,
21 tweets,
9 min read
Read on Twitter
Multiplicty in Clinical Trial is really a disturbing issue for statisticians and trialists! (and for me😬)
b/c there is no consensus on multiplicity issue: When, Why and How to deal with it?
-I’ll try to explain by using *frequentist* point of view
1/
b/c there is no consensus on multiplicity issue: When, Why and How to deal with it?
-I’ll try to explain by using *frequentist* point of view
1/
Briefly, multiplicity is using many (multiple) comparisons. It increases the likelihood that a chance association could be deemed causal. In other words, we carry out multiple tests, it becomes highly likely that one of these tests will be significant by chance.
2/
2/
What is the source of multiplicity?
1-Multiple endpoints (i.e. death and death+HF rehosp)
2-Multiple treatments/arms (i.e. PCI vs Med-Tx vs CABG in pts with CAD or Riv15 mg vs Riv20 mg vs ASA)
3-Multiple interim analyses
4-Multiple subgroups
3/
1-Multiple endpoints (i.e. death and death+HF rehosp)
2-Multiple treatments/arms (i.e. PCI vs Med-Tx vs CABG in pts with CAD or Riv15 mg vs Riv20 mg vs ASA)
3-Multiple interim analyses
4-Multiple subgroups
3/
Look at example:
Assume we carryout single null hypothesis at alpha=0.05 >> the P of rejecting true null hypothesis 0.05
if we carryout 2 independant test, the probability of type-1 error increased from 0.05 to 0.10 >>the P of rejecting at least 1 true null hypothesis 0.10
4/
Assume we carryout single null hypothesis at alpha=0.05 >> the P of rejecting true null hypothesis 0.05
if we carryout 2 independant test, the probability of type-1 error increased from 0.05 to 0.10 >>the P of rejecting at least 1 true null hypothesis 0.10
4/

*So, in confirmatory trials, control of the type I error at a 2-sided 5% level is mandated by regulatories .
*btw, to avoid loss of validity due to inflating Type I error from insufficient control, simultaneously avoiding power loss by excessive Type II error from overcontrol
5/
*btw, to avoid loss of validity due to inflating Type I error from insufficient control, simultaneously avoiding power loss by excessive Type II error from overcontrol
5/
So.. We know that multiplicity is an important problem when running a clinical trial. Do we need multiplicty adjustment?
Some statisticians/trialists are againist it, however some advocate it.
6/
Some statisticians/trialists are againist it, however some advocate it.
6/
How to Deal with multiplicity
1-The simplest way is to avoid multiple comparison..
2-If multiplicity still persists
*Multiplicity adjustment should be considered
(depending on endpoints families, Tx arm, ......)
7/
1-The simplest way is to avoid multiple comparison..
2-If multiplicity still persists
*Multiplicity adjustment should be considered
(depending on endpoints families, Tx arm, ......)
7/
If you run a confirmatory RCT and there is related arms (ie different drug doses), multiplicity adjustment is generally needed.
8/
8/

If you have more than one primary endpoints multiplicity adj generally needed.
9/
9/

when co-PEP are tested, MA generally is not necessary because there is no opportunity to select the most favorable result from among several endpoints. The impact of multiplicity in these situations is to increase the Type II error rate (from FDA guidance for industry)
10/
10/
Generally, no need to adjust for multplicity in subgroup analyses.
11/
11/

All methods to deal with multiplicity are based on p value. Stepwise tests have more power than singlestep. Singlestep procedures tend to cause loss of power, so that sample sizes need to be increased in comparison to sample sizes needed for a single-endpoint study
12/
12/

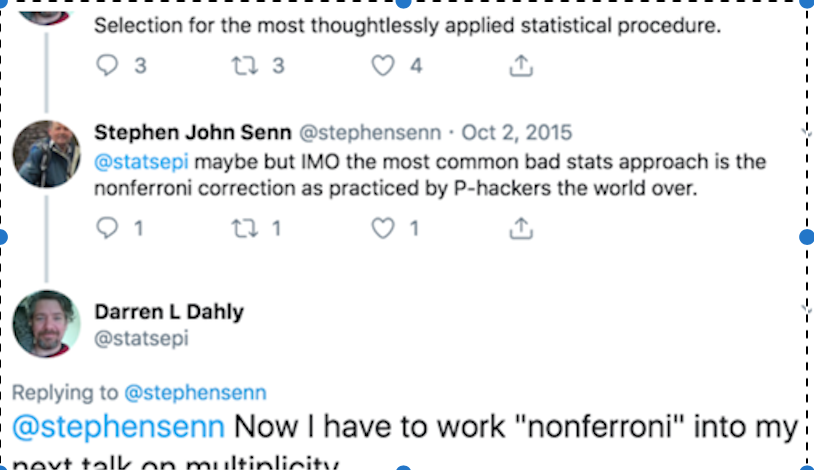
BTW, bonferrroni (or nonferroni😁) is the simplest and least useful methods in MA. Hierarchical procedures are mainly designed to deal with the issue with multiple endpoints.
nonferroni >> qutoted from @stephensenn, @statsepi
13/
nonferroni >> qutoted from @stephensenn, @statsepi
13/
macitentan 3 and 10 mg were compared to placebo >> α:0.01 and power 80%.To control overall α (0.01), the critical α for each comparison = 0.01/2 = 0.005. According to frequentist view, no sign difference between Maci3mg and placebo (p=0.01, higher than critical α of 0.005)
14/
14/

p-values are ordered from smallest to largest (0.03, <0.001, <0.001). Test begins by comparing smallest p-value (<0.001), to α/3 (0.017). p <0.001 is lower than 0.017, so considered sign. Then compares next-smallest p-value(<0.001) and so on until last p-value (0.03).
15/
15/

