Hola amigos, hoy no es sábado sabadete pero toca hilo sobre #privacidad y #eticadelosdatos. Hoy, hablaremos del papel FUNDAMENTAL de la Calidad de los Datos en #MachineLearning y, por qué una baja calidad de éstos es causa de sesgos y discriminaciones.
La calidad de los datos juega un papel crítico en Machine Learning porque cada modelo de Machine Learning se entrena y se evalúa utilizando conjuntos de datos, y las características y calidad de estos conjuntos de datos influirán DIRECTAMENTE en el resultado de un modelo.
Una definición de "calidad de los datos" es si los datos utilizados son "adecuados para el propósito". En consecuencia, la calidad de los datos depende en gran medida del propósito de su uso.
¿Cuál es el causante de las discriminaciones y sesgos en las predicciones de un algoritmo? Varios motivos, pero uno de los motivos es la diferencia entre el contexto en el que las predicciones van a ser aplicadas y la calidad de los datos con los que el algoritmo se ha entrenado.
Estos desajustes pueden tener consecuencias MUY GRAVES cuando las predicciones a través de los algoritmos de Machine Learning se utilizan en contextos de alto riesgo como la justicia predictiva, la contratación de personal, las finanzas, los seguros, el reconocimiento facial.
De particular preocupación son los ejemplos recientes que muestran que los modelos de Machine Learning pueden reproducir, o amplificar, los sesgos sociales no deseados reflejados en los conjuntos de datos.
Los ejemplos de estos problemas incluyen son las discriminaciones en el género en las traducciones del lenguaje surgidas a través del procesamiento del lenguaje natural, discriminaciones del tono de la piel en los sistemas de reconocimiento facial debido a baja calidad de datos.
Como ejemplo, Amazon canceló el desarrollo de un sistema de contratación automatizado porque el sistema amplificó los prejuicios de género en la industria tecnológica. reuters.com/article/us-ama…
En este paper arxiv.org/pdf/1607.06520… se mostró que las incrustaciones en baja dimensión de palabras en inglés inferidas de artículos reproducen discriminaciones de género al completar: "el hombre es para el programador de ordenadores como la mujer para X" "ama de casa".
Los empleadores ahora usan sistemas similares para elegir a sus empleados, monitorizando su actividad para mantenerlos productivos, sanos y prediciendo su fracaso, éxito, renuncia o, incluso, suicidio, de modo que puedan tomar los primeros pasos para mitigar los riesgos.
La Tecnología de Reconocimiento Facial está más que en tela de juicio por las discriminaciones que produce. @jovialjoy en este vídeo explica cómo el software de reconocimiento facial no reconoce su cara por ser mujer de raza negra.
@jovialjoy A su vez, @jovialjoy y Gebru en el paper proceedings.mlr.press/v81/buolamwini… encontraron que 3 empresas que desarrollan Tecnología de Reconocimiento Facial reconocían casi al 100% a hombres de raza blanca. Mientras que las tasas de error para las mujeres de piel más oscura llegaban al 33%.
@jovialjoy La discriminación en la toma de decisiones algorítmicas basadas en datos puede ocurrir debido a varias razones:
La discriminación puede ocurrir durante el diseño, prueba e implementación de algoritmos a través de sesgos que se incorporan, conscientemente, o no, en el algoritmo.
La discriminación puede ocurrir durante el diseño, prueba e implementación de algoritmos a través de sesgos que se incorporan, conscientemente, o no, en el algoritmo.
@jovialjoy Si existen diferencias en el rendimiento de un algoritmo, generalmente es muy difícil y, a veces, imposible eliminar el sesgo a través de soluciones matemáticas o programáticas.
@jovialjoy Una causa IMPORTANTE de la discriminación es la CALIDAD DE LOS DATOS utilizados para desarrollar algoritmos y software.
@jovialjoy Siguiendo con el software de Reconocimiento Facial, para ser efectivo y preciso, este software necesita ser alimentado con grandes cantidades de imágenes faciales. Más imágenes faciales conducen, en principio, a predicciones más precisas.
@jovialjoy Sin embargo, la precisión no solo está determinada por la CANTIDAD de imágenes faciales procesadas sino también por la CALIDAD de tales imágenes faciales. La calidad de los datos requiere también un conjunto representativo de rostros que reflejen diferentes grupos de personas.
@jovialjoy Pero, como dijimos antes, hasta la fecha, las imágenes faciales utilizadas para desarrollar algoritmos en el mundo occidental a menudo representan en exceso a los hombres blancos, con un menor número de mujeres y / o personas de otros orígenes étnicos.
