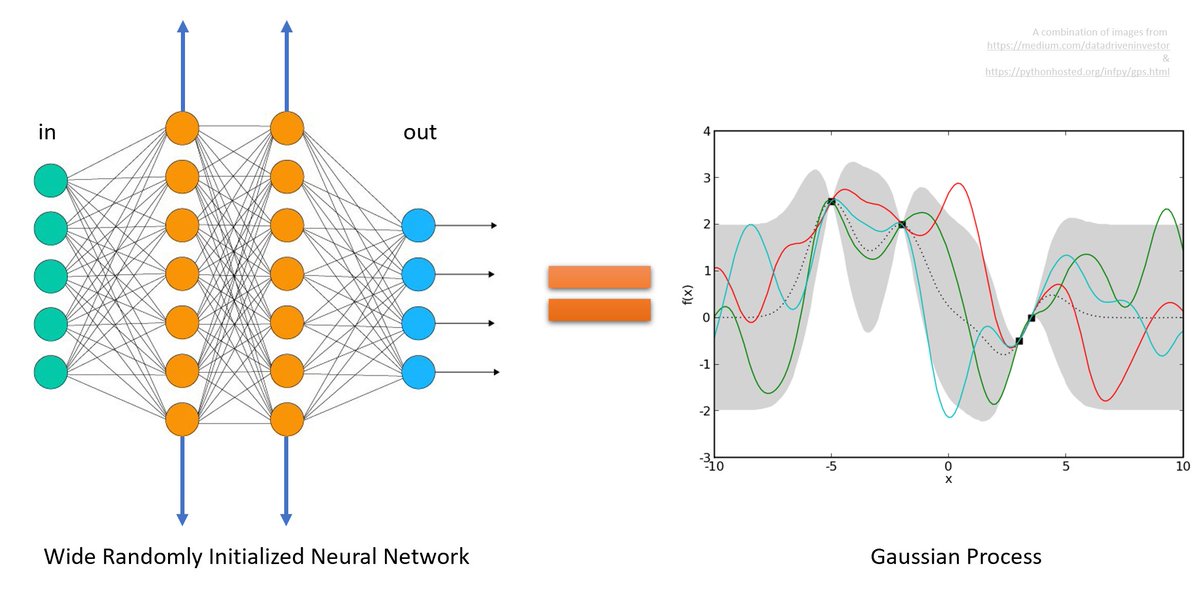
1/ Why do wide, random neural networks form Gaussian processes, *regardless of architecture*? Let me give an overview in case you are too lazy to check out the paper arxiv.org/abs/1910.12478 or the code github.com/thegregyang/GP…. The proof has two parts… 
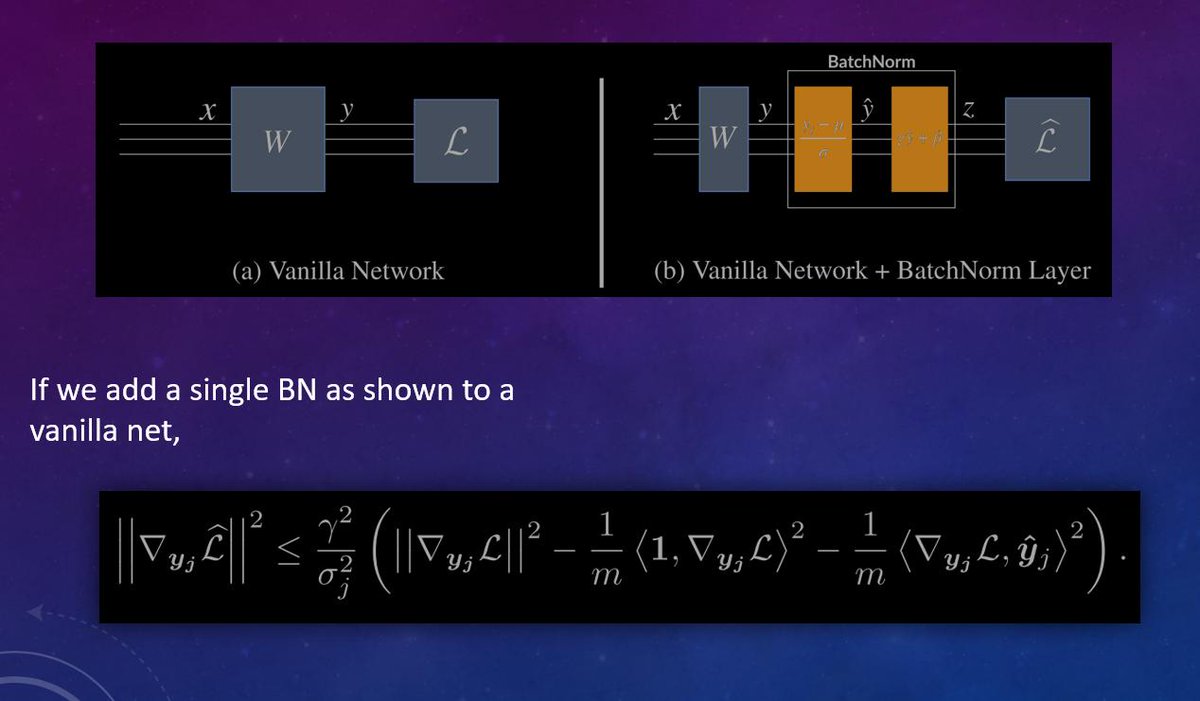
2/ Part 1 shows that any architecture can be expressed as a principled combination of matrix multiplication and nonlinearity application; such a combination is called a *tensor program*. The image shows an example. Thread 👉

