
Our new #Corl18 paper:
How curiosity-driven autonomous goal setting enables to discover
independantly controllable features of environments
pdf: arxiv.org/abs/1807.01521
Blog: openlab-flowers.inria.fr/t/discovery-of…
Colab: colab.research.google.com/drive/176q8pns…
#machinelearning #AI #NeuralNetworks
How curiosity-driven autonomous goal setting enables to discover
independantly controllable features of environments
pdf: arxiv.org/abs/1807.01521
Blog: openlab-flowers.inria.fr/t/discovery-of…
Colab: colab.research.google.com/drive/176q8pns…
#machinelearning #AI #NeuralNetworks
Imagine a robot perceiving a scene through low-level pixels.
It has no prior knowledge of its body (it only knows it can send numerical
numbers as motor commands that produce unknown movements of unknow body parts)
It has no prior knowledge of its body (it only knows it can send numerical
numbers as motor commands that produce unknown movements of unknow body parts)

It also does not know that the scene is composed of "objects". Yet, around it there are several objects: some of them can be controlled, others not (distractors)
How could it discover and represent entities, and find out which ones are controllable (and learn to control them)?
How could it discover and represent entities, and find out which ones are controllable (and learn to control them)?
How to maximize the diversity of controllable effects?
This problem can be approached within the Intrinsically Motivated Goal Exploration framework (IMGEPs)
It is an alternative to reinforcement learning, in the sense that it does not pre-suppose there are external scalar rewards coming from the outside world. Not even sparse ones.
It is an alternative to reinforcement learning, in the sense that it does not pre-suppose there are external scalar rewards coming from the outside world. Not even sparse ones.
Reinforcement learning vs. Intrinsically motivated goal exploration processes


In IMGEPs, agents imagine their own goals (and their own associated cost functions).
Pursuing them makes them use and improve their internal world model, leveraging forms of counterfactual learning.
Pursuing them makes them use and improve their internal world model, leveraging forms of counterfactual learning.
As agents make experiments to learn how to control the world (achieve self-generated goals) through their action interventions, IMGEPs is a framework pushing them to learn the causal structures of the body-environment ecosystem.
In IMGEPs, goals are not simply black-box reward functions to be maximized, but target properties of sensorimotor trajectories embedded in a parametric goal space: this enables to represent and leverage similarities among goals to learn faster, with hindsight, and to generalize
Also, goals are not necessarily target "end states" of an action policy, they can be dynamical properties of a full trajectory, e.g. as needed when learning to produce speech sounds
(e.g. frontiersin.org/articles/10.33… )
(e.g. frontiersin.org/articles/10.33… )
As the agent does not know in advance which goals are easy or difficult, and the space of goals may be large, it is useful to sample goals in an organized manner.
One way to do it is sampling goals in parts of the goal space for which the learner expects high learning progress.
One way to do it is sampling goals in parts of the goal space for which the learner expects high learning progress.
In a series of previous papers, we showed that such mechanisms can enable agents to learn diverse repertoire of skills in high-dimensional continuous state and action spaces, including in real world robots, showing their high sample efficiency.
e.g.
e.g.
Such mechanisms were also shown to reproduce major self-organized developmental stages in infant development, ranging from
vocalizations: frontiersin.org/articles/10.33…
to the discovery of tool use: sforestier.com/sites/default/…
vocalizations: frontiersin.org/articles/10.33…
to the discovery of tool use: sforestier.com/sites/default/…
However, in these previous papers the space in which agents sampled goals was based on a representation hand-defined by human engineers (e.g. it encoded directly the position and speed of individual objects in a scene)
Here, agent A first observe passively their environment, where one assume another skilled agent B (e.g. a human) is producing various effects.
Agent A then uses a Beta-VAE to learn a disentangled representation of the distribution of scenes. This enables to identify latent variables corresponding to key properties of separate objects.
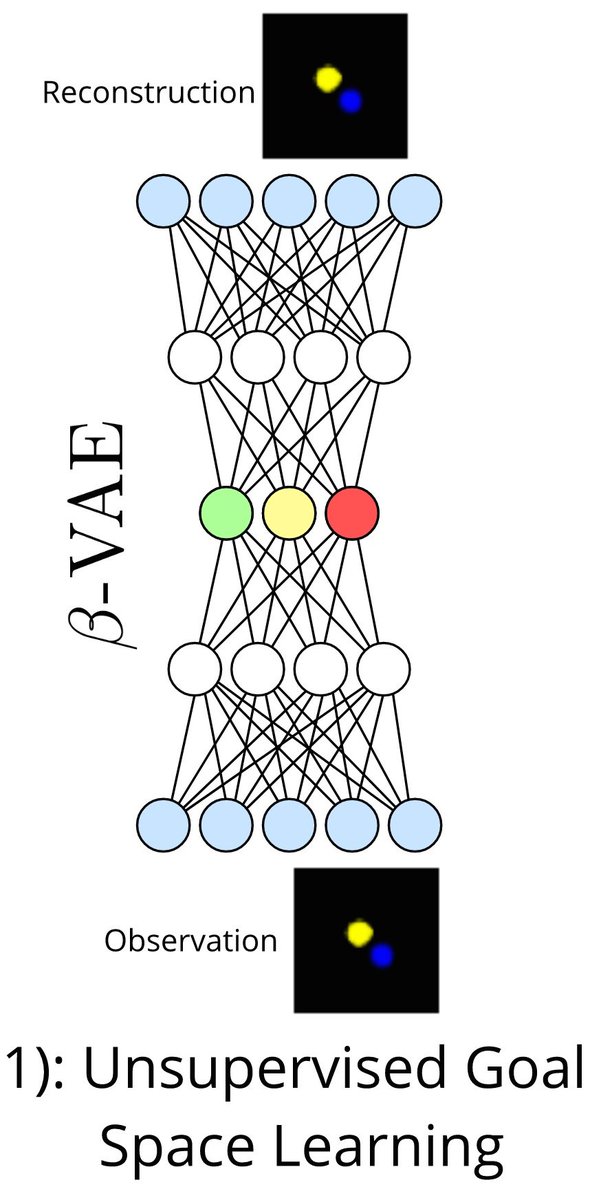
This learnt latent space may encode disentangled features of the environment, but this encoding is still at this stage independant of the action repertoire. Some latents may correspond to uncontrollable moving distractors, but the agent initially does not know.
Thus, in a second phase the agent sample goals in sub-spaces of this global latent goal embedding, e.g. it imagines target values of single latent dimensions, or couples of dimensions.

For each of the sub-spaces/latent dimension, the agent monitors its progress at learning how to control them with its own actions. This learning progress is used to organize exploration: goals in sub-spaces with high learning progress are sampled more frequently.
This first enables the self-organization of a learning curriculum: the agent first focuses on easy goals/sub-spaces, then progressively moves to more complicated ones, avoiding both too easy and too difficult ones.
Second, this enables to identify which features of the environment are independantly controllable: these are the disentangled dimensions where learning progress has been observed! Latents corresponding to uncontrollable distractors can now be discarded for further learning.
The outcome of this architecture is:
1) a learnt set of independantly controllable features
2) a world model enabling to predict and control controllable variables
3) a diverse set of skills, enabling to achieve many kinds of goals
And all without a single external reward!
1) a learnt set of independantly controllable features
2) a world model enabling to predict and control controllable variables
3) a diverse set of skills, enabling to achieve many kinds of goals
And all without a single external reward!

Special thanks to Adrien Laversanne-Finot and Alexandre Péré for all the outstanding work! The blog for more info: openlab-flowers.inria.fr/t/discovery-of…

















