Deep reinforcement learning overfits. Often, a trained network can only play the particular level(s) you trained it on! In our new paper, we show how to train more general networks with procedural level generation, generating progressively harder levels.
arxiv.org/abs/1806.10729
arxiv.org/abs/1806.10729
The paper, written by @nojustesen @ruben_torrado @FilipoGiovanni @Amidos2006, me and @risi1979, builds on the General Video Game AI framework, which includes more than a hundred different games and lets you easily modify games and levels (and generate new ones).
We also build on ours and others' research on procedural content generation for games, a research field studying algorithms that can create new game content such as levels. Useful not only for game development but also for AI testing.
More on PCG:
pcgbook.com
More on PCG:
pcgbook.com
The level generators we use in our paper allow for generating levels for three different games, with different difficulty levels. So we start training agents on very simple levels, and as soon as they learn to play these levels well we increase the difficulty level. 
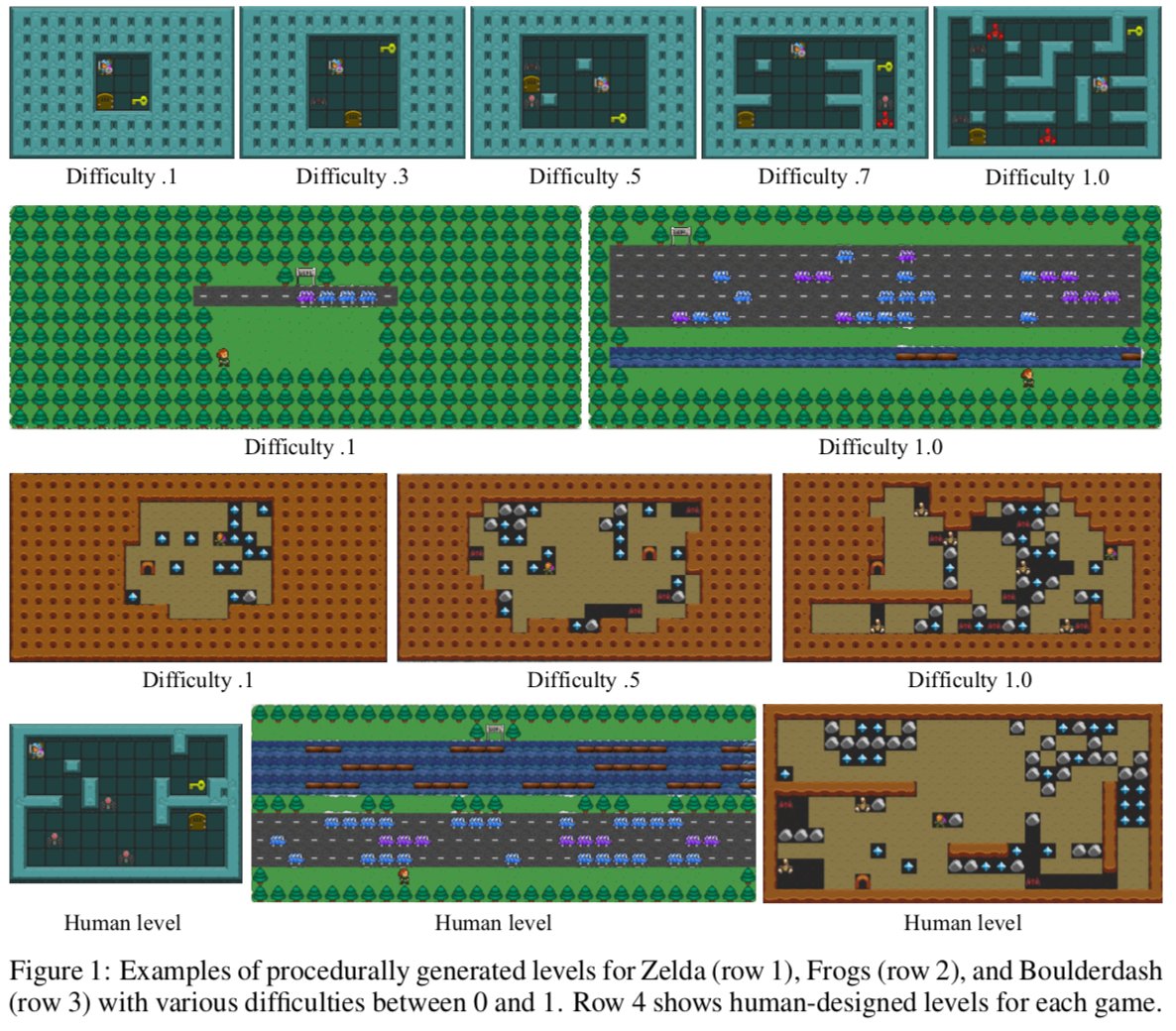
By training this way, we not only find agents that generalize better to unseen levels, but we can also learn to play hard levels which we could not learn to play if we started from scratch.


We are taking the old idea of increasing the difficulty as the agent improves, which has variously been called incremental evolution, staged learning and curriculum learning, and combining it with procedural content generation.
Our results point to the need for variable environments for reinforcement learning. Using procedural content generation when learning to play games seems to be more or less necessary to achieve policies that are not brittle and specialized.
When training on a single game with fixed, small set of levels, you are setting yourself up for overfitting. If your performance evaluation is based on the same set of levels, you are testing on the training set, which is considered a big no-no in machine learning (but not RL?).
In particular, this applies to the very popular practice of training agents to play Atari games in the ALE framework. Our results suggest that doing so encourages overfitting, and learning very brittle strategies.
In other words, reinforcement learning researchers - including but not limited to those working on games - should adopt procedural level generation as a standard practice. The @gvgai framework provides a perfect platform for this.
Our previous paper explaining the GVGAI learning track framework which we use for this research can be found here:
arxiv.org/abs/1806.02448
arxiv.org/abs/1806.02448