Hochberg starts with largest p-value, which is compared to the largest EP-specific critical value (α) (0.40 vs 0.05), this p-value is considered not significant. The procedure, however, continues to the second step.
16/
16/
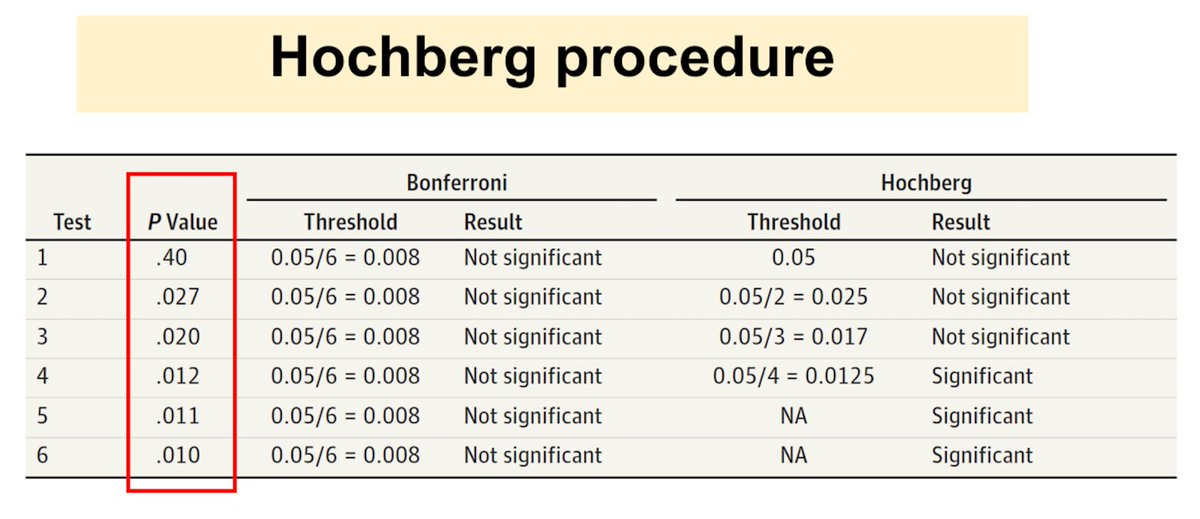
Hochberg;
In the second step, the second largest p-value, 0.027, is compared to α/2 = 0.025; this p-value is also not statistically significant. Test then compares the next-largest p-value(0.020) and so on until the last p-value (0.010).
17/
In the second step, the second largest p-value, 0.027, is compared to α/2 = 0.025; this p-value is also not statistically significant. Test then compares the next-largest p-value(0.020) and so on until the last p-value (0.010).
17/
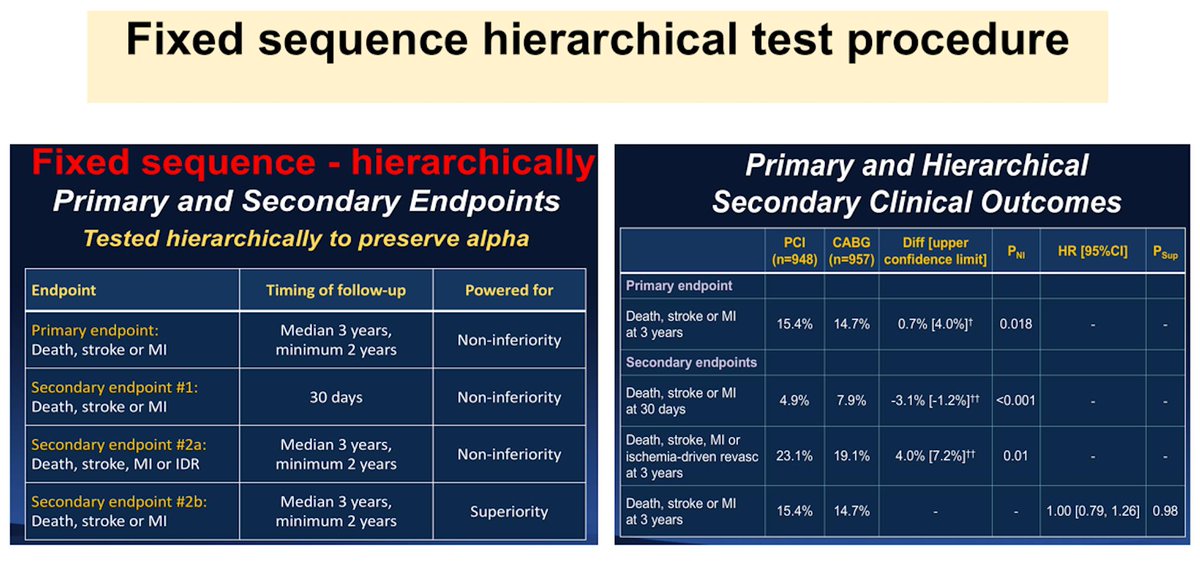
ODDYSEY-OUTCOME: To adjust for multiplicity, the results of the main secondary EP were to be tested in hierarchical fashion in the sequence listed in figure if the risk of the composite PEP was found to be significantly lower in alirocumab group than in placebo group.
19/
19/

Gatekeeping: (1) determine the order for testing multiple EP, considering their relative importance
and the likelihood that there is a difference in each; (2) test the first end point against the desired global false-positive rate (ie, .05)
20/
and the likelihood that there is a difference in each; (2) test the first end point against the desired global false-positive rate (ie, .05)
20/

Finally, many p value based tests😄...from frequentist view, could you share your comments ? @f2harrell @statsepi @stephensenn @venkmurthy @boback @raj_mehta @JeremySussman @ProfHayward @VPrasadMDMPH @ChristosArgyrop @ADAlthousePhD @dailyzad