3/ Part 2 shows that any such tensor program has a “mean field theory” or an “infinite width limit.” Using this, we can show that for any neural network, the kernel of last layer embeddings of inputs converges to a deterministic kernel. Thread 👉

4/ Finally, given the deterministic kernel limit, it’s easy to show that the output of the NN converges in distribution to a GP with that kernel.
5/ The NN-GP correspondence has a very long history, so let me also *briefly* summarize the prior works up to this point and give credits to the pioneers (see paper for full bibliography). It all started with Radford Neal in 1994...

6/ If you wanna know more, come check out my poster session next week at @NeurIPSConf, Wed Dec 11th 05:00 -- 07:00 PM @ East Exhibition Hall B + C #242 --- or come chat with me at @MSFTResearch Booth!
2.1/ A tensor program has 2 main types of variables, vector and matrix, and 2 main operations, matrix-vector multiplication and application of coordinatewise nonlinearities (in the paper we also add “linear combination” operation but that’s syntactic sugar).

2.2/ Claim: you can express pretty much any architecture in a tensor program, such that width = vector size; for example convolution is expressed as a bunch of matrix multiplications with shared matrices.

2.3/ This is a claim in the style of Church-Turing thesis: it can’t be formalized because we don’t know what architecture folks will come up with next, but it looks right for the architectures in existence so far. Ex: LSTM, GRU, Transformers, resnet, etc

3.1/ Thm: if the matrix variables of a tensor program are sampled as Gaussians, then the inner product between any two vector variables converges to a deterministic limit, as the dimensions (of the matrix and vector variables) tend to infinity.
3.2/ Intuition: if W is random Gaussian matrix, then (W u, W v) “should have” iid Gaussian coordinates for any vectors u, v: ((W u)_i, (W v)_i) should be jointly Gaussian with covariance <u, v> --- W "washes away" all but degree-2 covariance btw u & v
3.3/ Intuition: So any time a vector variable is created by matrix multiplication, it has roughly iid Gaussian coordinates, correlated with previous vector variables in a way that we can recursively compute.
3.4/ Intuition: If we apply nonlinearities to such “Gaussian” vector variables created by matrix multiplication to create a new vector, then this new vector has coordinates that are roughly iid images of Gaussians.
3.5/ These intuitions give way to a recursive relation that computes the covariance between all “Gaussian” vector variables.