@jovialjoy La medición de la vida a través de algoritmos significa que se pueden hacer predicciones, clasificaciones y decisiones sobre las personas basadas en modelos algorítmicos formados en grandes conjuntos de datos de tendencias históricas.
@jovialjoy El riesgo de mal uso involuntario del conjunto de datos aumenta cuando los desarrolladores no son expertos, ya sea en el Machine Learning o en el dominio donde se utilizará el Machine Learning.
@jovialjoy Esta preocupación es particularmente importante debido a la mayor prevalencia de herramientas que "democratizan la Inteligencia Artificial" al proporcionar un fácil acceso a conjuntos de datos y modelos para uso general.
@jovialjoy Y, justo por este motivo, es TAN IMPORTANTE que las organizaciones que usan algoritmos predictivos documenten la PROCEDENCIA, la CREACIÓN y el USO de conjuntos de datos, como primer paso, para evitar resultados discriminatorios.
@jovialjoy Pero, a pesar de la importancia de los datos para el Machine Learning, no existe un proceso estandarizado para documentar conjuntos de datos de aprendizaje automático. De hecho, es un proceso del que se habla muy poco.
@jovialjoy Además, los algoritmos de clasificación y puntuación también plantean desafíos en términos de su complejidad, opacidad y sensibilidad a la influencia de los datos.
@jovialjoy Los desarrolladores de modelos se enfrentan a dificultades para interpretar un algoritmo y sus resultados de clasificación, y esta dificultad se agrava aún más cuando el modelo y los datos sobre los que se entrena son propietarios o confidenciales, como suele ser el caso.
@jovialjoy Pero, ¿cómo sería el proceso de toma de decisión de un algoritmo? Está muy bien explicado en el paper: “The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards” arxiv.org/pdf/1805.03677… con el siguiente diagrama, y de la siguiente manera: 
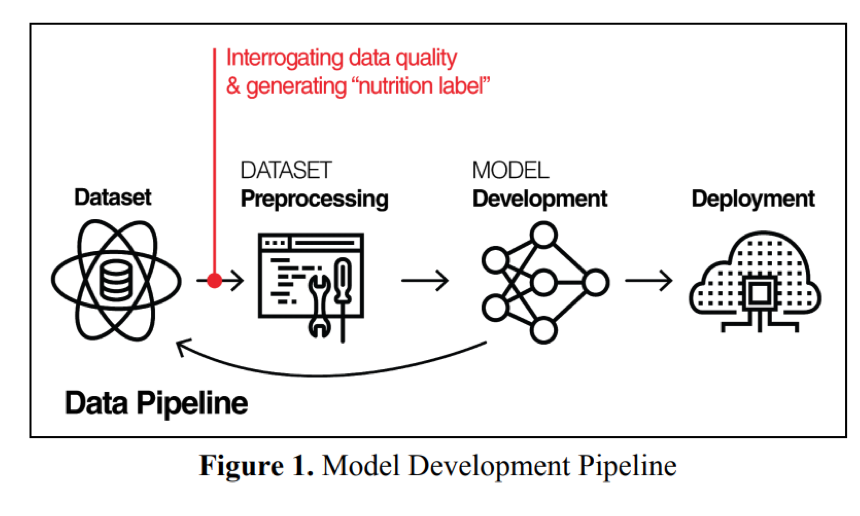
@jovialjoy Todo empieza con una pregunta u objetivo. Se selecciona un conjunto de datos etiquetados de RESPUESTAS ANTERIORES para que dé respuesta a la pregunta orientadora.
@jovialjoy Y estos datos, queridos amigos, se usan para entrenar el algoritmo, para que éste responda a la pregunta formulada, que puede ser desde identificar a individuos a través de tecnología de reconocimiento facial, predecir la personalidad de un candidato en un vídeo de 30 segundos...
@jovialjoy Puntuar el riesgo de impago de un grupo de individuos que viven en un código postal determinado, o predecir el riesgo de reincidencia criminal, o predecir cuándo un usuario se va a morir, o predecir si tiene riesgo de sufrir una depresión o de cometer suicidio…
@jovialjoy De esta manera, las RESPUESTAS PASADAS (o del pasado) se utilizan para PREDECIR LAS RESPUESTAS DEL FUTURO. Esto es MUY GRAVE cuando respuestas pasadas están contaminadas con sesgos y se le suma la dudosa capacidad de los algoritmos para predecir comportamientos y acontecimientos.
@jovialjoy Los modelos a menudo quedan bajo escrutinio (es decir, se revisan) pero sólo después de que se construyan, capaciten y desplieguen. Si se descubre que un modelo sigue repitiendo un sesgo o discriminación, se regresa a la etapa de desarrollo para identificar y abordar el problema.
