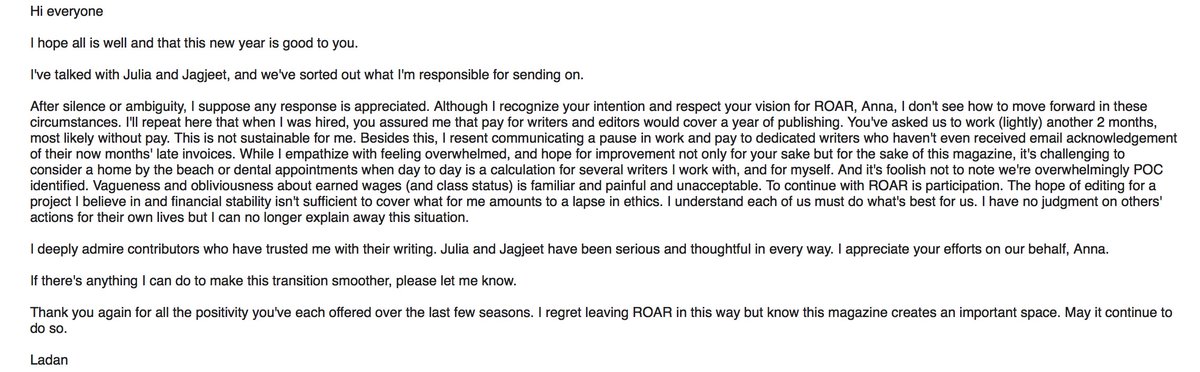
Very relevant. Thanks for sharing. If I end up going (trying to figure out my schedule), I'll let you know what I learned.
Example: google figuring out your genome
When google did this, they solved a very specific problem that made a lot of, potentially, sub optimal framing decisions
For example, you frame a problem on a particular way because it's familiar or you use a particular piece of software because you used it in the past
Data science is more computational. There are also some human decisions that led to the computation.
Theory: your estimates before you look at the data is different than your estimates after you look at the data
And this can be applied to every single step of the data science life cycle from developing the question to communicating the result
And how it relates to reproducibility of experiments
This is complicated because humans do crazy stuff to data. This might be the thesis of the talk
Explains the history of why we hate pie charts
And how can we apply that history to the entire data science process
For example 538 article where people estimated red card rate in soccer by race
Jeff used Coursera to get his data!
33499 repos on getting and cleaning data course
Most use dplyr. Overtime dplyr has grown a lot. Data table is third
They also did randomized experiments
Makes fun of himself for not using ggplot2
They randomly asked people to only use ggplot2 or base R in their experiment
Then they used peer grading to evaluate the plots
Results: ggplot2 is a bit better but it's basically the same. Small effect sizes
Let's apply this same technique to how they communicate results
When you do an inferential study but try to explain why the variables are related, people think it's a causal study
Another example, can people detect statistically significant scatter plots. Answer: no, but they get better with practice
Now onto modeling: how often do people feel pressured to find a result in a data set
Experiment: tell them that there is or isn't believed to be an effect, but give them a data set with or without a relationship
There were some weird results in this experiment
When you prime people there is a relationship, they are more likely to fit a model on that relationship
Lastly, can you prevent people from p-hacking?
Answer: probably not
Question: does this apply to phd students?
Answer: we don't know
There's a ROC curve for science (in terms of false positives of experiments). I'm perfectly comfortable with where we land. - Jeff
This was a fascinating take that I had never considered. Main argument: false positives are building blocks, not every experiment should be expected to be a phase III 10,000 human RCT