3.6/ Finally, every vector variable should have “iid” coordinates that are either Gaussian or image of one, so the inner product btw any vectors should converge to some Gaussian expectation like E phi1(z1) phi2(z2), with (z1, z2) jointly Gaussian, ph1, phi2 nonlinearities
3.7/ This in particular applies when we express the forward computation of a neural network in a tensor program, so that vector variables represent preactivations and activations (and matrices are weights), proving Part 2
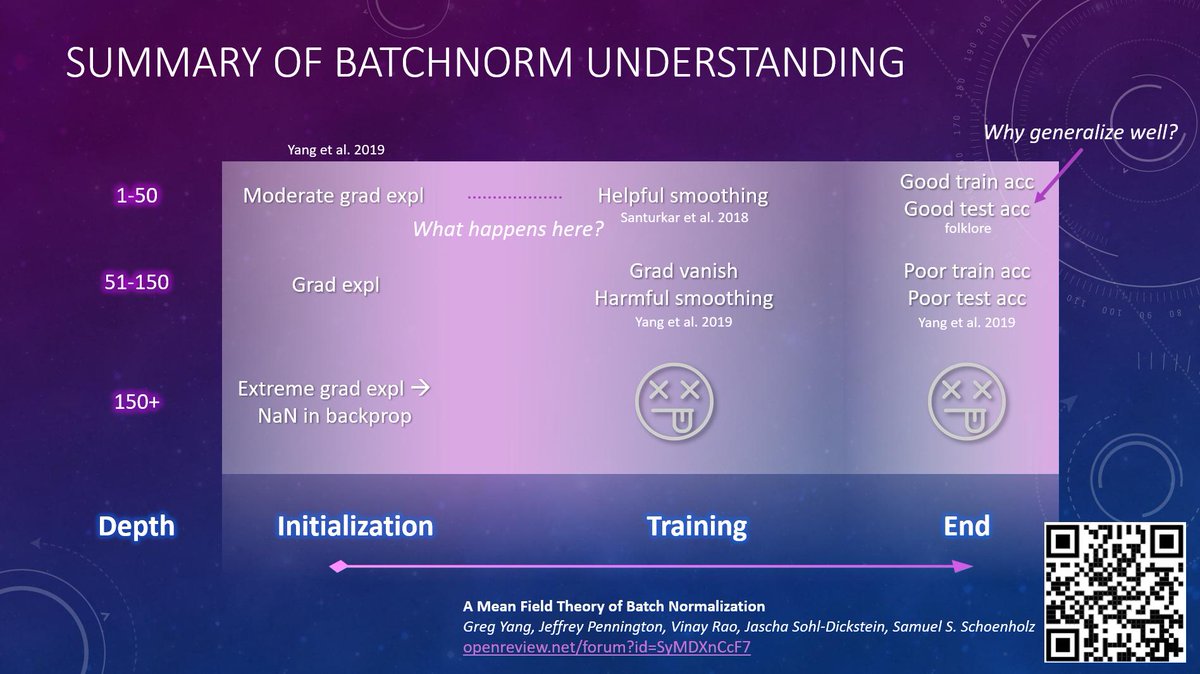
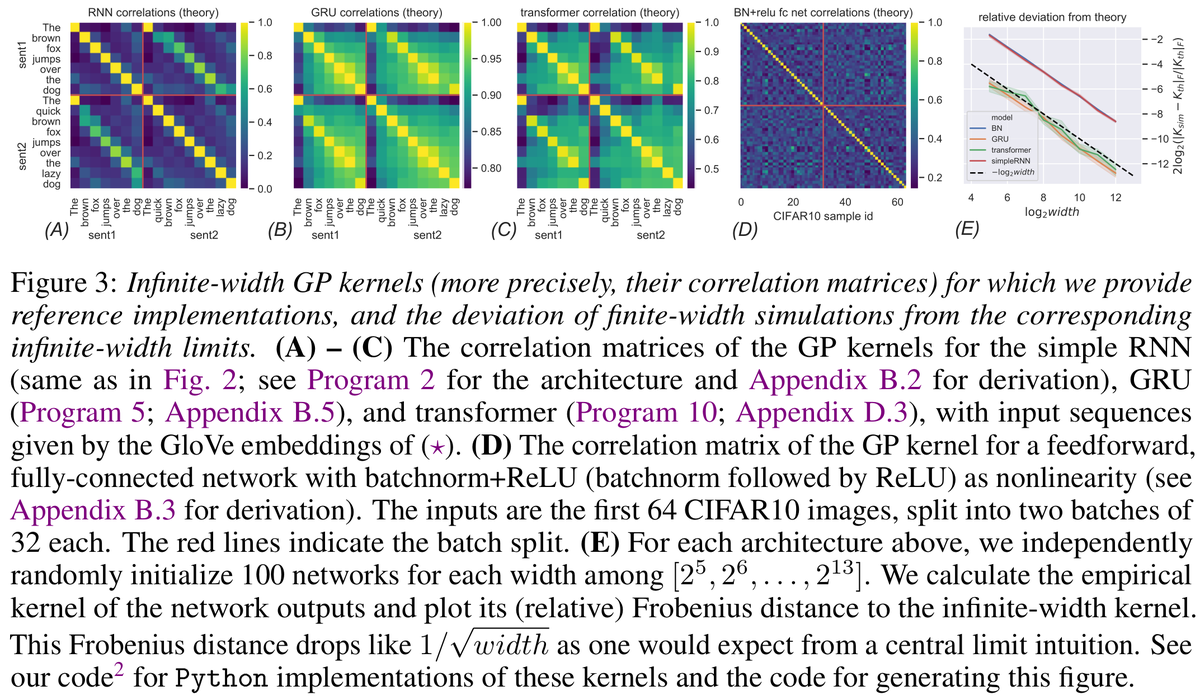
4.1/ github.com/thegregyang/GP… verifies the theory with simulation for the architectures of RNN, GRU, Transformers, and a Batchnorm+ReLU network. The deviation of empirical kernel from theoretical kernel drops like 1/sqrt(width), as one would expect
5.1/ …who famously showed a wide, randomly initialized 1-hidden layer NN is a GP: each hidden preactivation is an iid random var because the weights are iid, so the NN output is a sum of large number of iid random vars, so by Central Limit Thm it should b Gaussian. That's it!
5.2/ With a bit more math, you can generalize this argument to multiple layers, if you are fine with taking the (somewhat unnatural limit) limit as layer 1 width -> infty, then layer 2 width -> infty, and so on. This is the approach of Lee et al. 2018 arxiv.org/abs/1711.00165
5.3/ Concurrently, Matthews et al. arxiv.org/abs/1804.11271 proved the more natural limit when all widths tend to ∞ simultaneously. Their proof also inductively shows that the preactivations of each layer are GPs, like in the case of the sequential limit above. @alexggmatthews
5.4/ Matthews et al. relied on a Central Limit Thm for exchangeable sequences in order to avoid having to take the widths to infinity sequentially. Actually, 2 years before either paper, Daniely et al. arxiv.org/abs/1602.05897 already showed ...
5.5/ … the 2nd moments of the NN output distribution converges to the correct values --- with a bit more work, like in our proof, they could’ve proven the GP limit as well! Oh well.
5.6/ Novak et al. arxiv.org/abs/1810.05148 and Garriga-Alonso et al. arxiv.org/abs/1808.05587 further extended the NN-GP correspondence to convolutional networks in ICLR 2019. @AdriGarriga
5.7/ In all of these works above, however, it was important to use fresh randomness in each layer to make the GP argument. What if there’s weight sharing in different layers, like in an RNN? What about attention? What about batchnorm? Layernorm? …
5.8/ At the time it seemed like each new architecture required a paper completely devoted to it. Color me surprised when I found that any architecture can be expressed in a tensor program and one can prove such a GP limit once and for all!