@jovialjoy PROBLEMA: Este ciclo de retroalimentación no siempre mitiga el daño. El tiempo y la energía en realizar este escrutinio es CARÍSIMO y, si el algoritmo está en uso, ya pudo haber causado el daño que se querían evitar: discriminación por sexo, raza, edad, orientación sexual, etc.
@jovialjoy Otro gran problema que afecta a la calidad de los datos es la PROCEDENCIA de los mismos.
El fantasma de las redes sociales Y LO QUE COLGAMOS CADA DÍA... (hi! #Millennials y hi! a los no tan Millennials).
¿Por qué es un problema (problemón)?
El fantasma de las redes sociales Y LO QUE COLGAMOS CADA DÍA... (hi! #Millennials y hi! a los no tan Millennials).
¿Por qué es un problema (problemón)?
@jovialjoy Porque los datos de Internet sólo pueden reflejar un subconjunto de toda la población, lo que está relacionado con el acceso limitado a Internet . Y se usan para predecir comportamientos de toda la población.
@jovialjoy Muchas organizaciones usan datos de internet, como las compañías de seguros, que usan datos de las redes sociales para crear un sistema de puntuación de riesgo de clientes potenciales. Y sin comértelo ni bebértelo, te pueden meter en el mismo saco.
@jovialjoy Entre las empresas que utilizan Big Data, la fuente más importante son los datos de geolocalización, que son principalmente información sobre dónde están las personas y cómo se mueven, medidas a través de la información de sus móviles.
@jovialjoy El mismo paper afirma que, CADA SEGUNDO, las empresas que utilizan Big Data hacen uso de dichos datos (49%). Del mismo modo, el 45% del Big Data que utilizan las empresas es proveniente de redes sociales.
Y esto es GRAVÍSIMO. Y no podemos acceder a esa información.
Y esto es GRAVÍSIMO. Y no podemos acceder a esa información.
@jovialjoy Otras fuentes de datos incluyen dispositivos o sensores inteligentes de las empresas, que son utilizados por el 33% de todas las empresas que utilizan análisis de Big Data.
@jovialjoy Esto nos muestran que los datos de los móviles y redes sociales son FUENTES IMPORTANTES para el análisis de Big Data, que potencialmente pueden usarse para el desarrollo de algoritmos de aprendizaje automático y decisiones que afectan a nuestra vida personal.
@jovialjoy El uso de datos de Internet plantea muchas preguntas como: quién está incluido en los datos y en qué medida la información incluida es adecuada para su propósito.
@jovialjoy La aplicación de la ley de protección de datos a la cuestión de la calidad de los datos para construir tecnologías y algoritmos relacionados con la #InteligenciaArtificial no está nada clara.
@jovialjoy La ley de protección de datos ofrece una orientación mínima: el Principio de Exactitud de los datos en el RGPD está relacionado con la calidad de los datos, pero en un sentido muy limitado, ya que solo se centra en la obligación de mantener los datos personales actualizados.
@jovialjoy Llegados a este punto, ¿qué soluciones se podrían aportar?.
Como dije anteriormente, no hay una solución legal, pero sí se pueden plantear soluciones éticas como:
Como dije anteriormente, no hay una solución legal, pero sí se pueden plantear soluciones éticas como:
@jovialjoy 1. Evaluación del Impacto de los Derechos Fundamentales, para garantizar una aplicación de las tecnologías que cumpla con los derechos fundamentales, independientemente del contexto en el que se emplee. Dicha evaluación debe contemplar TODOS los derechos afectados.
@jovialjoy 2. Evaluación del Impacto de la Protección de Datos y Ética, CON TODAS LAS PARTES IMPLICADAS BIEN REPRESENTADAS.
@jovialjoy 3. Como manera de mitigar la opacidad de los algoritmos propietarios, que las organizaciones muestren la procedencia de los datos que han usado para entrenar su algoritmo y cuán adecuados son para su propósito.
@jovialjoy 4. Soluciones técnicas. Hay soluciones técnicas desarrolladas en estos papers (a modo de ejemplo): “Datasheets for datasets” arxiv.org/pdf/1803.09010… y “The Dataset Nutrition Label: A Framework To Drive Higher Data Quality Standards” arxiv.org/abs/1805.03677
@jovialjoy Y también recomiendo leer “El reto Big Data para la estadística pública” zenodo.org/record/1309185… de @algoya_dat que habla de la problemática de la calidad de los datos (en español).
@jovialjoy @algoya_dat Como siempre, gracias por leerme.