). But about 40% of that just comes from changing the weights on different 2x2 DD’s. That’s not really bias, that’s changing the estimand. 24/29
50% comes from changes in the DD’s, though. Easy to see which terms drive this by scattering the 2x2 DDs from OLS vs WLS.
The biggest changes involve the 1970 states: IA and CA. Clearly weighting matters for CA and CA matters a lot (nber.org/papers/w16773). 25/29
The biggest changes involve the 1970 states: IA and CA. Clearly weighting matters for CA and CA matters a lot (nber.org/papers/w16773). 25/29

I do this for: p-score weighting, DDD, unit-specific time trends (which are bad), partialling out pre-trends only (which is better), and disaggregated time FE. The decomp + scatter plots shed light on WHY estimates differ, which may or may not indicate a problem. 26/29
So that’s it. I love talking about this and I’ve been working on some version of it for a very long time. Here is an email from 2010, when this work was just a set of notes for myself, where I am embarrassingly confident in an untrue result. 27/29

This also spans influences going back years. Sarah West @macalester, Bitler/@gelbach/Hoynes (aeaweb.org/articles?id=10…), @martha_j_bailey (more than anyone else), John DiNardo, Gary Solon, @pedrohcgs…many more. Thank you! 28/29
In sum, I’ll probably keep doing TWFE DD, but now I know more about how to do it and what it means. @laura_tastic said it best: "diff-in-diff with caution, friends" 29/29
Bummed that this gif was so fuzzy. Maybe this is clearer.











