,
9 tweets,
5 min read
Read on Twitter
1/ Does batchnorm make optimization landscape more smooth? arxiv.org/abs/1805.11604 says yes, but our new @iclr2019 paper arxiv.org/abs/1902.08129 shows BN causes grad explosion in randomly initialized deep BN net. Contradiction? We clarify below 
2/ During a visit by @aleks_madry's students @ShibaniSan @tsiprasd @andrew_ilyas to MSR Redmond few weeks ago, we figured out the apparent paradox.
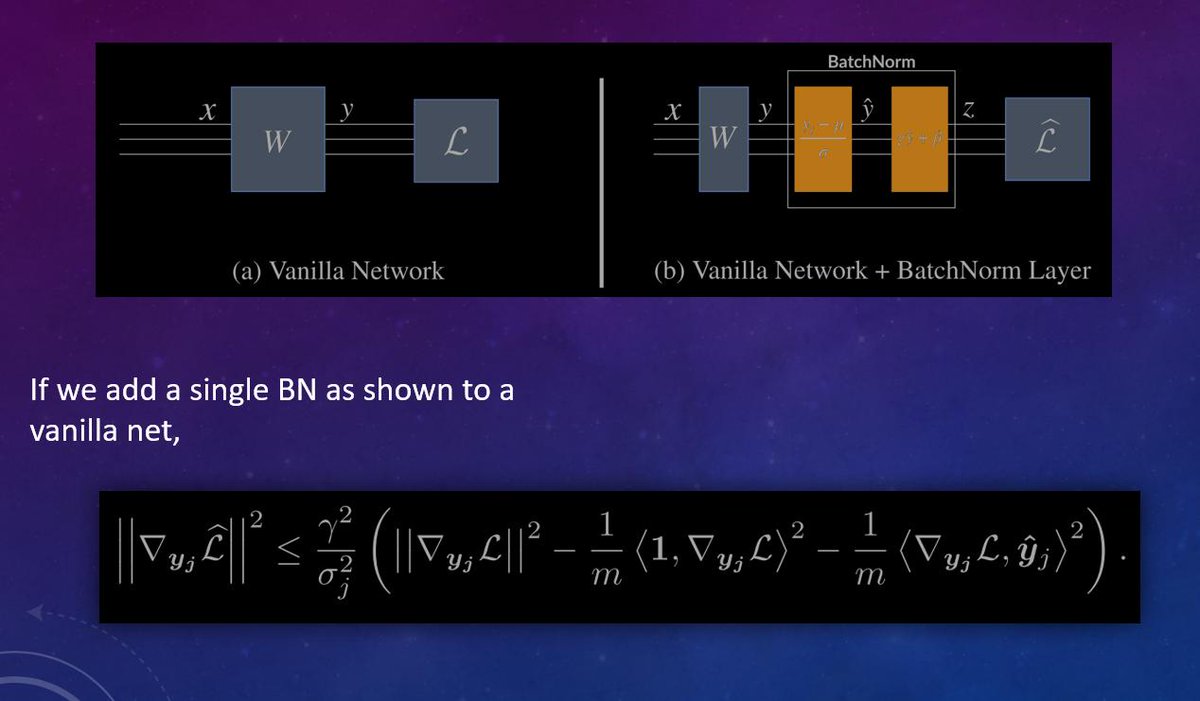
3/ The former shows grad wrt weight & preactivation *right before* BN is smaller than without BN, if the batch variance is large (which they empirically find to be true in training). But this result says nothing about gradients of lower layers, or stacking of BNs.
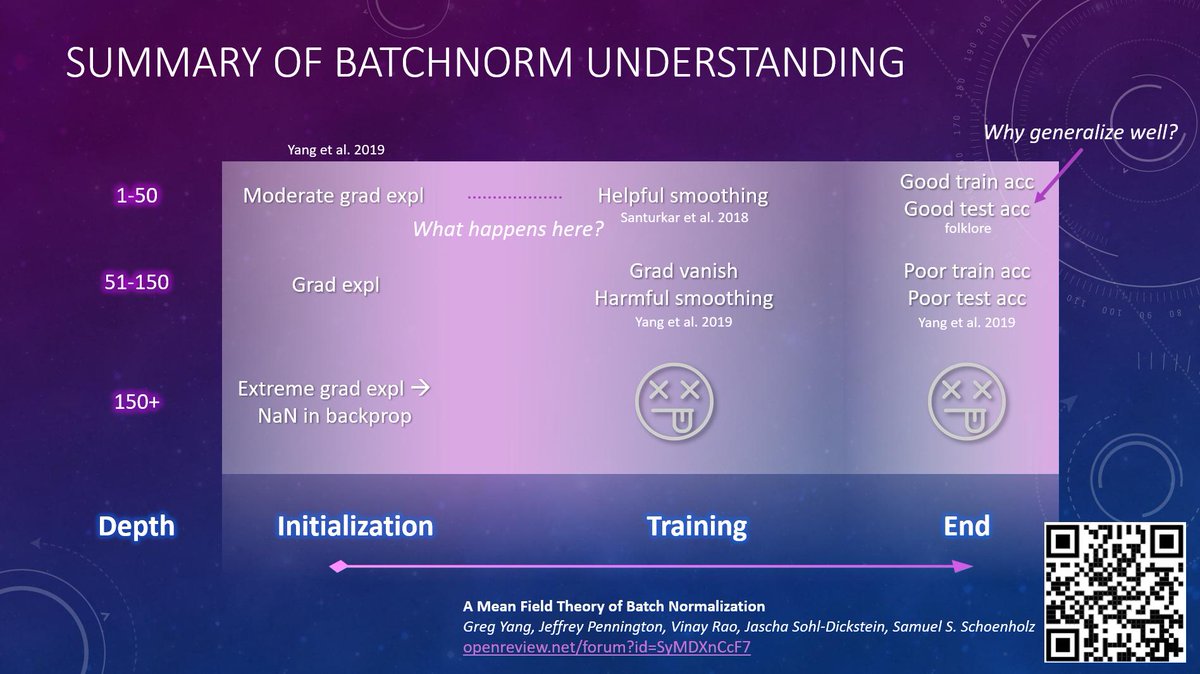
4/ The latter shows activation gradients exponentially explode in depth, *independent of batch variance*, for any nonlinearity. For 1-50 layers, no problem; for 50-150 layers, it causes optimization difficulty; for 150+, NaN during backprop, so training dies before 1 step.


5/ Indeed, in plots of optimization landscape in Santurkar et al., at initialization, the BN network is significantly less smooth than without BN.

6/ In fact, BN can cause exponential grad *vanishing* after 1 step --- extreme Lipschitzness --- because the exploding gradients dominate the weights during 1st SGD update, and due to the scaling property BN’(ax)=BN’(x)/a.

7/ For 50+ layers, this extreme Lipschitzness stalls optimization if NaNs don’t kill it already. Thus we say BN induces *harmful smoothing* here, while *helpful smoothing* with smaller depth (Santurkar et al.). Therefore we need to rethink how BN smoothness affects training.
8/ There is hence a difference in behavior between large and small depth BN networks. Still, how does grad explosion at init give way to helpful smoothing in training? Even more importantly, why is BN beneficial for generalization? Open questions!
9/ But why in the first place does batchnorm cause gradient explosion in randomly initialized networks? Somehow the math worked out perfectly, but we still don't have a simple, intuitive reason it should do so. If someone knows, please explain it to us!